≡

В предыдущей части мы разобрали основу, самые низы внутренностей системы управления git — blob'ы и коммиты. Пост не вызвал большого ажиотажа, а большинство вообще не стало его читать, но это была моя ошибка. Я плохо объяснил, что это не очередной из миллионов ман как создать git-репозиторий, от которых меня так же как и всех давно тошнит, а нечто немного более глубокое. Ну или просто мою кривую речь читать сложно. В общем, я все-таки решил написать вторую часть. Может в будущем кому-нибудь это пригодится и кто-нибудь скажет спасибо.
Во второй части, как и обещал, подробнее разберем ветвление и индекс, учитывая наши знания из первой части. Кто уже забыл чем закончилась первая серия, сделаю краткий пересказ. Git начинается с репозитория, репозиторий состоит из коммитов, которые связаны в дерево. Каждый коммит в свою очередь содержит ссылку на «рабочее дерево». Рабочее дерево — это дерево из blob'ов, которые представляют ваши файлы. Blob'ы являются неизменяемыми и при изменении файла создается новый blob. Главное, что мы должны были понять из первой части — не существует никаких бранчей, мержей и тегов, есть только коммиты, которые могут иметь несколько сыновей и несколько потомков. Бранч — всего-лишь ссылка на определенный коммит, как и тег. Ничего больше. При чекауте на бранч git просто перемещает ссылку HEAD на последний коммит в этом бранче. Так что заканчиваем мыслить бранчами и мержами, начинаем мыслить деревом коммитов. После этого такие операции как rebase становятся более понятными. А теперь начнем. Начнем как обычно с определений, некоторые из них уже вам известны.
<dt>tagname</dt>
<dd>То же самое, что бранч, с одним отличием: место, куда указывает tagname, никогда не меняется, в то время как branchname с новыми коммитами передвигается на последний.</dd>
<dt>HEAD</dt>
<dd>Коммит, на который сейчас сделан checkout. Если сделан checkout на branch, то передвигается с каждым новым коммитом, если checkout на commit — так и остается на нем, что является причиной оторванной головы (detached HEAD), о чем говорилось ранее.</dd>
<dt>c82a22c39cbc32...</dt>
<dd>Коммит всегда может быть получен по своему индивидуальному id, являющемуся 40-символьным SHA1.</dd>
<dt>c82a22c</dt>
<dd>Для простоты работы git позволяет использовать первые n символов, позволяющие точно идентифицировать id. Обычно хватает 4-8 символов. Как повезет.</dd>
<dt>name^</dt>
<dd>Символ ^ указывает, что нужно взять родителя этого коммита.</dd>
<dt>name^^ или name^2</dt>
<dd>Догадайтесь? Да, родитель родителя, соответственно. Количество символов ^ или число 2 может быть любым.</dd>
<dt>name~10</dt>
<dd>Ссылка на 10-го сына этого коммита. Часто используется при rebase.</dd>
<dt>name:path</dt>
<dd>Ссылка на определенный файл в рабочем дереве коммита. Например: HEAD^1:Makefile — ссылка на Makefile в предпоследнем коммите.</dd>
<dt>name^{tree}</dt>
<dd>Можно ссылаться не на коммит, а на рабочее дерево, которое он содержит.</dd>
<dt>name1..name2</dt>
<dd>Диапазон коммитов. Обычно используется для команд типа git log.</dd>
<dt>name1...name2</dt>
<dd>Три точки означают уже не диапазон, а ЛИБО name1, ЛИБО name2. Нужно редко, обычно для git diff.</dd>
<dt>master.. или ..master</dt>
<dd>То же самое, что master..HEAD и HEAD..master. Последнее пригождается при rebase.</dd>
<dt>--since="2 weeks ago" или --until="..."</dt>
<dd>Уже интереснее. Получает все коммиты за последние 2 недели (since), либо до них (until).</dd>
<dt>--grep=pattern</dt>
<dd>Выбор коммитов по регекспу. Придумывайте сами как ее использовать у себя.</dd>
<dt>--commiter=pattern или --author=pattern</dt>
<dd>Выбор коммитов с определенным автором или коммитером (странное слово, ну вы поняли).</dd>
<dt>--no-merges</dt>
<dd>Выбор коммитов, имеющих только одного родителя.</dd>Ух, надеюсь хоть кто-то с первого раза все прочитает. Теперь небольшой пример зачем, собственно, все это нужно:
$ git log --grep='foo' --author='johnw' --since="1 month ago" master..
Смысл этой команды можно понять, просто внимательно прочитав ее и все определения выше. Дам вам время подумать.
Одна из самых интересных команд для работы с деревом коммитов, невинно названная git rebase, используется обычно не часто, во-первых, потому что мало кто понимает ее суть, а во-вторых, и мало кто готов разбираться с ее сложностями просто для того, чтобы история коммитов «выглядела красивее» (например, я). Команда rebase позволяет оторвать коммит от родителя и прикрепить его к другому родителю. Рассмотрим пример (стрелочки указывают на родителей).
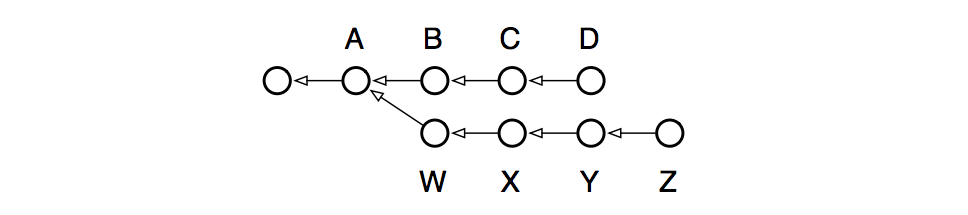
У нас есть 2 ветви с головами D и Z и одним общим родителем — А. Посмотрим командой:
$ git branch
Z
*D
$ git show-branch
! [Z] Z
* [D] D
--
* [D] D
* [D^] C
* [D~2] B
+ [Z] Z
+ [Z^]Y
+ [Z~2] X
+ [Z~3] W
+* [D~3] A
Тут стоит опять потратить немного времени и понять, что эти буковки, появившиеся в консольке, отображают ровно ту же картинку, что мы видели выше.
Что мы хотим сделать, так это внести изменения в ветке Z в ветку D. Например, кто-то поправил небольшой баг в отдельной ветке, совершенно не связанный с основным ходом разработки. Обычно в системах контроля версий мы бы сделали merge, создали бы такую «петельку» в разработке, но ведь она совершенно не нужна. Если у нас 100500 со-разработчиков, каждый правит какие-нибудь мелкие баги в своих ветках, то таких «петелек» становится куча. Нужно следить за тем, чтобы все правильно мержились, а если параллельно с этим идет активная разработка, то каждый merge опять нужно уследить. В общем, вечер глубокого петтинга с консолью вам гарантирован, если вы будете постоянно делать так:
$ git checkout Z # переключиться на ветвь Z
$ git merge D # мержим коммиты B, C и D в Z
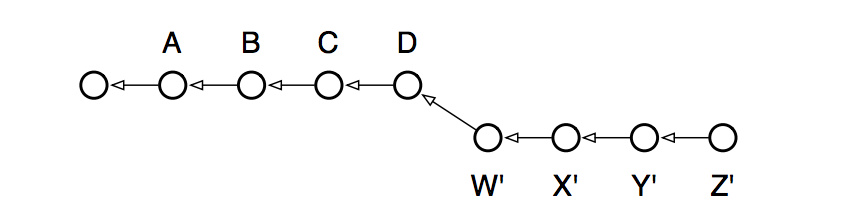
Вам понадобится разрешить все конфликты между D и Z, но в итоге мы получаем новый коммит Z' с тем, что хотели. Но этот коммит не представляет ничего нового, просто соединение D и Z. «Более лучший» путь внести изменения в D — просто пересадить ветку Z на кончик нашей. Ведь мы помним, что ветка - это всего-лишь коммиты, мы ничего не теряем. И так мы приходим к rebase.

$ git checkout Z # переключиться на ветвь Z
$ git rebase D # изменить место проростания ветви Z на коммит D
Мы можем дальше держать отдельну ветку для своих маленьких патчей и как только понадобится в любой момент rebase'ить ее на ветку разработки. Есть лишь одно требование — пересаживаемая ветвь должна быть локальной. Потому что rebase при пересадке Z с A на D изменяет все коммиты в ветке Z. А если у кого-то еще из разработчиков остались ссылки на старые коммиты в ветке Z — это могло бы привести к неприятным последствиям. Так что правило при использовании rebase такое: используйте rebase если у вас есть локальная ветвь, без ответвлений от нее самой, во всех остальных случаях — используйте merge.
В общем, я рекомендую прочитать маны по rebase, потому что кроме таких простых пересадок, он умеет и более сложные вещи по превращению вот такого:
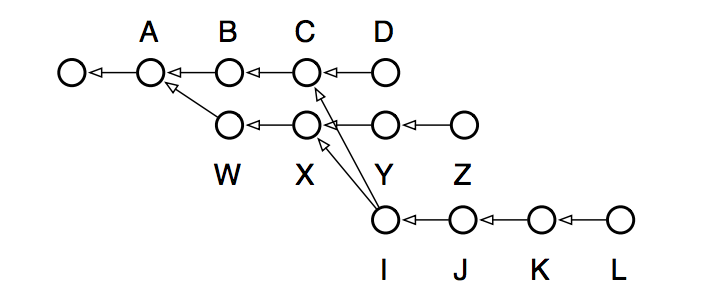
В вот такое:
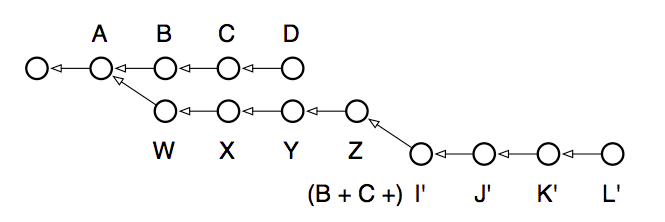
Хватит хардкора с rebase, вернемся к нашим blob'ам и поговорим об индексе. Тему индекса я затрагивал в предыдущей части, сейчас остановимся на нем поподробнее. Между вашими файлами и коммитами в git находится темная лошадка — индекс. Некоторые не понимают его работу, некоторые считают название «индекс» не очень правильным, но для полного понимания работы git игнорировать его нельзя. Индекс содержит blob'ы всех новых файлов, которые вы добавили командой add. Эти новые blob'ы ждут своего времени, когда их построят в деревья и сделают из них коммит, но до тех пор — это просто ссылки в индексе. А если вы отмените изменения командой reset, то все эти blob'ы станут не нужными (так же и называют orphaned — осиротевшими) и будут удалены когда-нибудь сборщиком мусора.
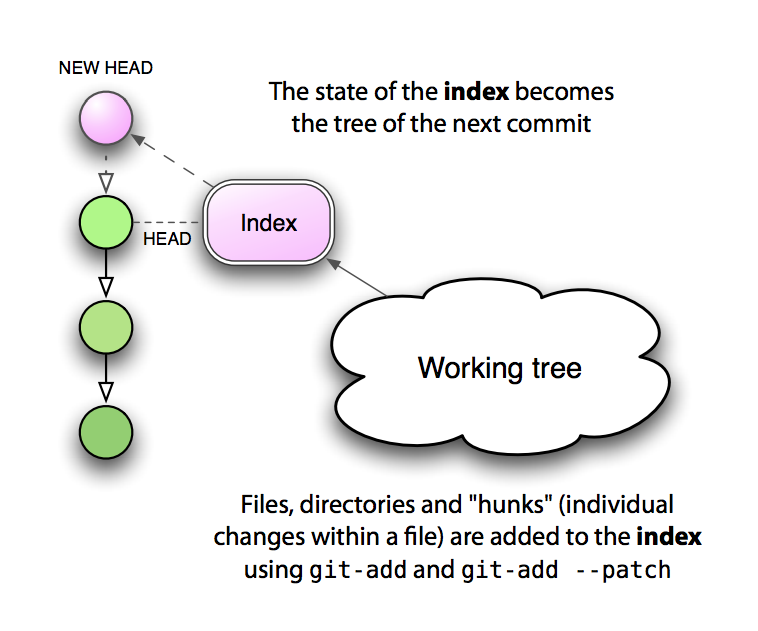
Команда git commit без дополнительных параметров добавляет в коммит только те файлы, которые вы добавили в индекс в ручную командой git add. Заметьте, что если файл изменен после git add, он не будет обновлен в индексе, нужно еще раз добавить его. Чтобы постоянно не делать эту операцию, у нас есть параметр -a у команды git commit. Коммит с этим параметром работает уже в два этапа: на первом этапе обновляется индекс, в него добавляются все изменения в проиндексированных файлах, а только затем создается коммит. Обратите внимание, что изменения просматриваются только в проиндексированных файлах, то есть ранее добавленных через git add, а вот удаленные файлы будут учтены.
Как это знание применить в работе, каждый решает сам для себя. Типичный пример — разделять изменения на несколько коммитов. Это для тех, кто придерживается принципа «один коммит — одно изменение» или просто для тех, кто забыл закоммититься (ну и является везунчиком, что не поменял те же файлы). Но вот вам пример более мудреного использования индекса в git.
Есть такая штука, как Quilt. Эта штука — хардкорный менеджер патчей, позволяющий, например, взять три патча A, B, C и протестировать их комбинации A + B, B + C, A + C. Или взять множество патчей и применить несколько из них. В общем, кому такой хардкор хоть раз пригождался (мне нет), наверняка уже знают про него. В git нет подобной системы. Если вы сделали коммит, нельзя его временно отключить и включить другой. Можно выпендриваться с временными ветвями и git cherry-pick, но ведь есть StackedGit, который позволяет проводить такие махинации напрямую в индексе. За более подробной информацией можно обратиться в документацию к stg, мое дело лишь рассказать, что с индексом git тоже можно интересно развлекаться, а не использовать его только как место сбора перед коммитом.
Вторая статья получилась менее интересной с теоретической точки зрения, чем первая, но быть может и она кому-нибудь придется по душе. В оригинальной книжке дальше остается еще пара глав про reset и stash, однако они показались мне еще более скучными, чем даже эта, так как уже не раскрывают особенностей git, а почти напрямую перепечатывают документацию. А документации в интернете навалом, практически каждую неделю выходят новые статьи по теме «начинаем работать с git или как создать свой первый репозиторий». Кстати, большинство людей и эти две статьи посчитало за такие же и просто не стало читать, я это понял потому что сразу несколько человек стало кидать мне «хорошие статьи» по их мнению, которые содержали именно основы git'а для чайников. Это не интересно, куда интереснее было бы почитать про структуры данных и сложные алгоритмы разрешения каких-нибудь коллизий, чем в очередной раз пролистывать простыню описаний «commit, push, pull, checkout».
Вот вам ссылка на оригинал (pdf), может быть кому-то пригодится: http://ftp.newartisans.com/pub/git.from.bottom.up.pdf
нунихерасебеяничонепонял
Здесь должен был быть холивар про merge и rebase, но я уже заебался слушать этот холивар на работе.
ReDetection, Посмотрел, книжка 2009 года. Видимо изменилось, спасибо за поправки
werehuman, ну надо просто различать то, что хочется сделать. я вот не понимаю необходимости операции последней черно-белой диаграммы. на мой взгляд, там и так все было хорошо, а после rebase в данном случае потерялась информация о том, что в I' есть В и С. rebase хорошая штука, часто использую, но, в основном, просто чтобы какую-нибудь ветку "подтянуть" над master'ом. кстати, интересно было бы доходчиво прочесть про интерактивный rebase. вроде и на хабре что-то было, но мне лень и хочу в картинках.
Спасибо Вася за книжку и перевод, помогло построить в голове полную картину всех этих процессов о которых знал частично
С помощью rebase удобно собирать коммиты в один, чтобы история не была слишком большой, а то разбираться трудно.
ak3n, покажи-научи?
ak3n, и будет у тебя один коммит с большими-пребольшими изменениями. И вдруг приспичит тебе bisect сделать...
ReDetection, <a href="http://feeding.cloud.geek.nz/2010/08/combining-multiple-commits-into-one.html">здесь</a> довольно наглядно написано. werehuman, ну, слишком больших-то нет, а вот группировать для для общей ветки надо.
Читнул русский перевод Pro Git. И сразу всё стало ясно и понятно, особенно в первом посте!
themylogin, видимой действительно не получилось донести. В следующий раз буду стараться больше.
Большая часть картинок почему-то из статьи про Apple, JS и видео :(
S, хах, офигеть, и правда. Что-то у меня с генератором имен файлов. Спасибо :)
Главная Блог Разработки Галерея Карта Продажа RSS #320 « Git снизу вверх. Часть 2 » 21 августа 2012 [18:32] Git снизу вверх. Часть 2 В предыдущей части мы разобрали основу, самые низы внутренностей системы управления git — blob'ы и коммиты. Пост не вызвал большого ажиотажа, а большинство вообще не стало его читать, но это была моя ошибка. Я плохо объяснил, что это не очередной из миллионов ман как создать git-репозиторий, от которых меня так же как и всех давно тошнит, а нечто немного более глубокое. Ну или просто мою кривую речь читать сложно. В общем, я все-таки решил написать вторую часть. Может в будущем кому-нибудь это пригодится и кто-нибудь скажет спасибо. Во второй части, как и обещал, подробнее разберем ветвление и индекс, учитывая наши знания из первой части. Кто уже забыл чем закончилась первая серия, сделаю краткий пересказ. Git начинается с репозитория, репозиторий состоит из коммитов, которые связаны в дерево. Каждый коммит в свою очередь содержит ссылку на «рабочее дерево». Рабочее дерево — это дерево из blob'ов, которые представляют ваши файлы. Blob'ы являются неизменяемыми и при изменении файла создается новый blob. Главное, что мы должны были понять из первой части — не существует никаких бранчей, мержей и тегов, есть только коммиты, которые могут иметь несколько сыновей и несколько потомков. Бранч — всего-лишь ссылка на определенный коммит, как и тег. Ничего больше. При чекауте на бранч git просто перемещает ссылку HEAD на последний коммит в этом бранче. Так что заканчиваем мыслить бранчами и мержами, начинаем мыслить деревом коммитов. После этого такие операции как rebase становятся более понятными. А теперь начнем. Начнем как обычно с определений, некоторые из них уже вам известны. branchname Как было сказано — ссылка на определенный коммит. Если сделан checkout на branchname, то поведение HEAD идентично branchname. Это одно и то же — просто ссылка. tagname То же самое, что бранч, с одним отличием: место, куда указывает tagname, никогда не меняется, в то время как branchname с новыми коммитами передвигается на последний. HEAD Коммит, на который сейчас сделан checkout. Если сделан checkout на branch, то передвигается с каждым новым коммитом, если checkout на commit — так и остается на нем, что является причиной оторванной головы (detached HEAD), о чем говорилось ранее. c82a22c39cbc32... Коммит всегда может быть получен по своему индивидуальному id, являющемуся 40-символьным SHA1. c82a22c Для простоты работы git позволяет использовать первые n символов, позволяющие точно идентифицировать id. Обычно хватает 4-8 символов. Как повезет. name^ Символ ^ указывает, что нужно взять родителя этого коммита. name^^ или name^2 Догадайтесь? Да, родитель родителя, соответственно. Количество символов ^ или число 2 может быть любым. name~10 Ссылка на 10-го сына этого коммита. Часто используется при rebase. name:path Ссылка на определенный файл в рабочем дереве коммита. Например: HEAD^1:Makefile — ссылка на Makefile в предпоследнем коммите. name^{tree} Можно ссылаться не на коммит, а на рабочее дерево, которое он содержит. name1..name2 Диапазон коммитов. Обычно используется для команд типа git log. name1...name2 Три точки означают уже не диапазон, а ЛИБО name1, ЛИБО name2. Нужно редко, обычно для git diff. master.. или ..master То же самое, что master..HEAD и HEAD..master. Последнее пригождается при rebase. --since="2 weeks ago" или --until="..." Уже интереснее. Получает все коммиты за последние 2 недели (since), либо до них (until). --grep=pattern Выбор коммитов по регекспу. Придумывайте сами как ее использовать у себя. --commiter=pattern или --author=pattern Выбор коммитов с определенным автором или коммитером (странное слово, ну вы поняли). --no-merges Выбор коммитов, имеющих только одного родителя. Ух, надеюсь хоть кто-то с первого раза все прочитает. Теперь небольшой пример зачем, собственно, все это нужно: $ git log --grep='foo' --author='johnw' --since="1 month ago" master.. Смысл этой команды можно понять, просто внимательно прочитав ее и все определения выше. Дам вам время подумать. Ветвление и пересадка (rebase) Одна из самых интересных команд для работы с деревом коммитов, невинно названная git rebase, используется обычно не часто, во-первых, потому что мало кто понимает ее суть, а во-вторых, и мало кто готов разбираться с ее сложностями просто для того, чтобы история коммитов «выглядела красивее» (например, я). Команда rebase позволяет оторвать коммит от родителя и прикрепить его к другому родителю. Рассмотрим пример (стрелочки указывают на родителей). У нас есть 2 ветви с головами D и Z и одним общим родителем — А. Посмотрим командой: $ git branch Z D $ git show-branch ! [Z] Z * [D] D -- * [D] D * [D^] C * [D~2] B + [Z] Z + [Z^]Y + [Z~2] X + [Z~3] W + [D~3] A Тут стоит опять потратить немного времени и понять, что эти буковки, появившиеся в консольке, отображают ровно ту же картинку, что мы видели выше. Что мы хотим сделать, так это внести изменения в ветке Z в ветку D. Например, кто-то поправил небольшой баг в отдельной ветке, совершенно не связанный с основным ходом разработки. Обычно в системах контроля версий мы бы сделали merge, создали бы такую «петельку» в разработке, но ведь она совершенно не нужна. Если у нас 100500 со-разработчиков, каждый правит какие-нибудь мелкие баги в своих ветках, то таких «петелек» становится куча. Нужно следить за тем, чтобы все правильно мержились, а если параллельно с этим идет активная разработка, то каждый merge опять нужно уследить. В общем, вечер глубокого петтинга с консолью вам гарантирован, если вы будете постоянно делать так: $ git checkout Z # переключиться на ветвь Z $ git merge D # мержим коммиты B, C и D в Z Вам понадобится разрешить все конфликты между D и Z, но в итоге мы получаем новый коммит Z' с тем, что хотели. Но этот коммит не представляет ничего нового, просто соединение D и Z. «Более лучший» путь внести изменения в D — просто пересадить ветку Z на кончик нашей. Ведь мы помним, что ветка - это всего-лишь коммиты, мы ничего не теряем. И так мы приходим к rebase. $ git checkout Z # переключиться на ветвь Z $ git rebase D # изменить место проростания ветви Z на коммит D Мы можем дальше держать отдельну ветку для своих маленьких патчей и как только понадобится в любой момент rebase'ить ее на ветку разработки. Есть лишь одно требование — пересаживаемая ветвь должна быть локальной. Потому что rebase при пересадке Z с A на D изменяет все коммиты в ветке Z. А если у кого-то еще из разработчиков остались ссылки на старые коммиты в ветке Z — это могло бы привести к неприятным последствиям. Так что правило при использовании rebase такое: используйте rebase если у вас есть локальная ветвь, без ответвлений от нее самой, во всех остальных случаях — используйте merge. В общем, я рекомендую прочитать маны по rebase, потому что кроме таких простых пересадок, он умеет и более сложные вещи по превращению вот такого: В вот такое: Индекс Хватит хардкора с rebase, вернемся к нашим blob'ам и поговорим об индексе. Тему индекса я затрагивал в предыдущей части, сейчас остановимся на нем поподробнее. Между вашими файлами и коммитами в git находится темная лошадка — индекс. Некоторые не понимают его работу, некоторые считают название «индекс» не очень правильным, но для полного понимания работы git игнорировать его нельзя. Индекс содержит blob'ы всех новых файлов, которые вы добавили командой add. Эти новые blob'ы ждут своего времени, когда их построят в деревья и сделают из них коммит, но до тех пор — это просто ссылки в индексе. А если вы отмените изменения командой reset, то все эти blob'ы станут не нужными (так же и называют orphaned — осиротевшими) и будут удалены когда-нибудь сборщиком мусора. Команда git commit без дополнительных параметров добавляет в коммит только те файлы, которые вы добавили в индекс в ручную командой git add. Заметьте, что если файл изменен после git add, он не будет обновлен в индексе, нужно еще раз добавить его. Чтобы постоянно не делать эту операцию, у нас есть параметр -a у команды git commit. Коммит с этим параметром работает уже в два этапа: на первом этапе обновляется индекс, в него добавляются все изменения в проиндексированных файлах, а только затем создается коммит. Обратите внимание, что изменения просматриваются только в проиндексированных файлах, то есть ранее добавленных через git add, а вот удаленные файлы будут учтены. Как это знание применить в работе, каждый решает сам для себя. Типичный пример — разделять изменения на несколько коммитов. Это для тех, кто придерживается принципа «один коммит — одно изменение» или просто для тех, кто забыл закоммититься (ну и является везунчиком, что не поменял те же файлы). Но вот вам пример более мудреного использования индекса в git. Есть такая штука, как Quilt. Эта штука — хардкорный менеджер патчей, позволяющий, например, взять три патча A, B, C и протестировать их комбинации A + B, B + C, A + C. Или взять множество патчей и применить несколько из них. В общем, кому такой хардкор хоть раз пригождался (мне нет), наверняка уже знают про него. В git нет подобной системы. Если вы сделали коммит, нельзя его временно отключить и включить другой. Можно выпендриваться с временными ветвями и git cherry-pick, но ведь есть StackedGit, который позволяет проводить такие махинации напрямую в индексе. За более подробной информацией можно обратиться в документацию к stg, мое дело лишь рассказать, что с индексом git тоже можно интересно развлекаться, а не использовать его только как место сбора перед коммитом. Заключение Вторая статья получилась менее интересной с теоретической точки зрения, чем первая, но быть может и она кому-нибудь придется по душе. В оригинальной книжке дальше остается еще пара глав про reset и stash, однако они показались мне еще более скучными, чем даже эта, так как уже не раскрывают особенностей git, а почти напрямую перепечатывают документацию. А документации в интернете навалом, практически каждую неделю выходят новые статьи по теме «начинаем работать с git или как создать свой первый репозиторий». Кстати, большинство людей и эти две статьи посчитало за такие же и просто не стало читать, я это понял потому что сразу несколько человек стало кидать мне «хорошие статьи» по их мнению, которые содержали именно основы git'а для чайников. Это не интересно, куда интереснее было бы почитать про структуры данных и сложные алгоритмы разрешения каких-нибудь коллизий, чем в очередной раз пролистывать простыню описаний «commit, push, pull, checkout». Вот вам ссылка на оригинал (pdf), может быть кому-то пригодится: http://ftp.newartisans.com/pub/git.from.bottom.up.pdf tags Категории: Кодинг com Комментариев: 15 _ — 21 августа 2012 [18:54] [IP: 89.189.191.19] Windows # нунихерасебеяничонепонял ReDetection — 21 августа 2012 [20:34] [IP: 89.189.191.13] Linux # > name^ > Символ ^ указывает, что нужно взять родителя этого коммита. > name^^ или name^2 > Догадайтесь? Да, родитель родителя, соответственно. Количество символов ^ или число 2 может быть любым. > name~10 > Ссылка на 10-го сына этого коммита. Часто используется при rebase. э-не-не-не! name^ и name~1 - одно и то же, родители. name^2 вообще нельзя. у тебя что за особенная версия git'а? werehuman — 21 августа 2012 [21:38] [IP: 178.49.21.200] Linux # Здесь должен был быть холивар про merge и rebase, но я уже заебался слушать этот холивар на работе. V@s3K — 21 августа 2012 [21:44] [IP: 195.208.147.206] Mac OS # ReDetection, Посмотрел, книжка 2009 года. Видимо изменилось, спасибо за поправки ReDetection — 21 августа 2012 [22:21] [IP: 89.189.191.13] Linux # werehuman, ну надо просто различать то, что хочется сделать. я вот не понимаю необходимости операции последней черно-белой диаграммы. на мой взгляд, там и так все было хорошо, а после rebase в данном случае потерялась информация о том, что в I' есть В и С. rebase хорошая штука, часто использую, но, в основном, просто чтобы какую-нибудь ветку "подтянуть" над master'ом. кстати, интересно было бы доходчиво прочесть про интерактивный rebase. вроде и на хабре что-то было, но мне лень и хочу в картинках. Vass — 21 августа 2012 [22:43] [IP: 46.237.31.234] Linux # Спасибо Вася за книжку и перевод, помогло построить в голове полную картину всех этих процессов о которых знал частично ak3n — 22 августа 2012 [21:23] [IP: 85.12.194.233] Linux # С помощью rebase удобно собирать коммиты в один, чтобы история не была слишком большой, а то разбираться трудно. ReDetection — 24 августа 2012 [00:28] [IP: 89.189.191.13] Linux # ak3n, покажи-научи? werehuman — 24 августа 2012 [02:38] [IP: 37.194.18.113] Linux # ak3n, и будет у тебя один коммит с большими-пребольшими изменениями. И вдруг приспичит тебе bisect сделать... ak3n — 24 августа 2012 [09:44] [IP: 85.12.194.233] Linux # ReDetection, здесь довольно наглядно написано. werehuman, ну, слишком больших-то нет, а вот группировать для для общей ветки надо. themylogin — 03 сентября 2012 [02:11] [IP: 178.49.94.51] Linux # Читнул русский перевод Pro Git. И сразу всё стало ясно и понятно, особенно в первом посте! V@s3K — 03 сентября 2012 [10:09] [IP: 178.49.15.6] Mac OS # themylogin, видимой действительно не получилось донести. В следующий раз буду стараться больше. S — 15 января 2013 [03:04] [IP: 37.193.243.56] Windows # Большая часть картинок почему-то из статьи про Apple, JS и видео :( V@s3K — 15 января 2013 [15:04] [IP: 178.49.15.6] Mac OS # S, хах, офигеть, и правда. Что-то у меня с генератором имен файлов. Спасибо :) Автор: Вы - бот? (не заполняйте это поле) i comm Комментарии PPPPPPPPPP » Устройства-паразиты V@s3K » Git снизу вверх. Часть 2 S » Git снизу вверх. Часть 2 .... » Так вот куда все деньги уходят Un1oR » Так вот куда все деньги уходят ajin.org » Gismeteo для GeekTool V@s3K » Так вот куда все деньги уходят streetmack » Так вот куда все деньги уходят MadAdmin » Так вот куда все деньги уходят themylogin » Так вот куда все деньги уходят new Свежее Блог Так вот куда все деньги уходят Устройства-паразиты Итоги года 2012 Галерея Красный Проспект, 17 Cold and abandoned #2 Cold and abandoned Распродажа Ботильоны с пиками (39 размер) [2000,0 руб.] Корм и подстилка для хомяка [Отдам за пироженку] Старый ТВ-тюнер AverMedia [Отдам за пиво] blog BlogRoll lj Жена @ themylogin A Alive recommmend Рекомендую apple iWantGadget V@s3K's Project 2008—2013
А ещё у тебя merge и rebase перепутались.
+1 про перепутались: в разделе Ветвление и пересадка (rebase) вторая и третья иллюстрации перепутаны, из-за чего наводят путаницу, если не знать заранее, о чём речь