≡
upd: У поста есть продолжение: https://vas3k.blog/blog/358/
Обычно мне не удаются длинные циклы статей по какой-то теме, однако писать про поиск и NLP оказалось интереснее обычного. Во-первых я сам структурирую собранные по крупицам собственные знания, во-вторых делюсь ими и возможно мотивирую нескольких читателей, которым это интересно, а в-третьих, заполняю информационный вакуум в данной теме в рунете.
Мне кажется, что многие не обратили должного внимания на отличную картинку, с которой начинался предыдущий пост, а ведь она действительно стоит того, чтобы немного её порассматривать. Если присмотреться в левый верхний угол, на оранжевую дорожку «Text Mining», можно примерно понять, какие разделы уже покрыты. Не все из них являются интересными для обсуждения, но есть одна, о которой хотелось бы рассказать поподробнее — Named Entity Recognition, по-русски — Извлечение Именованных Сущностей, или в более широком смысле — Извлечение Фактов, когда между именованными сущностями анализируются взаимосвязи.
Выделение именованных сущностей — одна из ключевых задач систем автоматической обработки текста. В заглавии поста приведена примерная иллюстрация того, что нас ждет. Именованные сущности — это объекты определенного типа, чаще всего составные, например, названия, имена людей, даты, места, денежные единицы и.т.д. В общем смысле это все те объекты, которые можно вытащить из текста.
Полезность умения вытащить именованные сущности из текста, думаю, очевидна большинству читателей. В Яндекс.Новостях, например, таким образом строятся аннотации к новостям, добавляются ссылки на «пресс-портреты» и карта. Очень популярно применение в системах, используемых маркетологами для анализа отзывов о товаре и упоминания бренда в сети.
 Яндекс.Новости делают аннотации с фотографиями и картой именно благодаря Томите
Яндекс.Новости делают аннотации с фотографиями и картой именно благодаря Томите
Моя магистерская работа посвящена семантическому поиску, в котором система разбора и понимания запроса является основным направлением разработки. По идее она должна понимать запросы типа «Итальянские рестораны в центре Новосибирска со средним чеком менее 1000 руб, в которые ходили мои друзья за последний месяц», для чего мне просто необходимо уметь извлекать объекты «итальянский ресторан», «центр Новосибирска», «средний чек», «мои друзья» и «последний месяц» — то есть практически каждое слово в запросе является интересующей меня сущностью. Подробнее о том, как я это делаю, возможно будет описано в следующих статьях, но суть вполне ясна.
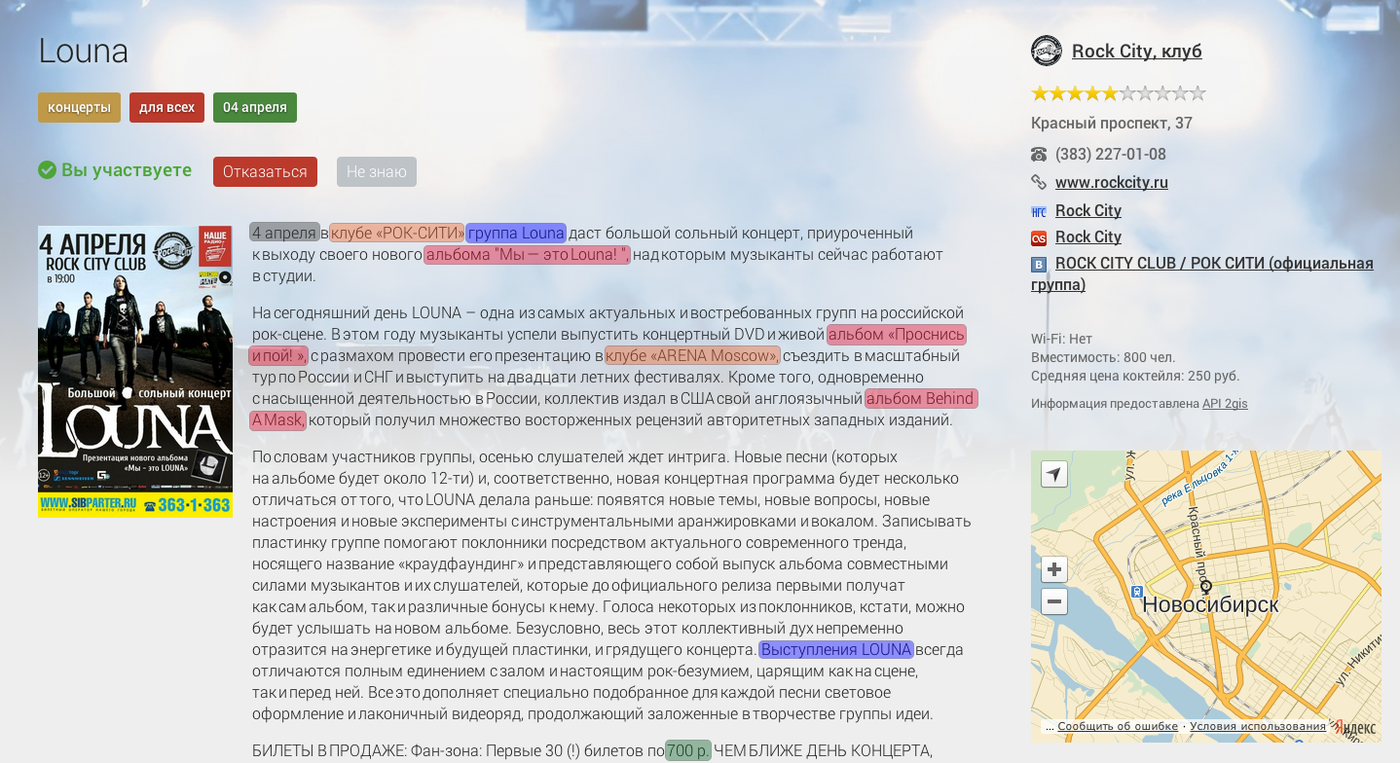
По доброй традиции в данном посте нашим подопытным кроликом для извлечения названий будут события из Futurise. Конкретным примером был случайно выбран концерт группы Louna в Новосибирске 4 апреля 2014. Хотя кого я обманываю, Louna — единственная рок-группа, на чьи концерты я хожу, но мы ведь не собираемся обсуждать сейчас мой ужасный музыкальный вкус? :)
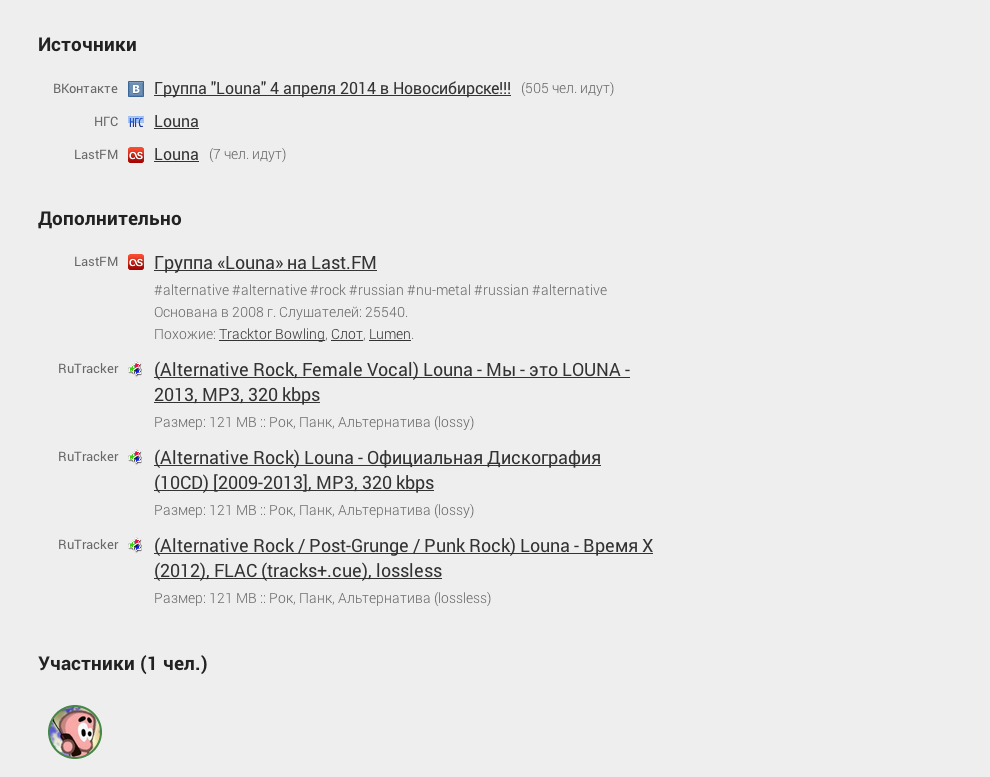
Кто читал первую статью помнит, что под каждым событием в Futurise есть вот такие ссылочки на источники данных, из которых событие и сформировалось:
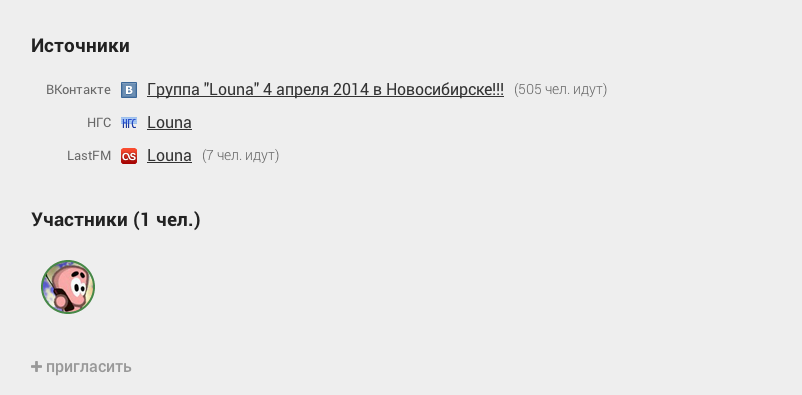
Простейшим примером улучшения аннотации после выделения именованных сущностей являются дополнительные полезные ссылки. Первой же идеей, пришедшей в голову, были ссылки на last.fm и скачивание дискографии с торрентов, однако возможности легко расширяются и зависят только от воображения:
Какие идеи сразу возникают, если стоит такая задача? Наверное, первое, что приходит в голову — регулярные выражения или что-то подобное. С многообразием словоформ поможет морфологический анализ, читавшие предыдущую часть помнят, что это не сложно. Ну и дальше пишется регулярка типа «слово "клуб", за которым идет одно или несколько слов — название, возможно в кавычках». Уже сейчас понятно, что такая регулярка получается, во-первых, очень сложной, во-вторых, любое отклонение во входных данных грозит провалом. В первой части я рассказывал, что, в отличие от тех же Яндекс.Новостей, в Futurise мы имеем дело с «ну очень естественным языком» — текстами лучших SMM-профессионалов города с орфографией и пунктуацией на уровне третьеклассника и очень своеобразной стилистикой.
В регулярном выражении придется учитывать огромное множество особенностей «ну очень естественного языка» — авторы забывают закрывать кавычки, ставить знаки препинания, иногда даже пробелы считаются излишними. Не учли какую-то особенность - ничего не найдется или, того хуже, регулярка вернет половину текста в качестве «сущности». Возможно, настоящие профессионалы регулярных выражений (коим я не являюсь) смогут написать даже более-менее работающую регулярку, однако я уже представляю себе ее размер и читабельность.
Но это не значит, что регулярные выражения совершенно бесполезны. Место, где они настоящие короли бала — это даты, денежные единицы и всё остальное, что связано с цифрами. Объекты «4 апреля», «04.04.14» или «700 р» во всех системах извлечения сущностей разбираются именно регулярными выражениями. Такую регулярку, даже учитывающую все комбинации, может написать любой уважающий себя разработчик.
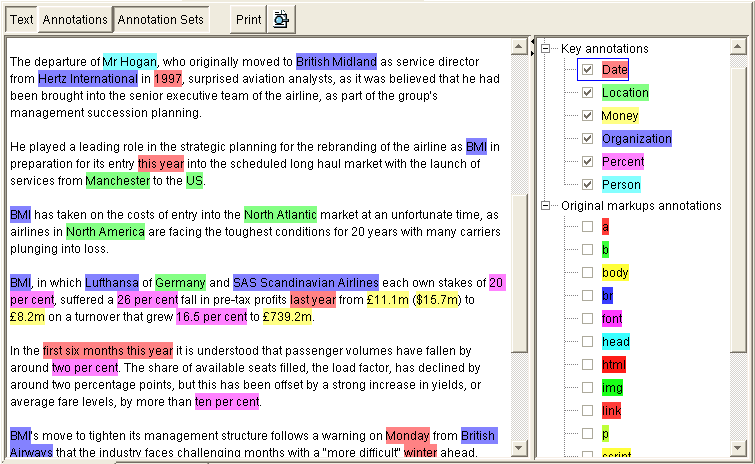 Пример системы извлечения именованных сущностей (к Томите пока не имеющей отношения)
Пример системы извлечения именованных сущностей (к Томите пока не имеющей отношения)
С датами и ценниками разобрались, но вопрос о том, как определять названия клубов или групп остается открытым. Здесь нам должна прийти в голову вторая идея: а что, если составить список всех клубов города? Для Новосибирска это пара сотен, не так уж и много, в Москве/Питере эта цифра раз в 10 больше, но всё равно не смертельна. Нормализуем, кладем в хеш-таблицу и затем ищем да тем же перебором. Или индексируем конечным автоматом и ищем по префиксам и с опечатками. Но эта методика сложная, так индексирует данные тот же 2ГИС, когда для всего словаря строится граф какая буква может идти после какой, не буду пока углубляться.
Подход многообещающий и 100% поможет нам с названиями клубов, исключив ложные срабатывания и дав максимальную точность. Особенно хорошо работает для имен известных личностей и названий известных компаний, ведь самый популярный источник таких данных — Википедия - еще частенько дает нам возможные варианты написания этих названий. Небольшая проблема может возникнуть с обновлением (например, появление нового клуба в городе), но тут нужно решать индивидуально. Кстати, такой подход называется «по словарю» или «по онтологии» (такие словари, где между терминами расставлены еще и связи).
Однако, решительно непонятно, как быть с названиями тех же музыкальных групп. Если клубы можно напарсить из открытых источников, того же Foursquare, то выгрузить все музыкальные группы в мире из last.fm, а потом еще и пытаться перебирать их, кажется нереализуемой для простого смертного задачей. Перебирать каждое слово из текста в last.fm так же займет кучу времении, повысит риск, что last.fm просто забанит вас, а так же даст кучу ложных срабатываний.
Встает проблема, что нам просто необходимо уметь хотя бы примерно определять, что какое-то словосочетание может являться названием группы. Чтобы потом полезть на тот же last.fm или в БД и проверить. Сделать это можно, например, по имеющимся где-то рядом в предложении словам «группа», «выступает», «на сцене», и.т.д. Запомним эту идею.
Третим подходом в литературе обычно выделяют «машинное обучение». По моему скромному мнению, когда лингвисты не могут придумать как решить определенную задачу, они всегда садятся в кресло, зажигают трубку, и говорят: «Нужно машинное обучение». То есть как бы сливаюся. Машинное обучение - это весело и интересно, но оно не является серебряной пулей, а скорее наоборот. Ведь главный минус машинного обучения в том, что, стоит вам выбрать немного не те или ошибиться с выбором критериев, по которым машину обучать, так всё идет, простите, по хуям. И понять, почему всё идет по хуям, чаще всего сложно или невозможно, нужно выбирать другие критерии и бегать с бубном.
Вернемся и взглянем на то, что у нас уже есть. Нужно как-то иметь находить слова «группа», «в клубе», «выступает» и названия рядом с ними. Не буду томить, это типичный алгоритм синтаксического LR-анализатора, который проходят в университете на курсе «языки программирования». На самом деле это даже GLR-парсер, который, возможно, и не проходят.
Для тех, кто прогуливал лекции или забыл, небольшое введение, так сказать «на пальцах». Кто помнит, может пропустить. Синтаксический анализатор состоит из записанной определенным образом формальной грамматики, состоящей из терминальных и нетерминальных символов.
Нетерминальный символ — объект, непосредственно присутствующий в тексте или исходном коде и имеющий конкретное, неизменяемое значение. В простых текстах это просто слово (Россия) или устойчивое словосочетание (Российская Федерация), в исходном коде это все единицы кода — названия переменных, классов, операторы, скобочки, и.т.д.
Терминальный символ — объект, обозначающий какую-либо сущность языка. Опять же в простых текстах это может быть «страна» или «название группы», в коде это «функция», «блок if», и.т.д.
LR-анализатор работает следующим образом: есть грамматика, входная строка и стек. Например дана грамматика, разбирающая последовательности типа a+a+a...
S -> F
F -> a
F -> F+FИ входная цепочка:
a+aНачальное состояние:
+--
| a+a
+--действие - сдвиг.
+--
|a +a
+--действие - свертка по правилу F -> a
+--
|F +a
+--действие - сдвиг.
+---
|F+ a
+---действие - сдвиг.
+---
|F+a
+---действие - свертка по правилу F -> a
+----
|F+F
+----действие -- свертка по правилу F -> F+F
+--
|F
+--действие -- свертка по правилу S -> F
+--
|S
+--конечное состояние успешного LR-процесса. Пример взят отсюда и упрощен.
Это условное описание работы любого LR-анализатора, остальное - всякие LR(1), LALR(1) — детали реализации.
Теперь можно представить, что вместо «a» и «+» у нас слова «клуб» и его название. Идеально подходит для нас. Вот только где взять такой парсер? Для английского языка подобных парсеров очень много, даже в самый популярный пакет NLTK входит такой. А для русского? Ответ в заголовке — Томита-парсер, который Яндекс в конце 2012 года открыл для всех желающих в виде бинарника.
Томита-парсер – это инструмент для извлечения структурированных данных (фактов) из текста на естественном языке. Извлечение фактов происходит при помощи контекстно-свободных грамматик и словарей ключевых слов. Парсер позволяет написать свою грамматику, добавить свои словари и запустить на текстах.
В основе лежит лежит алгоритм GLR-парсинга Масару Томиты. Грамматика для Томита-парсера выглядит как-то так:
#encoding "utf-8"
#GRAMMAR_ROOT S
S -> Adj Noun; Данная грамматика очень проста и вернет нам все пары прилагательных (Adj) и существительных (Noun), согласованные по числу и падежу (nc-agr). В грамматике Adj и Noun являются терминальными символами, всё, что записано в <угловых скобочках> — так называемые пометы.
Кажется, штука неплохая. Яндекс недавно громко рассказывал как они используют его в новой Яндекс.Почте. Чтобы воспользоваться нужно проделать несколько шагов.
Разберемся на уже привычном примере: названия групп и альбомов. Написание правил для Томита-парсера начинается с главного конфига — config.proto. Да, конфиги пишутся, внезапно, на языке Google Protobuf.
encoding "utf8";
TTextMinerConfig {
Dictionary = "dict.gzt";
PrettyOutput = "output.html";
NumThreads = 3;
Input = {
File = "text.txt";
}
Output = {
Format = xml;
}
Articles = [
{ Name = "группы" }
]
Facts = [
{ Name = "Group" },
{ Name = "Album" }
]
}dict.gzt — словарь, PrettyOutput — полезная информация для дебага, NumThreads — количество потоков парсера, Input/Output — настройки ввода вывода, читать из файла text.txt, писать в STDOUT в формате XML. Articles — используемые статьи из словаря dict.gzt, Facts — те факты, которые мы хотим извлечь.
dict.gzt выглядит так
encoding "utf8";
import "base.proto";
import "articles_base.proto";
import "facttypes.proto";
TAuxDicArticle "слово_группа"
{
key = "группа"
key = "ансамбль"
key = "коллектив"
}
TAuxDicArticle "группы"
{
key = { "tomita:group.cxx" type=CUSTOM }
}Мы описали «мультиворд» — «слово_группа», в котором скрываются все слова, которые могут стоять перед названием группы, а так же добавили ссылку на group.cxx — файл грамматики. facttypes.proto — это описание фактов, которые мы будем извлекать, а всё остальное — служебная информация, жестко закрытая в бинарнике Томита-парсера; Яндекс говорит ее просто нужно импортировать всегда.
facttypes.proto выглядит так
import "base.proto";
import "facttypes_base.proto";
message Group: NFactType.TFact
{
required string Name = 1;
}
message Album: NFactType.TFact
{
required string Name = 1;
}Мы описали два факта, которые будем извлекать — это название группы и альбом. Наши факты состоят только из полей Name, однако, в зависимости от извлекаемой информации, они могут состоять из множества полей, причем некоторые могут быть optional.
Ну и самое интересное — group.cxx, описание грамматики.
#encoding "utf-8"
#GRAMMAR_ROOT S
AlbumName -> 'альбом' AnyWord AnyWord<~r-quoted>* AnyWord;
GroupName -> Word Word+;
S -> GroupName interp(Group.Name::not_norm);
S -> AlbumName interp(Album.Name::not_norm); AlbumName — состоит из слова «альбом» в любой его форме (томита поймет «альбому», «альбомы», и.т.д., так как делает нормализацию) и следующих за ним любых последовательностей символов AnyWord с открывающей кавычкой l-quoted и с большой буквы h-reg1 и любого количества слов до закрывающей кавычки (для простоты я опустит условие, что она может отсутствовать).
GroupName — состоит из слов словаря «группа», «ансамбль», и.т.д. и следующих за ним слов с большой буквы, согласованных по числу и падежу (хотя это не обязательно).
Всё, что найдет парсер, извлечется в факты благодаря конструкции interp(Group.Name::not_norm), где ::not_norm указывает, что нужно сохранять слова в таком виде, в котором они встретились в тексте.
Действительно, эта грамматика написана мной на коленке во время изучения возможностей Томита-парсера и пока не применяется, и в таком виде точно не будет применяться в Futurise. Слишком она детская и дает много ложных срабатываний, над ней нужно еще посидеть, подумать, поэкспериментировать, но это процесс творческий.
В документации Томита-парсера есть несколько примеров, а так же описаны основные структуры парсера. Мельком упомянуты алгоритмы автоматического извлечения ФИО, дат и денежных единиц, написанные на С, однако очень скудно. Могу сделать предположение, что Яндекс все еще скрывает достаточно большую часть функциональности Томита-парсера, выложив то, что мы видим сейчас, исключительно чтобы такие как я «поигрались».
Открытие исходников, понятно, скорее из разряда фантастики, однако распространение исключительно в виде бинарника, который нужно на каждый текст запускать — это палка в колеса всем, кто захочет использовать его для чего-то серьезного. Оверхед от таких перезапусков громадный, инициализация занимает почти секунду, что не позволит использовать его так же быстро, как это делает Яндекс у себя. Засранцы, короче :)
Но у меня для вас есть небольшой бонус. Так как я всё же планирую попытаться его использовать, я написал однофайловую обертку, которая позволяет запускать и получать данные из него на Python. Там же есть и пример, приведенный в статье.
Используйте на свой страх и риск, но велкам.


Спасибо, интересно.
Это все круто. Но когда будет нормальный дизайн?
артур, нормального дизайна не существует. Любой дизайн — говно, я гарантирую.
А откуда взят пример извлечения сущностей на англ. языке?
Уже нашел, это Gate На сайте пишут, что он может процессить русский язык. Вы уже пробовали? Как результаты?
Это всё очень круто. Всегда хотел хотя бы что-то понимать в программировании. Да только хер пойми с чего начинать.
ikud, только сейчас узнал, что Gate умеет русский, потому даже не рассматривал его. Ну и еще думал, что это больше графическая среда, чем библиотека. Вообще рассматривал все, что есть здесь: http://nlpub.ru/Обработка_текста Но основная причина отказа от большинства библиотек (после неподдержки русского, конечно) - это языки программирования, на которых они написаны. Одни на дотнете, другие на java, третьи вообще черт пойми на чем. Ну и Томита у всех на слуху, да и по реализации самая адекватная, потому выбор и пал на нее.
Как скучно я живу.
gOuTM, что начать, программирование? Nks, почему?
vas3k, >> Ну и Томита у всех на слуху Где еще про Томиту пишут, может кто-то предлагает готовые наработки в добавок к встроенным?
ikud, "на слуху" скорее всего потому что сам Яндекс про нее активно пишет. А вот статей по разработке правил для Томиты кот наплакал, в основном это PDF-слайды презентаций того же Яндекса. По запросу "томита парсер" на первых двух страницах находится 99% имеющейся по ней информации, остальное лишь додумывать.
Есть задача парсить форумы с целью поиска определенной смысловой информации, это возможно сделать?
Однозначно лайк👍
Очень крутая статья! Лайк
Пизды дам! Лайк