≡

Кому лень читать, могут сразу отмотать в конец, там картинка.
Вчера мне выдался свободный денек и я решил посвятить его кодингу «для себя». Давно вынашивал план написать спам-фильтр для блога на основе каких-нибудь алгоритмов машинного обучения. Что-то типа собственного Akismet, только хуже. Конечно, ценность у проект представлял сугубо для меня, но саморазвитие - это же классно!
Для тех, кто не в курсе - как это все работает: в написании такой системы выбор пал на широко известные алгоритмы классификации, такие как наивный байесовский классификатор и метод Фишера (в наукозадротских кругах известный как «итеративный взвешенный метод наименьших квадратов», если я ничего опять не путаю). Хотел так же использовать давно любимые нейронные сети, но не смог нормально придумать входные сигналы. Любые попытки в конце сводились к вышесказанным классификаторам и я поклал хуй. Как известно и тот и другой метод являются примерами обучения с учителем.
Когда пара классов классификатора (кеке, каламбурчик) на Языке Самого Высокого Уровня Бетон было написано, мне внезапно пришла в голову идея. Классификатор ведь можно использовать не только для определения спама, он получился универсальный и принимал любое количество классов (категорий) для классификации. Тут как раз подвернулся под руку твиттер со своими вечными срачами и мне показалось интересным замерить количество ненависти в каждом из твиттер-аккаунтов моих знакомых. Задача показалась смешной и забавной и, конечно же, я как мудак решил ее реализовать. Никакой научной значимости и полезности для общества, в отличии отзывов на фламп, она не несет, так что можно считать, что я просто хорошо провел время.
Для обучения мне нужно было напарсить обучающее множество. Подключив python-twitter я написал простенький скрипт, который выводил твит и спрашивал есть ли в нем НЕНАВИСТЬ или ДОБРО. На обучение я убил, наверное, больше часа. Всего было собрано по больше 500 твитов в каждой из двух категорий, а сколько вашего я говна начитался - жесть. Но это все равно крайне мало для действительно показательных результатов, я просто заебался. Метод Фишера, реализованный в системе как главный, достаточно хорошо определяет вероятность и не будет лажать как Байес, если слово встретилось только 1 раз в какой-то категории. Будем надеяться. В качестве порогов я задал 0.8, то есть сообщение считается злом или добром только в случае более чем 80% уверенности. Запуск производился на 300 последних твитах пользователя, полученных все через тот же twitter api. Ретвиты не учитывались. И еще одна важная оговорка: мне было лень регать приложения, что-то там подключать, поэтому тестовые выборки делались в «файле ненависти» есть много твитов нашего любимого The___Master, см. пикрелейтед).
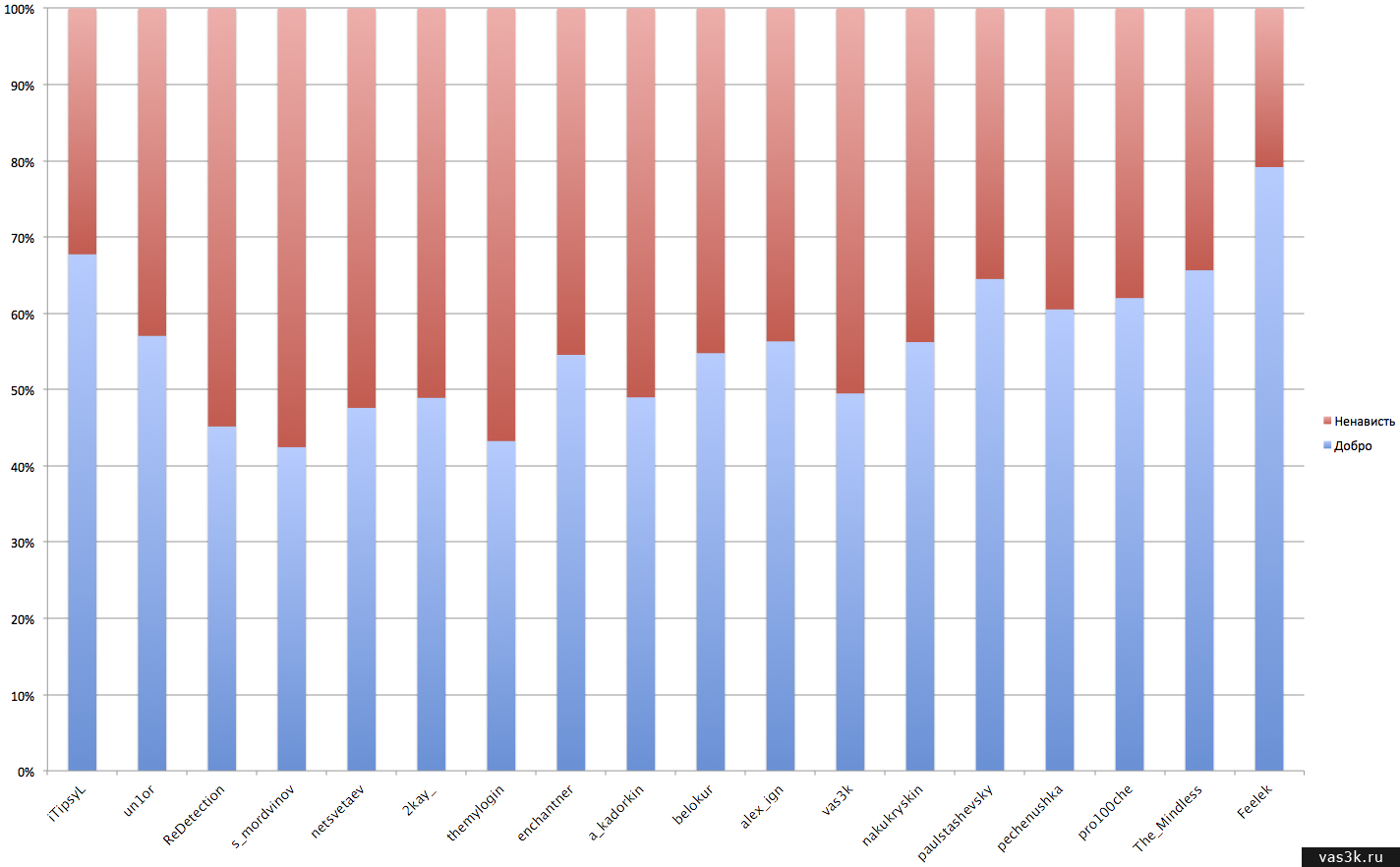
Итак, в первом раунде у нас участвуют: iTipsyL, un1or, ReDetection, s_mordvinov, netsvetaev, 2kay_, themylogin, enchantner, a_kadorkin, belokur, alex_ign, vas3k, nakukryskin, paulstashevsky, pechenushka, pro100che, The_Mindless, Feelek.
Ну и да, эти результаты ничего особо не значат и показывают в основном погоду в южной африке, всмысле определение ненависти только по небольшой обучающей выборке. Пример синтетический и «чисто на поржать», просто не хотелось тратить еще один день на нудный процесс обучения (если кто-то знает, где взять много ненависти и много добра, пожалуйста, перезапущу с ними). Нужно все это было просто для того, чтобы протестировать работу свеженаписанного классификатора. Он частенько ошибается, сарказм, например, даже некоторые люди плохо определяют, что уж говорить о машине. График скорее некоторое приближение всех по одной оси. Ну и поржать.
Позже, когда напишу нормальный класс для общения с классификатором и БД, выложу его на свой github, сможете поштырить.
Обучающие выборки не выкладываю во избежание срача и демагогии. Ну и наконец-то вот (кликабельно):
sentiment analysis, только я не понял какие фичи ты использовал, n-граммную модель языка?
potomushto, ну изначальный проект не рассчитывался именно на sentiment analysis, так что n-граммы не юзал (кстати, отличная идея, надо попробовать, благодарю). Там просто слова нормализуются (приводятся к начальной форме) и подсчитывается сколько раз какое слово встретилось там и там. На основе этого потом подсчитывается суммарная вероятность всего текста (метод фишера использует функцию хи-квадрат для этого), короче все банально. Развиваться можно еще далеко :)
Странно, я думал, что больше всего ненависти будет у тебя.
ога, получается юниграмная частотная модель. Такие проекты-велосипеды на один день люблю я. Если будет интересно добей до какого-нибудь веб-сервиса с коррекцией, пусть по-тихому обучается дальше сам.
Сейчас тонны всяких разных сервисов, в основе на сантиментах и другого nlp, ведь Твиттер один большой, охуенно большой такой сенсор, с которого удобно снимать весь этот массив данных, тем кому это нужно. Из того что я знаю: анализ спортивных событий и котировок акций, маркетинговых эвентов и обратной связи, но ещё больше, думаю что сильно больше - особо не афишируется.
Забавно, что я пишу про обработку естественного языка с таким количеством ошибок.
potomushto, а ещё с такой кашей в голове, что никому ничего не понятно.
А меня? =(
Интересно, каким образом ты задавал "ненависть". Учитывая, что пол твиттера у меня - няшности - довольно странный результат. Да и твои ровные 50% радуют ;)
Э, а чё меня пропиарили а в таблице ненависти меня нету. Как так? Это дискриминация!!! Я буду жаловаться!
The Master, у тебя акк закрытый :P Psyhister, точно, записал.
проверь меня)
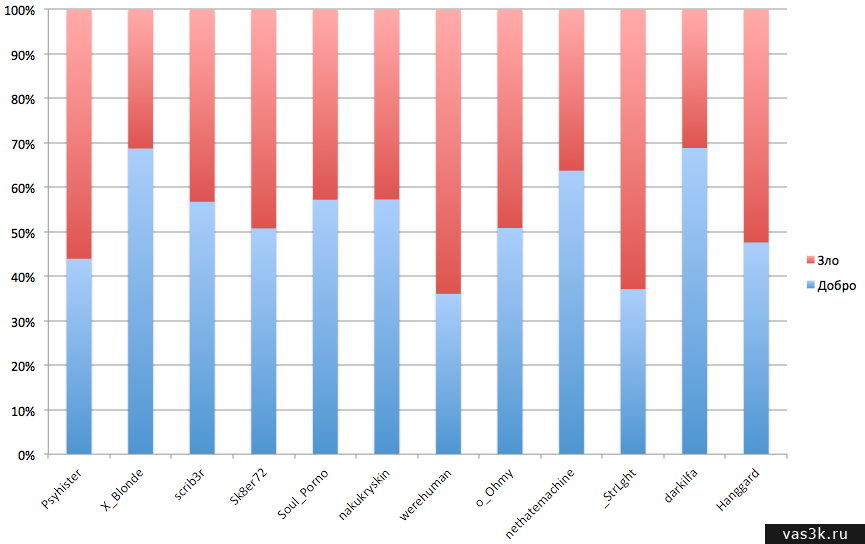
Добавил еще одну картинку
Не, у тебя определённо очень предвзятые фильтры.
werehuman, прости, я согрешил. Моя программа говно, я не умею писать непредвзятые программы. Даже мой код ненавидит тебя лично.
Интересно. Сколько, блядь, раз нужно предупредить в посте об этом, сколько раз сказать лично или еще где-то написать, что выборка мала, что обучение недостаточно, что показывает погоду, что просто ХА-ХА, БЛЯДЬ, ПОСМЕЯЛИСЬ И РАЗБЕЖАЛИСЬ, но нет же, каждый считает, что я лично сидел и его лично считал с ненавистью АХ ЭТОТ СМОРДВИНОВ И ВЕРХУМАН МЕНЯ ОБИДЕЛИ ЩАС Я ИМ ЗАРЕЖУ ДОБРА ХАХАХАХ. Да, я упомянул, что сделал главную ошибку - смешал обучающее и тестовое множество (хоть и обучающие твиты я выбирал ранние, а тестил на поздних), да, там далеко не совершенно всё, там используется, как уже обсуждали, униграммная модель, которая считает, что если слово "колбаса" встречалась больше в твитах ненависти - оно характеризует зло, обсуждение гомосексуалистов или iphone 4 - точно ненависть и наоборот. Это программа, написанная за час для лулзов, а вы побежали серьезно считать свои твиты. Это влияние пиратов на глобальное потепление, не более. Расслабьтесь, блядь.
Чо ты бугуртишь ёбана? Все расслаблены, кроме тебя.
угу. Я без поддекста спросил. Мне правда интересны критерии "добра" и "зла".
Alive, я тебе потом расскажу что такое машинное обучение, раз ты пропускал пары по нему. И как конкретно работает эта система на пальцах.
V@s3K, Как работает, я себе представляю более менее (хоть у нас и не было пар по этому всему). Мне интересен "словарь" именно.
Alive, выборка из 1000 старых твитов разных людей (штук 20 по-моему), к сожалению, в том числе и ваших.
V@s3K, аааар. Я не про это же. Тупо приведи пример твита, который отправился в "зло". Не очевидного "заебали суки", естественно :(
Alive, если я начну приводить примеры твитов, тут начнется "да я совсем не со зла это писал, это шутка была" и.т.д. Ну и плюс ошибки классификатора. Так что не буду.
V@s3K, Вааааася :(
Охохо, я 4-5 по злу. Join the dark side, we have cookies! :D
И ваще, харе сраться, охуенно же. Я даже первые 2 коммента не понял =(
ыы) я в топе злости :D
Накукрыскин прямо одна из обителей зла :3
@nakukryskin, почему это? У тебя наоборот высокие показатели достаточно.
кстати. если скармливать нейронной сети текст и разницу времени между предыдущим твитом, научить ее определять ФУТБОЛ The_Master'а, потом прикрутить это дело к yahoo pipes, то можно будет автоматически фильтровать всякое такое из ленты :)
меня забыл! у меня вообще тви полон зла!