≡
Предыдущий небольшой обзор для поста про программирование привлек достаточно внимания, чтобы продолжать. Думаю теперь стоит пойти по порядку. Начать с описания по моему мнению самой важной и основополагающей меры в статистическом анализе языка — tf-idf. Посты будут рассчитаны на программистов, которые не хотят погружаться в дебри, но им интересно узнать «как это работает» просто для саморазвития. Лично мне всегда приятно читать именно такие посты, для кого-то они будут стимулами погружаться глубже, для других — просто интересным чтивом из параллельной области.
Инвертированный индекс — самая простая и основополагающая структура данных в поиске, которую без труда поймет даже ваш кот. В отличии от Прямого Индекса, где для каждого документа хранятся списки слов, в Инвертированном Индексе для каждого слова хранятся списки документов, в которых оно встречается. Все просто, как предметный указатель в конце книг.
Я очень не люблю дотошные тексты из учебников, в которых вводят множество точнейших определений каждого термина, я же специально упрощаю. Например, использую «слова» вместо «лексемы», «словоформы» и.т.д. потому что считаю, что у читателя есть хоть капелька логики чтобы понимать смысл, а не докапываться до определений. Это допущение так же будет актуально и в дальнейшем.
Слова обычно хранятся либо в начальной форме, как например именительный падеж или инфинитив, либо в виде их основ (без окончаний и других левых морфем). Понятно зачем. Начальную форму для слова определить обычно просто, нужен морфологический анализ, но в отличии от синтаксиса и сематики, с морфологией работать очень просто, алгоритмы морфологического анализа описаны и просты, можно использовать готовые библиотеки под любимый язык программирования. Под свой любимый язык я использую pymorphy2. Определение основы слова — еще более быстрая и простая операция, называется стемминг, ее алгоритмы так же популярно описаны и обычно заключаются просто в последовательном отрезании лишних кусков от слова пока те не закончатся. Однако главным минусом перед морфологическим анализом является то, что такие формы как «люди» и «человек» считаются разными словами, так как имеют разные основы. Зато работает в несколько раз быстрее морфологического анализа.
Образованный читатель уже догадался, что имея инвертированный индекс уже можно делать поиск — разбить запрос на слова и выбрать документы для каждого. Однако у такого метода один большой недостаток — система будет выдавать абсолютно все документы, в которых встречается хотя бы одно слово запроса. Представьте что будет если это предлог. Так мы подходим к такому понятию как ранжирование.
Действительно, обычно мы хотим видеть сверху те документы, которые больше всего релевантны нашему запросу. Начать выкручиваться можно уже сейчас, например, во время выборки считать сколько слов из запроса входит в документ (наверное чем больше, тем больше документ нам подходит). Можно сохранять не только документы, в которых слово встретилось, а еще и местоположение слова в документе. Тогда мы сможем еще больший вес ставить тем документам, в которых слова стоят радом или ближе к началу. Можно сохранять кроме всего этого еще и место документа (заголовок, тело, комментарий) — тогда если слово встречается в заголовке, оно имеет больший вес, чем то же слово в теле документа. Часто это называют Зонным Индексом, почти все доступные поисковые библиотеки умеют такое: Sphinx точно, Lucene вроде как тоже, но плохо документирует это. Раньше еще думали, что полезно учитывать частоту слова в документе, но SEO'шники убили эту идею.
Как видно, даже имея простой инвертированный индекс уже можно накрутить вокруг него множество условий. Эти условия называют Метрики. Каждому документу по каждой метрике присваивается значение, чаще всего нормированное от 0 до 1. Затем можно соединить это всё в общее значение — ранг, в простейшем случае просто сложив. А можно сложить с коэффициентами. И если грубо, то это есть формула релевантности. В современных поисковых машинах, по обрывкам предоставляемой ими информации, такое уже не используется, но лет 10 назад вполне срабатывало, а всё более новое для простого обывателя остается закрытой информацией.
Но всё это детский лепет по сравнению с той метрикой, название которой гордо стоит в заголовке — TF-IDF. Эта мера используется абсолютно во всех даже современных поисковых системах как один из компонентов, а большинство доступных простым смертных библиотек опираются на нее как на основную. При всей своей важности и крутости, она чрезмерно проста, чем и красива. В нее входят два сомножителя: tf и idf.
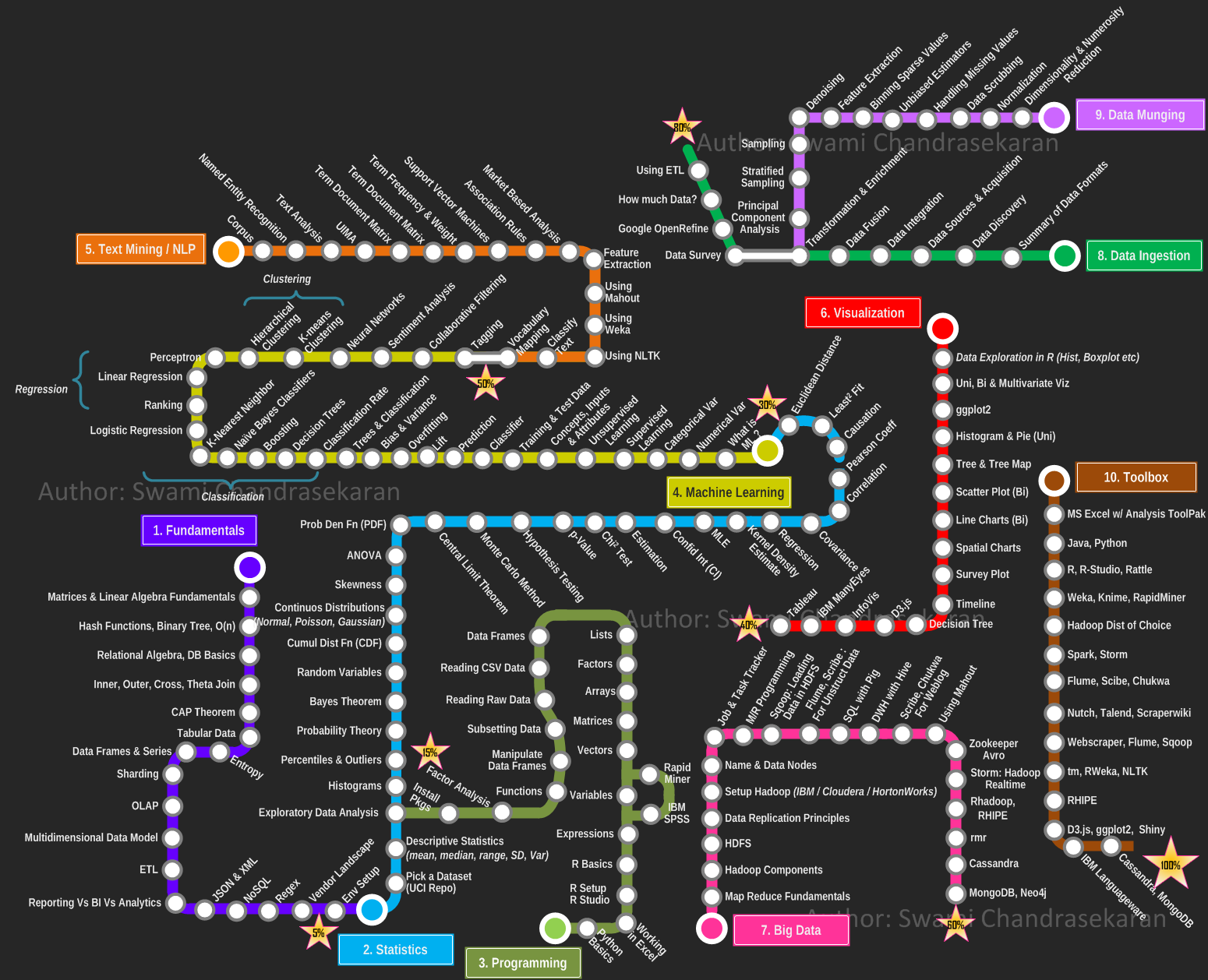
TF (term frequency — частота слова) — отношение числа вхождения слова к количеству всех слов документа. То есть чем чаще входит слово в документ — тем оно важнее для данного документа. Всё логично.
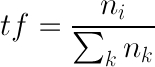
IDF (inverse document frequency — обратная документная частота) — инверсия частоты, с которой слово встречается во всех документах. То есть если данное слово встречается практически в каждом документе, то оно общеупотребимо и менее важно для поиска. IDF сразу убивает все частицы, предлоги и другие служебные части речи, а так же часто используемые слова.
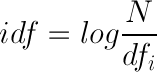
Таким образом, метрика tf-idf является просто произведением этих двух частот. То есть самое важное (с большим весом tf-idf) слово — такое, которое чаще всего встречается в одном документе, и реже во всех остальных. Всё это очень просто — чем больше «важных» слов из запроса входит в определенный документ, тем он более релевантен.
На практике чаще всего берут формулу ранжирования Okapi BM25, хорошо описанную в Википедии. Почитав выступления Яндекса на РОМИП можно заметить, что сам Яндекс ее очень и очень, и очень, и очень любит, что как бы намекает. В BM25 входит несколько дополнительных коэффициентов, но смысл остается точно такой же: считай веса слов, сортируй.

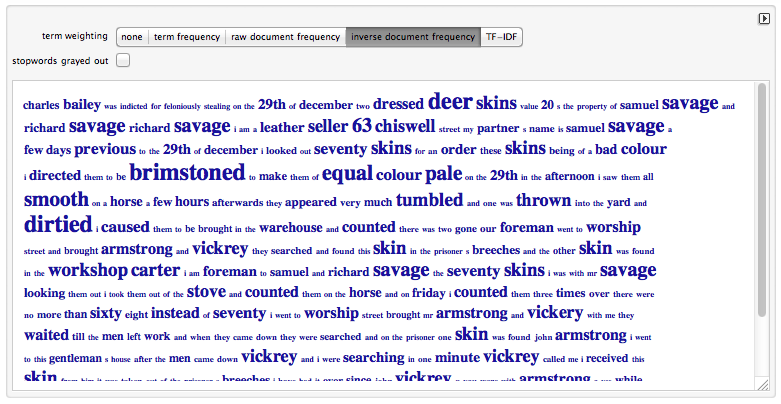
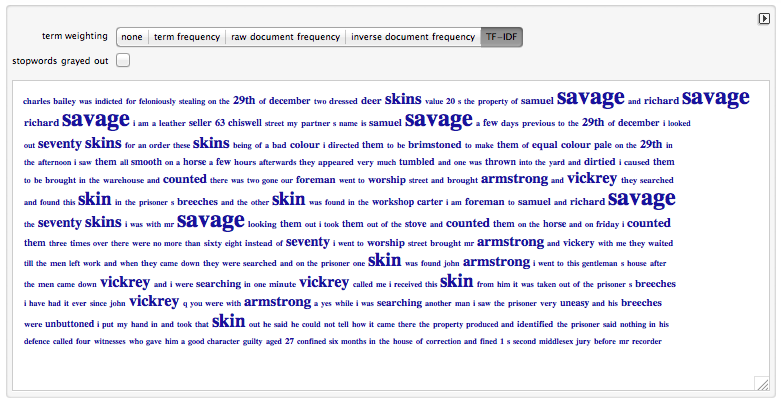 Примеры вычисления значений tf-idf для документа
Примеры вычисления значений tf-idf для документа
Но на этом прелести tf-idf только начинаются. Зная меры слов в документе можно сравнивать количество «воды» в двух документах — чем больше в одном из них общеупотребимых слов, не несущих смысловой нагрузки, тем более он «водянистый». Вероятно подобным образом Яндекс подбирает заголовки в Яндекс.Новостях, а я же у себя на Futurise так же ищу подходящие описания, правда я еще учитываю их длину.
Важными областями применения меры tf-idf являются так же поиск похожих документов или их классификация по темам. Как вообще можно определить, что документы похожи или принадлежат одной тематике? Если не углубляться в алгоритмы классификации, можно воспринимать их как такие черные ящики, которым дают много-много данных, а они находят как эти данные разделяются по классам. Тогда можно взять все слова документа, нормализовать, а затем для документа составить список пар типа «слово»: «мера», где мера — в простейшем случае +1 - входит, -1 — не входит, либо количество вхождений слова в документ. Для каждого словаря прописать класс, к которому документ относится (ручками или автоматически, не важно). Затем скормить эти списки классификатору, например самому популярному libsvm, в большом количестве и он научится с определенной погрешностью определять для каждого нового такого же списка его класс. Для поиска похожих нужно так же скармливать классификатору, но уже по паре списков с флагом «похожи»/«не похожи». Документов понадобится много, так что надо бы заранее определить где их взять, но это дело техники.
from svmutil import *
results = [1, 2, 2]
vectors = [{1: 1, 3: 1}, {2: 1, 3: 1}, {2: 1, 4: 1}]
model = svm_train(results, vectors, '-t 0 -c 5')
label, acc, val = svm_predict([0], [{3: 1, 4: 1}], model)
А если вместо обычной меры взять для каждого термина его tf-idf? Тогда наш классификатор не только будет знать, что какое-то слово входит в документ, он еще и научится понимать, что в одном документе это слово является важным, а в другом — просто встретилось пару раз случайно. В этом и вся красота, точность классификации при таком раскладе моментально возрастает. В статьях тех, кто писал такие классификаторы, точность достигала 90-95%, что очень недурно, учитывая, что точность живого человека обычно тоже не 100%. Ну и Яндекс тоже развлекался и не раз.
Для определения схожести двух документов с использованием tf-idf существует еще один хороший способ: векторная модель. Она помогает использовать те же самые списки пар «слово»: «tf-idf» без классификатора. Эти списки и являются N-мерными векторами документов, где N - количество всех известных системе слов. То есть такие же списки пар, где рисутствующим в документе словам ставится значение tf-idf, а отсутствующим соответствует значение 0. Между двумя такими векторами можно посчитать угол, а точнее его косинус, который и будет показывать насколько документы похожи: чем меньше угол — тем больше косинус, а значит и похожесть. А как посчитать косинус между векторами учат еще в школе, он равен скалярному произведению векторов (сумма произведений соответствующих координат) деленному на произведение их длинн (эвклидова длина — корень из сумм квадратов координат). Например на модели векторного пространства основана поисковая библиотека Apache Lucene, хотя BM25 она тоже умеет (см. главную страницу).
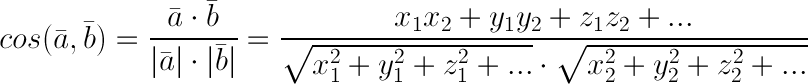
На этом применения меры tf-idf не заканчиваются, именно потому я поднял эту тему, так как именно tf-idf чаще всего в будущем встречается во все новых и неожиданных местах. Конечно, при использовании tf-idf возникают и проблемы — это скорость. Обычно они решаемы путем хранения в индексе заранее просчитанных количеств вхождений.
Сможете ли вы после прочтения статьи написать свой простой поисковый велосипед? Ну, погуглив дополнительную информацию, возможно. Правда очень медленный, потому что я нарочно опускал все методы оптимизации в угоду простоте описания. Сможете ли вы составить конкуренцию Google и Яндекс — нет, в этом деле они ушли на десяток лет вперед и на данный момент не раскрывают своих секретов. Что для нас, конечно, печально.

Прочитал с удовольствием, вообще норм. Пиши ещё.
О, прикольно. Спасибо за статью, я оказался твоей ца сегодня. Оказывается, что в универе мы в очередной раз изучали устаревшие технологии. Печально. Дуров, верни вастрикрутриноль!
Пиши ещё. С русским NLP как-то тягостно. Начиная от корпуса :( В этом плане повезло питону, что там есть хотя бы pymorphy2. Года три назад встречался с их двумя контрибьюторами, когда это ещё был https://bitbucket.org/kmike/pymorphy/ здесь, в академе. Меня тогда неплохо опустили на землю по уровню развития обработки естественного языка, и что почти для всего в русском языке нужно делать свои велосипеды/адаптировать чужие.
Спасибо, хорошая статья, все просто и понятно.
Откуда взяты скриншоты с примерами расчета TF-IDF?
PAVEL, вот с этого приложения: http://demonstrations.wolfram.com/TermWeightingWithTFIDF/
Респект и уважуха! Наконец то до конца понял как посчитать схожесть двух текстов