≡
В одном из прошлых проектов мы реализовывали систему «заражения» ближайших к источнику пользователей. Одно движение пальцем по экрану запускало процесс геопоиска, а затем сотни записей и удалений в базе. Но чем больше данных появлялось, тем хуже становилось. Итак, перед вами задача: достаточно быстрый и устойчивый поиск k-ближайших соседей на поверхности земного шара. Искать нужно не просто ближайших, а еще и удовлетворяющих трем условиям: еще не зараженных, еще не голосовавших и инфицируемых. Инфицируемость определяется эвристическим алгоритмом и ее определение мы опустим.
Берем PostgreSQL. Отличная тема, я ни раз говорил, что его и ядро Linux я считаю двумя лучшими opensource-проектами в истории. Для поиска ближайших берем расширение PostGIS с поддержкой геоиндексов, не так ли? Нет, не так. С 2011 года в основной состав PostgreSQL включены операторы <->, <#> и GiST-индексы, которые позволяют делать поиск ближайших без сторонних библиотек. Никакого мусора в проекте и «ну все на хабре так делают» — это залог успеха. Заявляемая производительность — «меньше 10 ms на 2 млн записей» нас устраивает. 2 млн активных пользователей — это очень большой проект, а 10 ms в распределенной СУБД — копейки, зачастую join дороже.
Получаем примерно такой запрос:
select users.*
from users
left outer join votes on votes.user_id = users.id and votes.post_id = %(post_id)s
left outer join infections on infections.user_id = users.id and infections.post_id = %(post_id)s
where votes.post_id is null and infections.post_id is null and users.is_infectable = true
order by users.coordinates <-> point(%(latitude)s, %(longitude)s)
limit %(limit)sНовый пользователь получает возможность заразить своим постом только 4-х людей вокруг. С повышением его индекса влияния, если он ведет себя хорошо и не репостит всякую чушь, это количество растет. PostgreSQL отлично справляется с такими объемами данных и не сильно-то напрягается. 2000 записей в секунду? Ерунда, 10% CPU на db.m3.2xlarge инстансе AWS (примерный аналог небольшого 8-ядерного сервера с 30 Гб RAM).
Проект потихоньку запустился, про него написали все крупнейшие технические издания, и вам наваливает пару сотен тысяч первых пользователей. И здесь начинаются проблемы. Дело в том, что скорости порядка 2000 IOPS (операций ввода/вывода в секунду) на амазоне стоят $200 в месяц, что примерно сопоставимо со стоимостью аренды самого db.m3.2xlarge сервера. Как только вы упираетесь в IOPS, это примерно как упереться в 100% CPU. Очень неприятно, да еще и проходит не моментально. Можно докупить еще тысячу, но это уже $300. А если нам нужно завтра вырасти в 50 раз? Ценник начинает кусаться, а ведь CPU занят всего процентов на 10.
Перед нами вживую пример того, что часто объявляют минусом реляционных СУБД — они ОЧЕНЬ не любят когда много пишут и удаляют, но мало хранят. И несмотря на старую шутку про стартаперов, которые всё делают на NoSQL, сейчас действительно пришло время выбирать дополнительное хранилище.
MongoDB — в задницу, просыпаться ночью от segmentation fault из-за очередного незакрытого бага, нет уж, увольте. Cassandra — круто, но Java, нужны будут люди чтобы это поддерживать. Aerospike — дорого. Tarantool — быстро, в памяти, со скиптами, но чето ссыкатно опыта работы и знакомых нет, куда в случае чего бежать за помощью не понятно. Да еще и однопоточный как Redis. Ну вот да, остается только Redis. Всё в памяти, то есть проблем с I/O не будет никогда. А еще у амазона есть платформа ElastiCache, в которой настроенный масштабируемый редис прям из коробки. Надо попробовать.
Но как организовать геопоиск на Redis, который умеет хранить, умеет работать со множествами, но совершенно не умеет считать что-то сложное? Быстрое гугление показывает экстеншен redis-geo, который обещает путем установки кастомной сборки редиса некоторые фичи географического поиска со скоростью около 100000 операций в секунду. Поставим, проверим.
Поиск по 5000 точкам в радиусе 3000 км на макбуке про с i7 занимает... 3 секунды. Что за фигня, где обещанные микросекунды? Оказывается он выбирает все точки через geohash, а потом для каждой считает расстояние. На расстоянии 20 км и паре сотен точек это действительно быстро, но в масштабах всей земли и миллионов точек — лажа. Редис однопоточный, потому это блокировка всего сервера на 3 секунды. Даже целым редис-кластером нужной производительность не добиться. Лажа.
Но использование алгоритма geohash — интересная идея, нужно развивать. Для тех кто не в курсе, GeoHash — это система кодирования пары latitude/longitude в одно число, или же при переведении в 36-ричную систему счисления — обычную строку (поиграть с демо можно здесь).
Например: координатам г. Бобруйск (53.13810821063661, 29.217967987060547) соответствует хеш u9ky2c7zg.
Однако если мы переведем u9ky2c7zg обратно в координаты, мы получим (53.138101, 29.217947). Точность при кодировании была отброшена, но шестой знак после запятой — это ошибка порядка 5 метров, более чем достаточно. Однако это кодирование не простое. Если отбросить последний символ полученного хеша (u9ky2c7z), то получаем координаты (53.13804, 29.21797). А если еще 4 символа (u9ky2) — (53.17, 29.36). Этого до сих пор вполне достаточно, чтобы определить, что мы в Бобруйске. Оставив всего 2 символа (u9) мы можем сказать лишь то, что координаты где-то в Беларуси (или кусочке Литвы).
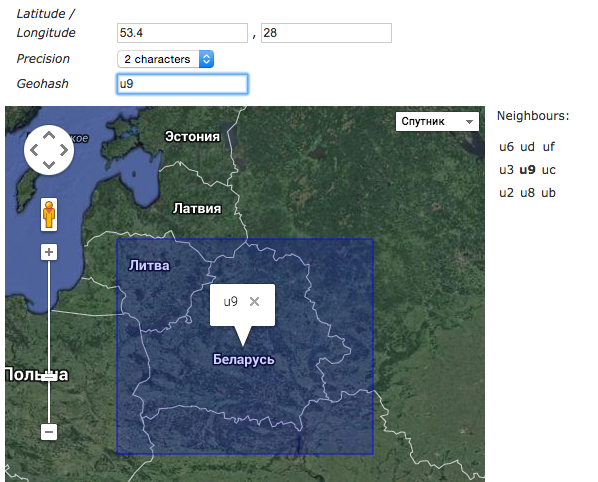
Третьей важной особенностью метода является то, что для любого geohash можно с помощью простых математических операций получить 8 его соседей. Имея эти знания можно попытаться что-то реализовать на Redis. Ясно, что искать перебором ближайших соседей на однопоточном редисе — плохая идея. При необходимой точности порядка 50 метров (это 8 символов геохеша) таких соседей будет 8^36 = 3 с 32 нулями после.
upd: Спустя год после выхода этого поста Redis имеет geohash прям из коробки: http://redis.io/commands/geohash
Но мы можем «зумить» путем отбрасывания последнего символа. У Redis есть операция KEYS, которая может искать по маске, например: «KEYS u9ky2*». Можем искать по различным маскам и за 8 операций найти всех до точности 5000 км, а дальше просто пробежать по соседям.

Используя set'ы вида geo:<geohash> = {user_id, user_id, ...} реализуем поиск с помощью KEYS и проверяем на 150 тысячах точек.
6 секунд. Говно.
Переписываем всё на хранимых в Redis процедурах LUA. Те же 6 секунд.
Говно.
Замена KEYS на SCAN тоже ничего не дает, операция выполняется так же за O(N), где N — количество ключей в базе, просто теперь не блокирует весь сервер. 6 секунд — по прежнему неприемлемо. Выход? Хранить ID каждого пользователя с 8 точностями. Если ID это integer, пользователей 100 млн, то это всего 8 bytes * 8 * 10^8 = 5.6 Gb. Для 100-миллионного проекта найти 5.8 Gb RAM — копейки (hint: образованный читатель здесь заметит, что Redis в своих структурах хранит не чистые int'ы, а обернутые в собственные объекты, потому эти теоретические выкладки стоит увеличить в несколько раз).
Храним каждого пользователя сразу в 8 сетах вида geo:u, geo:u8, geo:u8k, и.т.д. Теперь выборка для любой точности может производиться за 1 команду. Кроме всего прочего нам необходимо выбирать не просто всех юзеров, а тех, кто заражаем и еще не голосовал и не заражен.
Так как каждый geo:* — это множество, редис имеет операцию вычитания нескольких множеств SDIFF и очень быстрые операции объединения SUNION и пересечения SINTER. Чтобы реализовать задуманное нам нужен один union с множеством «заражаемые» и два diff с множествами «проголосовавшие» и «зараженные» для каждого такого geo-квадрата.
Двигаясь от 8-й точности можно за O(1) с помощью SCARD получить размер geo-квадрата (количество пользователей в нём), затем 8 его соседей, а затем, если это количество недостаточно, переключиться на меньшую точность и повторить.
def search(post_id, latitude, longitude, limit):
precision = 8
user_hash = geohash.encode(
latitude=latitude,
longitude=longitude,
precision=precision
)
users = set()
while precision > 0:
user_square_hash = user_hash[:precision]
users = users.union(users_in_squares(
squares=[user_square_hash],
post_id=post_id,
limit=limit
))
if len(users) >= limit:
break
neighbor_square_hashes = geohash.neighbors(square_hash)
users = users.union(users_in_squares(
squares=neighbor_square_hashes,
post_id=post_id,
limit=limit
))
if len(users) >= limit:
break
precision -= 1
return users
def users_in_squares(squares, post_id, limit):
users = set()
pipe = slave.pipeline(transaction=False)
for square_hash in squares:
pipe.scard("geo:%s" % square_hash)
users_in_square = sum(pipe.execute())
if users_in_square > limit:
pipe = slave.pipeline(transaction=False)
for square_hash in squares:
pipe.sinterstore(
"geo:%s" % square_hash,
"infectable:users",
"tmp:geo:infectable:%s" % square_hash
)
pipe.sdiff(
"tmp:geo:infectable:%s" % square_hash,
"post:%s:infected" % post_id,
"post:%s:voted" % post_id
)
pipe.delete("tmp:geo:infectable:%s" % square_hash)
users = users.union(*[u for u in pipe.execute() if isinstance(u, set)])
return usersТолько имея нужное количество мы можем производить операции SUNION и SDIFF. К сожалению, Redis не позволяет сделать SUNION и SDIFF сразу в одном запросе, потому нам нужно записать результаты SUNION во временное множество с помощью SUNIONSTORE, а затем его про-diff-ать с оставшимися.
Реализуем. 0.0001 секунда в лучшем (густонаселенная Германия), 0.01 секунда в худшем (Сибирь) случае, вместе с отправкой/приемом/парсингом данных между серверами. Терпимо. Реализуем все остальные алгоритмы, тщательно тестируем добавление/удаление пользователей в множества geo:*, начинаем копировать часть трафика на тестовые сервера чтобы протестировать под нагрузкой и...
Под нагрузкой имеем время обработки под 3 секунды и блокировку всего сервера. В качестве апп-фреймворка у нас асинхронный Tornado, либа редиса была специально выбрана официальная, а она блокирующая. Однако неблокирующая реализация работает в десятки раз медленнее, из-за чего не имеет особого смысла. Но всё равно пробуем переписать всё на неблокирующем tornado-redis'е.
Под нагрузкой снова 2-3 секунды на поиск. Даже если запустить tornado в 16 процессов на 4 CPU с connection pool'ом на 20 соединений в каждом. Но почему?
Потому что сам Redis тоже однопоточный, какими бы неблокирующими библиотеками мы его не обкладывали, многопоточным он от этого не станет. При выполнении большого diff'а он начинает блокироваться до завершения операции. А еще в это время Redis бомбардируют сотни запросов на обновление местоположения. Diff выполняется быстро, несколько миллисекунд, потом еще несколько десятков мс на отправку, однако после его выполнения torando не возвращая управление в IOLoop вызывает остальные diff'ы. В сумме набегает кругленькая сумма миллисекунд. И несмотря на то, что в это время другие вполне бы могли выполнить множество операций чтения, Redis тщательно занят нашим diff'ом и не хочет ничего читать. Встретились два однопоточных одиночества, мать их. Нужен слейв.
Amazon ElastiCache позволяет поднять read-only slave сервер для существующего за пару кликов мышкой. Теперь у нас есть откуда читать, но что делать с постоянно занятым master'ом? Нужно отказываться от единственной операции записи, а именно от SUNIONSTORE. Если бы разработчики Redis позволили на read-only слейвах создавать временные переменные — всё было бы куда проще, а так придется снова поебаться.
Быть может эффективнее получать все данные из Redis и делать объединение множеств уже в Python? Тестим. Нет, результат ожидаемо в сотни раз медленнее. Вместо того, чтобы работать в памяти одного сервера, нам приходится гонять по сети сотни килобайт.
Единственный выход — хранить в geo:* уже результат union'а, то есть только тех пользователей, которые точно могут получать заражения.
А что если на 8 точности geo (20 метров) хранить всех, а на всех нижних — только заражаемых? Таким образом мы избавляемся от любых операций записи и получаем возможность масштабироваться на бесконечное число read-only серверов.
def users_in_squares(squares, post_id, limit):
users = set()
pipe = slave.pipeline(transaction=False)
for square_hash in squares:
pipe.scard("geo:infectable:%s" % square_hash)
users_in_square = sum(pipe.execute())
if users_in_square > limit:
pipe = slave.pipeline(transaction=False)
for square_hash in squares:
pipe.sdiff(
"geo:infectable:%s" % square_hash,
"post:%s:infected" % post_id,
"post:%s:voted" % post_id
)
users = users.union(*[u for u in pipe.execute()])
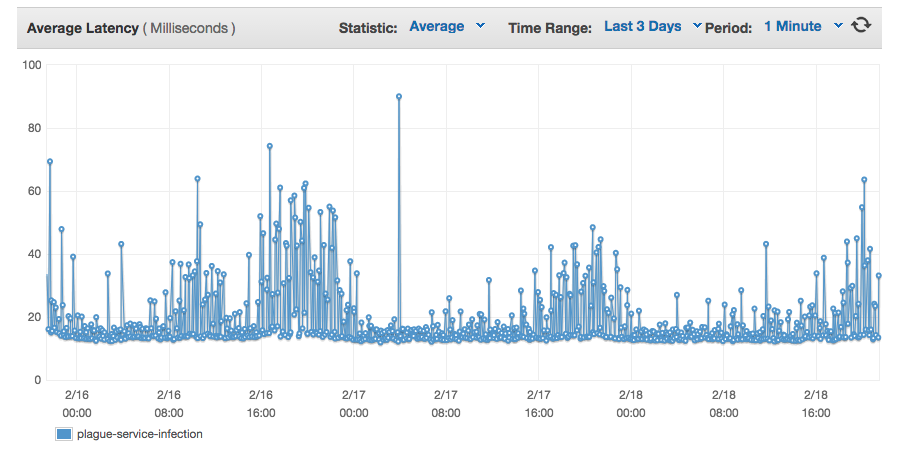
return usersПо графикам на балансировщике обработка запроса занимает от 10 до 60 мс под нагрузкой. Отлично, хотя можно еще оптимизировать.
Выводы:
Если вам нужно много писать и удалять из таблицы, скорее всего вы быстро упретесь в I/O традиционных SQL СУБД.
Одним серверов Redis даже не среднего размера проектах можно обойтись только если он используется как простой кеш. Если используется что-то сложнее операций GET/SET, скорее всего понадобится кластер. Встроенной в redis кластеризацией пока никто не пользуется, а вот twemproxy вполне годен.
SDIFF на больших множествах — узкое место, вспомните курс алгебры множеств и перепишите на другие операции. SINTER самая быстрая, SUNION на втором месте. Используйте сначала их чтобы уменьшить размерность множества.
Pipeline ускоряет отправку данных в Redis в десятки раз, однако если отправить пару тысяч команд, да еще и сказать выполнять их атомарно — придется страдать.
Так как мы работаем с NoSQL, да еще и храним все данные в памяти, нужно всегда быть готовым к тому, что всё сломается и из бекапа не восстановится. И иметь скрипт «судного дня», который за конечное время сможет восстановить работоспособность. Ну и конечно, все жизненно важные данные нужно дублировать в SQL.
Операция KEYS действительно (как и написано в документации, но кто верит документации не проверив, хах) может использоваться только для отладки. Потому что она лочит всё и пробегает ВСЕ ключи в БД. Альтернатива ей — операция SCAN, хоть и кажется хорошим решением, на деле работает еще медленнее (просто не блокирует всю базу), так как по сути делает то же самое.
Если оно работает медленно, скорее всего переписывание всего на хранимых процедурах LUA не поможет ничем. А тем более реализация всей логики на ней. Если хотите упороться LUA прям внутри БД, попробуйте tarantool, потом мне расскажете как оно.
Экономия памяти становится главным приоритетом, а её утечки снова головной болью. Почти каждая операция записи должна сопровождаться установкой времени жизни EXPIRE/EXPIREAT, даже если это добавление в существующую структуру (дело в том, что при опустении сета редис его удаляет, соответственно при последующей записи это будет уже новый сет без expireat и опа — память потекла). Hash-таблицы эффективнее по памяти, чем просто куча ключей. Вот тут можно почитать подробнее.
Слушай,спасибо за статью! а aioredis тоже блокирующий? И еще один вопросик: как я ([email protected]; stvlpotapov) узнаю, что мне пришел ответ?:)
Читал как детектив на каком-то славянском языке. Половина слов не понятна, но очень увлекательно. Спасибо =)