≡

Вы молодые, шутливые, вам все легко (с). Мы тут про стартапчики да про стартапчики, вот только в рутине дейтингов и геолокейшена стали забывать ради чего мы вообще все выбрали IT как путь. Не те, которые потому что хорошо платят и в США съебать, а другие, которые ради Идеи и скорейшей технологической сингулярности.
Несмотря на все айфоны и уберы, я до сих пор считаю самым величайшим достижением компьютерной эры до появления интернета — табличные процессоры (да-да, которые все называют Excel, потому и я так буду, хоть он был далеко и не первым). Это вещь, который умна настолько, насколько умён её пользователь. При этом он позволяет делать то, что раньше требовало примерно бесконечного времени вычислений на калькуляторе и других инструментах, то есть по сути автоматизирует, в разы ускоряет процессы и делает человека с экселем в десятки раз эффективнее человека даже с самым мощным калькулятором. При этом он максимально простой, но не проще, чем нужно. Он является абсолютным продолжением мозга своего хозяина, мощным настолько, насколько квалифицирован его пользователь, выполняя те задачи, которые человеческий мозг выполняет плохо и не трогая другие, по которым мозгу нет и не будет равных еще долгое время.
Вот как, блеять, Notes.app, в котором я набираю этот текст, упорно хочет заменить "кавычки" во всех html тегах на по его мнению красивые «ёлочки», совершенно не понимая почему я сейчас его закрою и пойду набирать продолжение поста обратно в никогда не подводящий меня Sublime. Вот это я называю — не трогать те вещи, где я лучше разбираюсь и упрощать рутину.
Большая часть современного IT пытается сделать программу «умнее» человека, вместо того, чтобы делать человека умнее с помощью программы.
Для меня эта разница колоссальна. Именно поэтому я привел в пример Excel. Впрочем, про рак IT я подробно писал ранее, в одном из предыдущих постов, который кстати теперь открыт не только для илиты.
Отчасти это идея объясняет почему всю свою исследовательскую деятельность в универе я посвящал «ненужным», по мнению многих, поисковикам, или почему в глубине душе я уважаю навигаторы, справочники, да тот же 2гис, хоть с ними у меня личные счеты. И почему так скептически отношусь к любой идее «умного дома» (хештег #домдурачок снова с нами), «самообучающегося помощника» или «искусственного интеллекта». А на сегодняшний рассказ меня сподвигли одни ребята.
Это калифорнийская компания Palantir. Наверняка некоторые слышали про них, если вдумчиво читают СМИ, например о том, что они третий по стоимости стартап после Uber и AirBnb в США, о котором, однако, вы ничего не знаете. Я вот тоже не особо по началу обращал внимание чем кто там у них в калифорниях занимается, может опять сервис анимированных селфи для неодарённых интеллектом школьников, но это вроде Snapchat называется.
Цены на штучную установку Palantir, по данным СМИ, варьируются от 5 до 500 млн долларов, потому я пока не смогу дать вам ссылку на .exe. Такая стоимость объясняется тем, что эта штука не простое приложение, а целый набор высокопроизводительных серверов баз данных и обработки, которые допиливаются и устанавливаются под заказчика. То, что видим мы на скриншотах — лишь страшненький веб-интерфейс ко всему этому делу.
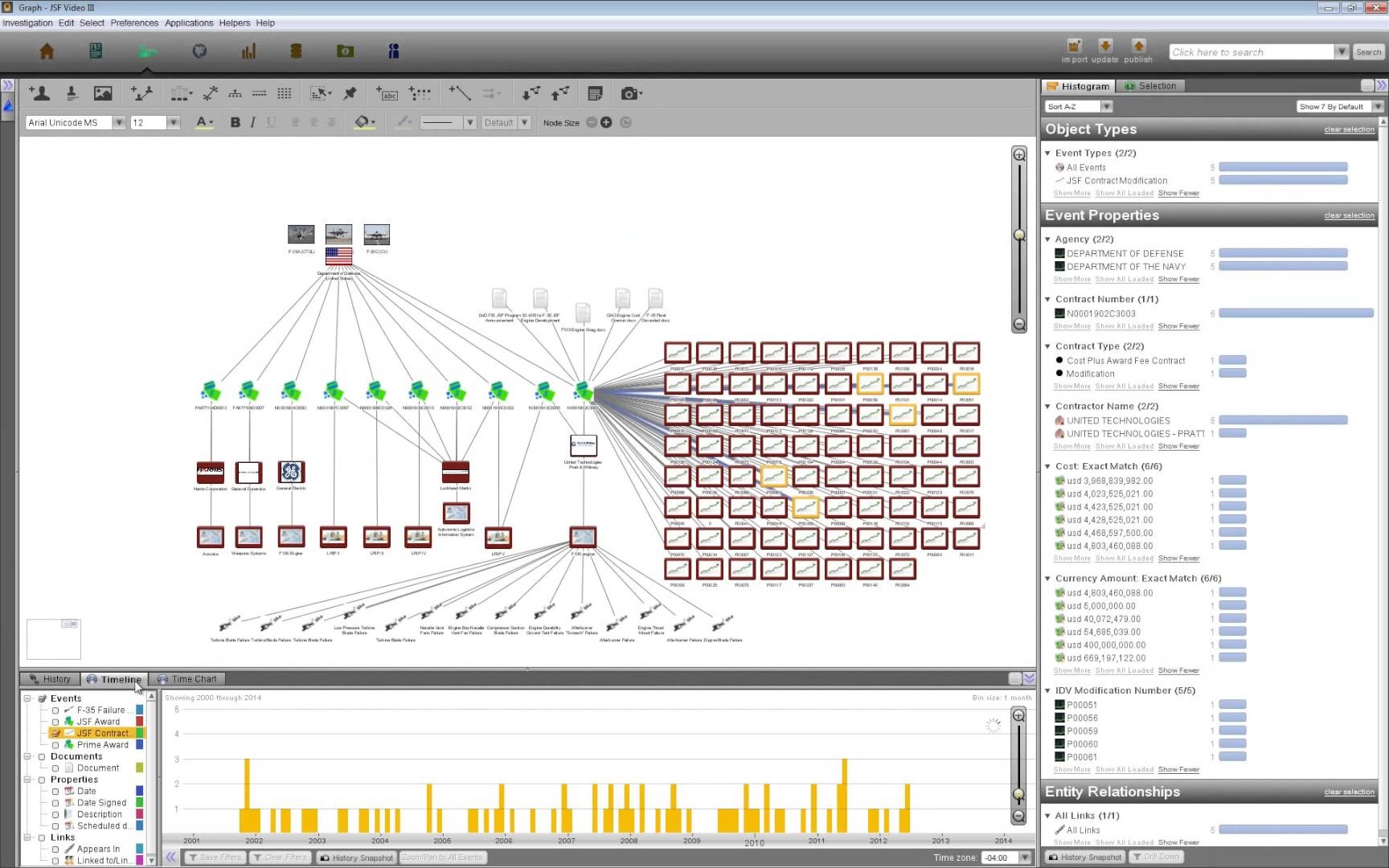
Пробираясь через дебри маркетинговой чуши и громких высказываний, по обрывкам видео и кусочкам информации, я попробовал понять что вообще этот Palantir технически делает. По сути он занимается тем, что берет поступившие в него данные (абсолютно любые — тексты, документы любых форматов, веб-сайты, видео, аудио, базы данных, итд) и превращает их в единые «объекты», с которыми можно работать человеку, совершенно не думая, в каком формате они представлены. Работать так же мощно, как работает с таблицами тот же excel. То есть можно взять, например, csv-файл с номерами автомобилей, наложить на него 20 терабайт видео, чтобы найти на каких видео данные автомобили встречались и в какое время, а затем наложить сверху базу данных с расположением камер, снявших это видео, чтобы затем отобразить на карте любые их перемещения во времени. Пример придумал из воздуха, основываясь на десятках просмотренных видео (примеры ниже). Самому поработать с Palantir и увидеть это воочию, конечно, вряд ли вообще получится у кого-либо, кто читает это.
Существует пока в двух изданиях, названных в честь марвелловских городов — Palantir Gotham, ориентированный больше на работу с «человеческими» данными, типа профилей, баз данных, карт, итд., и Palantir Metropolis (бывший Finance), ориентированный на работу с большим количеством чиселок и буковок — финансовыми отчетами, логами серверов, и преисполненный суровым матаном. Судя по всему это просто два разных интерфейса к одному и тому же огромному вычислительному кластеру, который состоит из шести типов серверов: Dispatch Server — управляющий диспетчеризацией запросов, Revisioning Database — ключевая БД, основанная на Oracle 10g, Lock Server — отвечающий за блокировки в БД (отдельный сервер для этого, охуеть), Search Server — сервера поиска, вроде как модифицированный Apache Lucene, Configuration Server — отвечающие за конфигурацию и работу со всем кластером, Job Server — классические сервера для параллельных задач, используется модифицированная версия алгоритма MapReduce.
Окунувшись в историю, можно понять откуда растут корни такого метода работы с данными — на заре становления интернет-платежей, еще до краха доткомов, чуваки из PayPal тщетно пытались написать самые моднейшие и любимые всеми Машинные Обучения, чтобы автоматически вылавливать мошеннические транзакции в системе. Когда они поняли, что чем дальше они обучают систему новым трюкам, тем быстрее мошенники находят всё новые способы обхода глупых по своей сути компьютерных алгоритмов. И им пришло в голову то, что я давно и тщетно пытаюсь донести до примерно всех вокруг — большинство задач невозможно решить даже самыми мощными алгоритмами, нужна людская экспертиза. Но любую задачу можно автоматизировать. Тогда они придумали систему, которая сама выявляет хоть сколько-нибудь подозрительные паттерны поведения из миллиардов транзакций и выводит их на экран оператору, который уже принимает окончательное решение. Книжка Питера Тиля хвастается, что после введения такой системы, им за год удалось спасти от мошенников какие-то дикие десятки миллиардов долларов. На 100% верят книжкам «как стать успешным» только полные дегенераты, но судя по написанному всё пошло хорошо.
Потом, когда PayPal был успешно продан eBay, команда PayPal решила развить эту идею дальше. Как будто под руку случились теракты 11 сентября в Нью-Йорке, после чего было решено основным фокусом новой системы сделать правительственные расследования. Чуваки по сути сделали систему-убийцу, которая помогала ловить самых громких преступников, анализировать петабайты данных, выявляя финансовые манипуляции, и даже спасать людей после наводнения в Новом Орлеане.
Данные правят миром, особенно сейчас, когда этих данных у всех просто дикие количества. Вот только инструментов быстрой и визуальной обработки этих данных до сих пор не существует. Вы можете посадить 1000 программистов, чтобы они за месяц вам написали специфический софт, решающий одну конкретную задачу, а потом еще 1000 на другую, но это никуда не годится. В сердце Palantir — мощные базы данных, серьезные параллельные алгоритмы, написано всё это на Java, ставится на дикое количество серверов и, по заявлениям на официальном сайте, позволяет обрабатывать терабайты данных «за секунды». В качестве примера в презентации разработчиков приводится цифра — 500 млн снимков автомобильных номеров обрабатывается за 5 секунд. А ваш РНР-скрипт за 5 секунд капчу сгенерить не успевает.
Но мощность Palantir не в том, что он хуярит пиксели с килобайтами за секунды, а в том инструментарии, который он даёт человеку. По сути сам Palantir, как и Excel, ничего не будет сделать с данными, пока человек не запросит какое-либо действие. Он даёт инструментарий в руки человеку, чтобы тот, используя те аналитические способности своего мозга, которые еще не скоро смогут автоматизировать, мог из миллиардов записей найти те десятки тысяч, которые действительно важны. А затем наложить на них другую кучу данных, чтобы найти пересечения и скрытые связи, повторяя операцию вновь и вновь. Как в научно-фантастическом фильме типа «Особое Мнение» (разработчики, кстати, тоже использовали такое сравнение где-то). Всё это отображается в любом удобном для работы виде — граф, гистограмма или карта, которые еще и легко конвертируются между собой так, как вы это ожидаете. Для пояснения приложу несколько видео, кому интересно как это выглядит на деле.
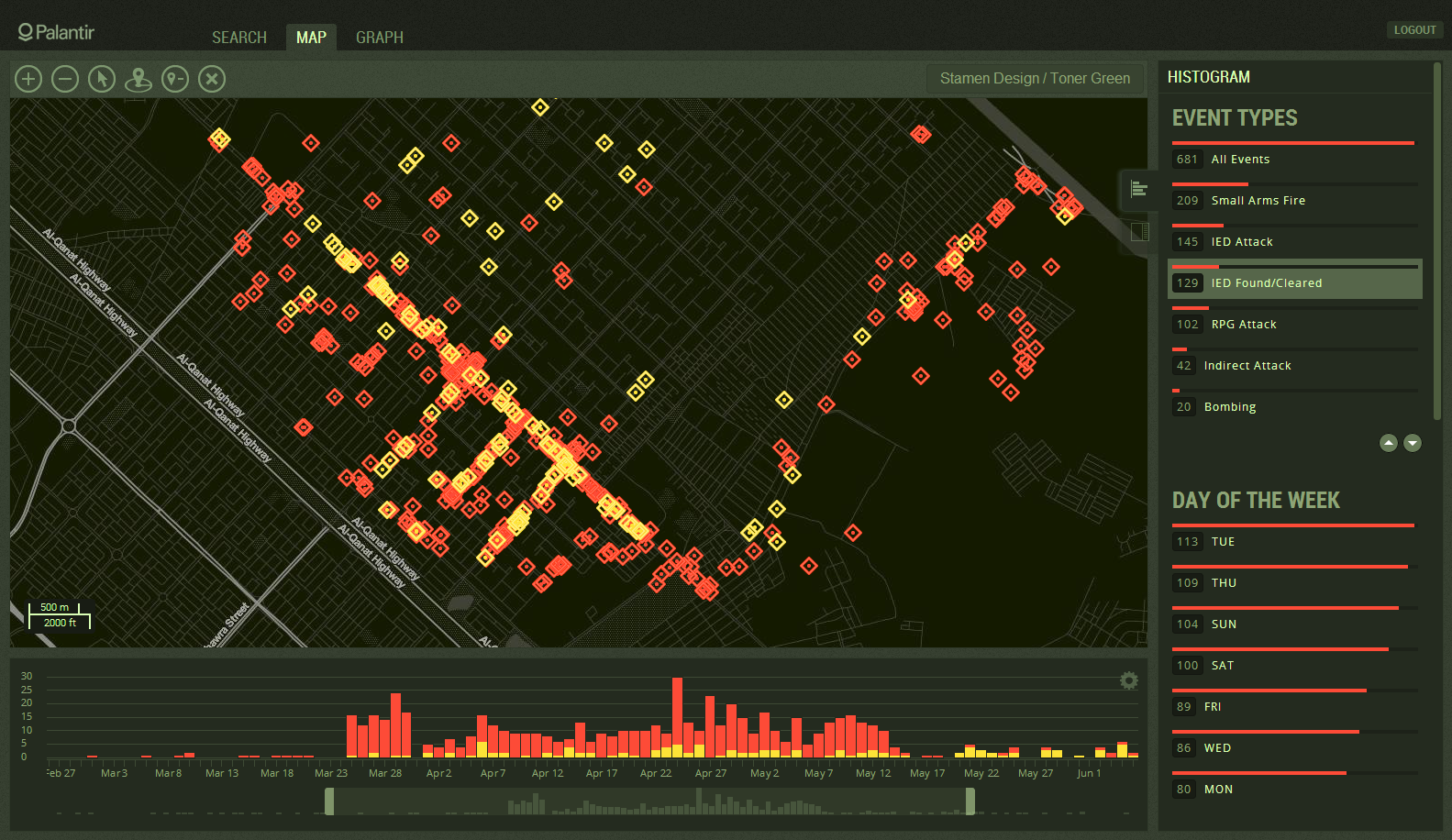
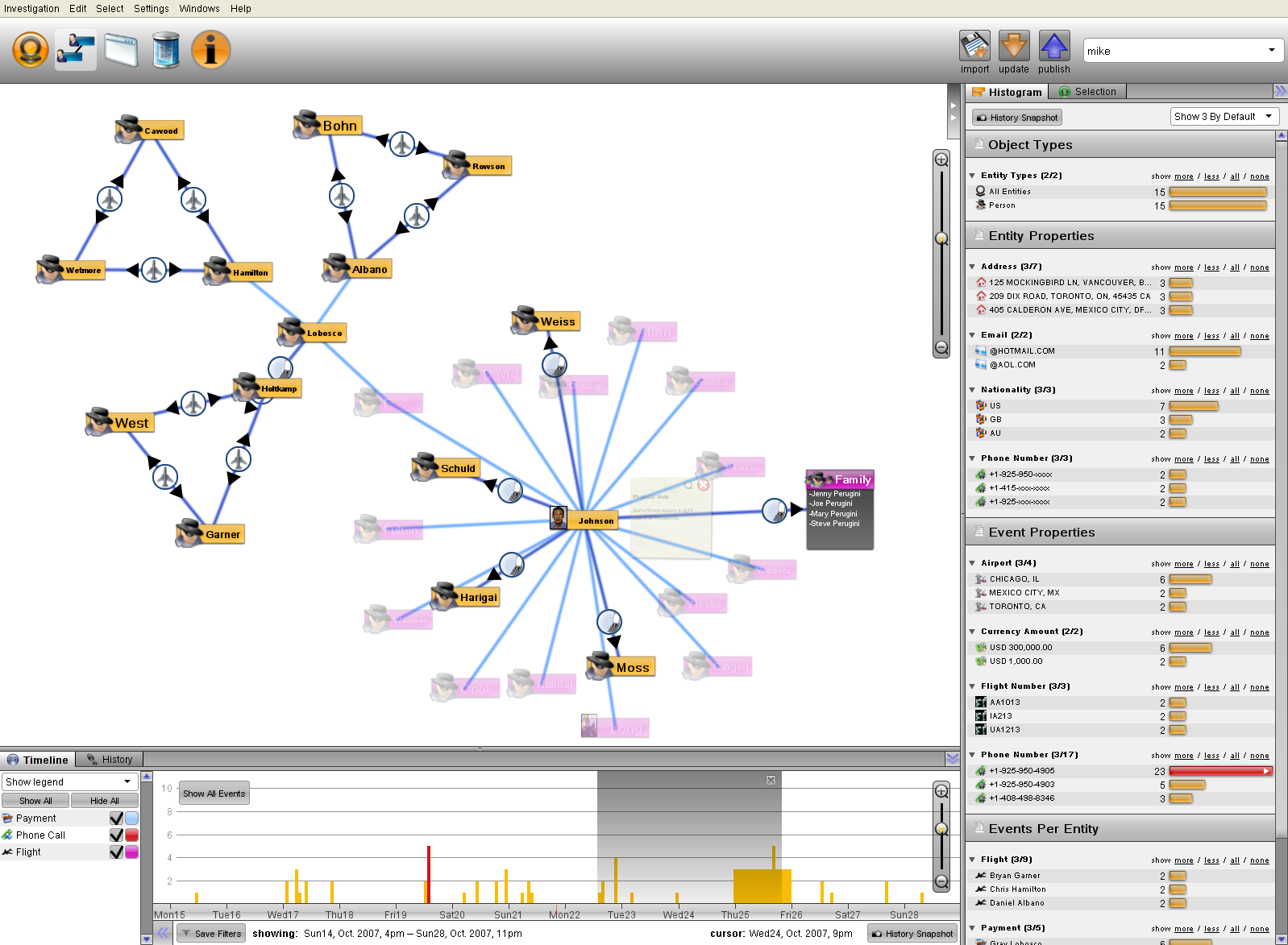
Когда я делаю подобные исследования, я обычно беру какой-нибудь Jupyter (бывший iPython Notebook), а потом ебусь со всякими pandas, scipy, matplotlib, пишу скрипты, чтобы «import csv, вот тут разбей по строкам, а вот тут… UnicodeDecodeError… ладна». На то, чтобы из неподготовленных данных получить хоть какую-то визуализацию, обычно уходят часы или дни, а мечтать о кросс-представлении этих данных в разных форматах даже не приходится. Palantir отменяет эти вымышленные компьютерщиками (sic!) форматы данных, для него любые данные — это одинаковые объекты. Если тебе хочется, ты можешь сравнить число и картинку, всё в твоей власти. Примерно каждая кнопочка в интерфейсе Palantir — это отдельный многомиллионный стартап.

Вдаваться в более маркетинговые подробности как они ловили Бен-Ладена и как сотрудничают с ЦРУ/АНБ не буду, мы тут программисты все, мы про технологии, нам насрать. Если интересно, то вот самая подробная (и без говна) статья на русском, что я нашел: http://www.3dnews.ru/621533
Вот статья на хабре, где много примеров и тотальные (типичные для хабра) ничего не понимающие уебаны в комментах: http://habrahabr.ru/post/262837/
А вот официальный сайт, который на редкость крутой и красивый (особенно на фоне интерфейсов самого Palantir), но незнающему человеку не дает понять вообще ничего: https://www.palantir.com/about/
Понравившиеся мне видео:
Как находят ботнеты:
Как вычисляют сливающих инфу организации:
Как ловят террористов:
Однако работать в Palantir, говорят, большая честь полный ад. Даже несмотря на все заявления на официальном сайте про «настоящую инженерную культуру», о которой так мечтает каждый гик, которую никогда не видел. Судя по всему это лукавство. Его сотрудники, помимо того, что получают достаточно невысокую для Bay Area з/п (около $127 тыс в год), еще и настолько обложены всякими NDA и всем этим, что никогда даже не разговаривают с другими жителями долины. Я бы так не смог.
Зато они делают реально крутой инструмент, который реально делает людей умнее, беря на себя хорошо получающиеся у машин операции, и отдавая людям операции, хорошо получающиеся у них — аналитику и принятие решений.
Показательно, что этот подход решает настолько серьезные и действительно полезные задачи, а не ваши «облака» с «бигдатой и машинлёрнигом», которые научились разве что таргетированный спам рассылать и холодильники рекомендовать.
Дискасс.
Расчехлил! Это же просто масштабы почти космические. Знал одного чувака, который заявил, что скоро программировать не надо будет. Интересно сначала было, потому градус неадеквата заоверфлоуил счетчик и теперь говорю о нем в прошедшем времени. До сих пор пугает скорым comming out своего "стартапа" (на самом деле нет). Мысль простая: автоматизация всего, кроме человеческого мозга - это охуенно. Все, что помогает деграднуть, во-первых убого, а во-вторых - вредно. Вообще это тренд - все хотят за тебя что-то сделать. Надо варп движки хуярить, автоматизовать транспорт, а они рекомендуют котиков, contextual ads, кавычки ставят. Причем это говно даже у гугла, который просто весь насквозь машинленинг. И еще эра социального говна должна пройти, либо качественно, кардинально измениться, чтобы быть продолжением мозга, а не заменой, например, ты еле-еле снова осваиваешь мыслить блобами длиннее 140 символов, а тебе твитор еще и рекламу хуярит, а гугл предлагает страпоны, потому что ты искал в картинках колбасу. А фейсбук шлет, как же долго ты не заходил. В здравом уме можно просто перестать все это делать, но если вдуматься, Карл, мы все заражены.
Первая часть напомнила почему-то вот это: http://geektimes.ru/post/268834/ А по сути хочу сказать, что такой софт наверно только для правительственных целей и создается, заполучить его в использование кем-либо кроме парней из этих самых органов наверное даже за ОЧЕНЬ большие деньги, практически нереально. Печалька что мы все под колпаком и если что любого вычислят по видосу с камеры у падика((
Да, эксель реально хорош, хоть некоторые элементарные вещи в нём делать несколько неудобно (фильтрацию одного массива по другому, например). Ты бы видел, что мой начальник в нём делает :) из него мог бы выйти неплохой разработчик, кстати. ну ты знаешь, толковый человек на многих фронтах молодец. Так, а что, годных альтернатив палантиру ещё нет? Насколько я понимаю, палантир же дата майнинг, то есть всё сводится к задачам "эту охуенную кучу данных хранить" и "быстро по ней искать". Мне кажется, таких средств уже полно, опять же, у большинства из нас ещё не такие объёмы, чтоб нужен был палантир. У вас там в плаге много гигов постгря? (картинки пока опустим, но о них я помню, да) У них там на сайте есть видос про защиту от кибер атак, который навёл на следующую мысль: Ок, получается отличный тул для защиты, почти как Губарев мечтал про "систему иммунитета" для компа, только для компа в сети. Однако, эта палка о двух концах, блэкхэты тоже однажды научатся использовать схожие тулы. Это бесконечный процесс, ты знаешь. Нет, я не против него, он двигает наши горизонты всё дальше и дальше. Может, за время, пока это произойдёт, мы всё-таки научимся строить космопорты.
LeaXDC, > И еще эра социального говна должна пройти, либо качественно, кардинально измениться Тоже, кстати, хорошая тема для обсуждения. Если этот пост хоть как-то привлечет дискуссию, можно будет устраивать такие посиделки время от времени :) ReDetection, > то есть всё сводится к задачам "эту охуенную кучу данных хранить" и "быстро по ней искать" Вычислительно почти любая задача программирования сводится к этому :) Пост скорее про сам подход — симбиоз человека и машины, от того тут и эксель как пример, как бы кто ни ненавидел эксель, на калькуляторе у него быстрее посчитать не получится. > понимаю, палантир же дата майнинг По определению даже написание SQL-запросов — это датамайнинг. Тут же всё дело в реализации и совокупности методов работы с данными. Лично я вижу достаточно мощную штуку у них — это загрузчик, который любые данные загружает и анализирует. Такого точно нет, в своем Jupyter я бы хотел только мечтать о таком, чтобы не постоянно import csv, import json, import Image, а оторваться наконец от представления данных и работать с самой информацией в них. А уж про то, как тяжко огранизовать даже 1 млрд вполне обычных записей в современной SQL СУБД и говорить не стоит, это до сих пор боль. > Однако, эта палка о двух концах, блэкхэты тоже однажды научатся использовать схожие тулы. Так это же описывает то, как и был придуман Palantir, я писал выше про историю с PayPal и мошенниками. Им легко было обойти любой алгоритм, однако Palantir снимает возможность что-либо «обходить», тут уже борьба мозгов людей, а не людей и машин, так что вот хуй знает. А у самих хакиров мощных тулзов вообще завались так-то. Так что да, это скорее: > бесконечный процесс, ты знаешь.
vas3k, > третий по стоимости стартап тут notes.app тоже постарался в ссылке > Пост скорее про сам подход — симбиоз человека и машины OК, да, здорово. Делать-то что-нибудь с этим знанием будем? Я не знаю подходящего инструментария. Вот у нас появился компьютер, и мы научились писать программы для него (и они уже даже преемптивны), но по-прежнему нужно их писать для каждой конкретной задачи. Так же как и чтобы быстро перемещаться из точки А в точку Б, нам нужен, например, автомобиль, и мы не можем его собрать за секунды, и есть разные автомобили для разных конкретных задач. Отличие автомобиля от компьютера заключается в том, что нет таких жестких ограничений физического мира — для написания программы не нужно наличие металла и много энергии, чтобы его гнуть и резать. А в компьютере — можем, но пока что данные хранятся в миллионах разных форматов и для каждого нужен свой кодек/программа обработки. Я к чему: мы пока умеем писать только программы для человека. Ну потому что мы их как-то пишем, они как-то по-разному выглядят, но человек с ними может работать только потому, что у него голова большая и он этой головой может подумать и адаптироваться. Мы не умеем договариваться и писать программы так, чтобы потом эти программы легко использовали другие программы, которыми пользуется человек. Даже, мне кажется, уровень не тот. Это должна быть операционная система a-la Palantir, в которой есть программы-источники, программы-фильтры, программы-представления, и пользователь может в секунды собрать себе. Как hurd, как sketch, как plan9 и линукс, но не текстовый. И даже мы с тобой n лет назад говорили, что было бы круто любой сайт воспринимать как API. Сейчас для этого есть kimono, но чуешь, как мы промахнулись с уровнем? Надо вообще всё воспринимать как API. И UI к этому нормальный. Программистов не станет не потому, что AI-программы будут писать другие программы, а потому, что пользователи смогут себе накидать любую программу за секунды.
ReDetection, > Делать-то что-нибудь с этим знанием будем? Ты спрашиваешь вопрос, а потом сам же на него отвечаешь экраном текста. Ты молодец :) Сия блогозапись не заходила так далеко, она была скорее моим криком души о том, как все вокруг пишут умные алгоритмы для тупых людей. Не спорю, таких большинство и у них тоже есть потребности, которые надо удовлетворять. Но я ищу полезные и умные инструменты для того вымирающего числа хоть немного старающихся мыслить человеков. И похуй, что они пока только у ЦРУ, важен сам факт, идея, концепция. А тут еще и коммерчески успешный пример, что редкость. Я полностью согласен с написанным тобой далее, просто это еще дальше развивает мою идею и действительно, как мы много лет назад обсуждали, что каждый сайт будет просто API, я до сих пор иногда об этом думаю. Про операционную систему даже думал, где-то видел прототип интерфейса операционной системы, где всё было представлено не в виде привычных файлов и папок, а в виде графа «данных» и работы с ним. Проект был какой-то мелкий хардварный, чуваки типа свой Raspberry Pi пилили, и судя по всему эти гики даже не поняли, что им надо не железку паять, а идею эту с графами развивать, можно было бы DE к линуксу такую написать как прототип. К сожалению, щас искал ссылку, не нашел. Переосмыслив просто подход к работе с информацией уже можно сделать охуенно, что сделал в свое время и Excel (давайте сделаем калькулятор на табличках), и Palantir в моем примере. Один из постов в моем «долгом ящике» как раз описывал пример мобильной ОС, в которой отсутствуют приложения и рабочий стол как класс (вдохновился когда-то на MWC год назад, не поверишь, убунтуфонами), может как-нибудь появится желание дописать. А вот на написание программами программ я всегда смотрел скептически, а вот идея с > программы-источники, программы-фильтры, программы-представления, и пользователь может в секунды собрать себе охуенная. Вот для этого я и писал пост и это как раз и ответ на вопрос "Делать-то что-нибудь с этим знанием будем?" :) Понятно, что вряд ли мы такие завтра обсудим это всё и запилим Next Big Thing, но для разминки мозга такие дискуссии полезны, даже просто читая комменты у меня уже 3 новые концепции появилось.
Последние два коммента напомнили философию близкую к горячим идеям Стивена Вольфрама, который обещал победить всех программистов своей супер-платформой, в которой ты не паришься ни про API, ни про визуализацию и интерфейсы, ни про то где это всё хранится и исполняется, а в итоге выкатил по сути продвинутый REPL и Wolfram Cloud.
Говно, вот мудила, да? Лучше бы свой набор фильтров для инстаграма или сервис по обмену видео-селфи замутил?
Нет, эмоциональная окраска немного другая (если бы я восторгнулся, то получил бы в ответ "да ну, я посмотрел, у них говно какое-то, а не будущее"), скорее про то как это сложно сделать, но мысли есть у нескольких Research подразделений, что радует и что логично, этот пост отлично вписывается. Может однажды и ты в подобной лаборатории, с кучей бесплатной дешевой рабочей силы типа студентов, запилишь настоящий некстген?
vas3k, приветствую! По сабжу - штука интересная... Почитаю ещё, как будет время. >По определению даже написание SQL-запросов — это датамайнинг. Я б так не сказал, data mining - перевод сырых данных в знание (извлечение качественно нового знания), а не просто извлечение данных из БД. Например, автоматом пройтись по чекам в магазине и выяснить наиболее часто сопутствующие друг другу товары - это уже дата-майнинг, а простой запрос с фильтром - нет. У меня вопрос (я здесь впервые): что это за ресурс и как можно зарегистрироваться для отслеживания новых записей (подписаться)?
Sorlak, > Я б так не сказал, data mining - перевод сырых данных в знание (извлечение качественно нового знания), а не просто извлечение данных из БД. Вот тут я не до конца понимаю. А если в запросе мы считаем среднюю сумму чека, то это же новое знание? То есть датамайнинг? > У меня вопрос (я здесь впервые): что это за ресурс и как можно зарегистрироваться для отслеживания новых записей (подписаться)? Просто мой блог. Регистрация не нужна, она от дьявола и грех! Подписаться по-олдскулу можно через <a href="http://vas3k.ru/rss/">RSS</a> или читать меня где-нибудь в <a href="http://twitter.com/vas3k">твиттере</a>/<a href="https://www.facebook.com/vas3k.ru">фейсбуке</a>. На <a href="http://vas3k.ru/">главной</a> под верхним меню много иконочек со всем этим добром.
vas3k, > Вот тут я не до конца понимаю. А если в запросе мы считаем среднюю сумму чека, то это же новое знание? То есть датамайнинг? Нет, имеются ввиду новые нетривиальные ("скрытые") знания, но доступные к интерпретации. Запрос средней суммы чека к дата-майнингу не относится. К дата-майнингу относятся задачи кластеризации, классификации, поиска логических связей (закономерностей), прогнозирования и т.д. >Просто мой блог. Регистрация не нужна, она от дьявола и грех! Подписаться по-олдскулу можно через RSS или читать меня где-нибудь в твиттере/фейсбуке. Спасибо! Подписался пока по старинке - через RSS.
Palantir поглотил Kimono :-(
themylogin меня опередил! Значит, ты тоже им пользовался и получил письмо? Надо срочно найти или написать аналог!
ReDetection, да, я еще до вас прочитал на хакерньюсе. А я наоборот порадовался за пацанов :) Можно написать, дыа.
ReDetection, у нас с пацанами ещё давно возникала идея сделать сервис по отслеживанию изменений на веб-страницах с оповещением. Kimono так и не удалось воспользоваться на наших кейсах (всё время какая-нибудь ошибка), найдены аналоги — import.io и parsehub.com, но в итоге всё стухло, потому что не смогли придумать, как пользователю отдавать нам свою авторизацию
themylogin, ну простые изменения можно на https://runscope.com проверять, я так за чужими API слежу
круто, а теперь давай чё-нибудь про крипты и майнеры со своей точки зрения.