≡
Статистика. Излюбленное поле для манипуляций всех, от ничерта в ней не понимающих, до корыстных профессионалов. Современные медиа, как недавно писал в своей колонке Илья Красильщик, «в полной заднице». Все наигрались с агрегаторами и объяснительной журналистикой, а гаджеты не менялись с выхода iPhone в 2007 году. Выходом из «задницы» сейчас они гордо видят «новые форматы», являющиеся по сути вариациями на тему «как обмазать рекламу интерактивными JS+CSS чтобы больше кликали», по ссылке выше весьма показательная точка зрения. Западные СМИшечки и эти развлечения переварили и выблевали, и теперь играют в снапчаты и тиндеры, чтобы хоть как-то продать себя «поколению миллениалов», пересказывая книги в формате интерактивных чатов. Это уже похоже на дно. Расцвет графомании и оглушительная победа синдрома дефицита внимания.
Основным из «новых форматов» зачастую выбирают красивенькую инфографику — это коротко, просто и легко шарится по соцсетям, откуда много трафика. Конечно, уже завтра какая-нибудь «медуза» кинется на какие-нибудь дейли-видео-стримы, попомните моё слово, но сейчас о текущем. Вчера мы смеялись над отправкой СМС в помощь участникам шоу Дом-2, а сегодня на Эхе Москвы решаем кто виноват в Сирии. Релевантность, форма распределения, случайность выборки, наводящие на ответ вопросы или оценка отклонений? Да кому это нужно, у нас тут Журналистика. Всё это давно побуждало меня написать пост про статистику.
Как я упоминал в пилотном эпизоде цикла «Информационное Поле», для многих статистика сродни алхимии и черной магии, что и позволяет любому так просто делать даже банальные манипуляции в этой области. На деле же статистика — это точная наука, которая одновременно весьма сложна и довольно проста. Проста тем, что её основные методы, которые и нужны простым людям и СМИ, разработаны лет 100 назад, а «самые передовые» из них не менялись уже десятилетия. Завтра не откроют меняющие всё гравитационные волны, а задачи статистики не входят в список неразрешимых задач тысячелетия. Сразу хочу оговориться, что здесь и в дальнейшем речь идет про базовый её раздел — описательную статистику (так как уже начали появляться комментарии «экспертов», желающих рассказать мне про нейросети и SVM).
 Сложна же она тем, что я бы вынес на первую страницу любого учебника — статистика не объясняет причинно-следственных связей. Статистика лишь может сказать, что данное распределение в определенных случаях имеет значимость с определенной ошибкой на определенной выборке, релевантность которой не всегда доказуема. То есть даже доказанная корреляция двух параметров не означает, что один зависит друг от друга. Возможно они просто оба зависят от третьего, упущенного параметра. Статистикой нельзя что-то с точностью доказать или с точностью опровергнуть, однако человечество может пользоваться ей чтобы выдвигать и проверять гипотезы, которые без нее были бы невозможны. Если они сработали — поздравляю, вы получили достижение «Двигатель Прогресса» и (например) изобрели пенициллин, пройдите на клетку человеческой эволюции вперед.
Сложна же она тем, что я бы вынес на первую страницу любого учебника — статистика не объясняет причинно-следственных связей. Статистика лишь может сказать, что данное распределение в определенных случаях имеет значимость с определенной ошибкой на определенной выборке, релевантность которой не всегда доказуема. То есть даже доказанная корреляция двух параметров не означает, что один зависит друг от друга. Возможно они просто оба зависят от третьего, упущенного параметра. Статистикой нельзя что-то с точностью доказать или с точностью опровергнуть, однако человечество может пользоваться ей чтобы выдвигать и проверять гипотезы, которые без нее были бы невозможны. Если они сработали — поздравляю, вы получили достижение «Двигатель Прогресса» и (например) изобрели пенициллин, пройдите на клетку человеческой эволюции вперед.
С другой стороны, просто поражает как едко любая информация, напоминающая статистическую и содержащая цифры, действует на наш мозг. Скажите молодой матери, что среднестатистический ребенок начинает ходить в год, и она на 11-й месяц изведет бедного поцана упражнениями, несмотря на среднее отклонение чуть ли не в пол года. Спросите у людей на улицах сколько лет их родителям и вы удивитесь насколько многие ответят круглую цифру типа 55-60-65, просто потому что не помнят точно. Но по прежнему в заголовки типа «86.4% питавшихся здоровой пищей людей добились успеха» хочется сразу поверить, не правда ли?

Статистика — это набор инструментов и вполне конкретных правил, которые говорят нам как правильно собирать, анализировать и делать выводы по данным. Во всех этих трех областях есть свои типичные ошибки, как намеренные, так и нет.
 Ошибки выбора. Выбор релевантной группы сродни искусству, а современные горе-социологи часто даже не заморачиваются с этим, проводя опросы просто по первым попавшимся каналам. Зачем заботиться о качестве выборки, если можно просто устроить голосование вконтакте или на своем сайте, где миллион леммингов кликнут на вариант ответа? Подобную ошибку допустил журнал Literary Digest в 1936 году. Опросив аж 10 млн своих подписчиков, журналисты сделали вывод, что что на выборах победит Альфред Лэндон. А победил Франклин Рузвельт. За неделю до публикации этого прогноза, молодой исследователь Джордж Гэллап обнародовал свои результаты, полученные в результате опроса всего лишь 5 тыс. человек, правда, в отличие от Literary Digest, подобранных на основе жестких критериев релевантности. Гэллап не просто предсказал победу Рузвельта, а так же точно угадал, какой прогноз опубликует Literary Digest. Несмотря на огромную выборку, ошибкой Literary Digest было непонимание того, что их подписчики, люди имеющие автомобиль и домашний телефон, чаще всего были из богатых слоев общества и в те времена воедино поддерживали Республиканскую Партию.
Ошибки выбора. Выбор релевантной группы сродни искусству, а современные горе-социологи часто даже не заморачиваются с этим, проводя опросы просто по первым попавшимся каналам. Зачем заботиться о качестве выборки, если можно просто устроить голосование вконтакте или на своем сайте, где миллион леммингов кликнут на вариант ответа? Подобную ошибку допустил журнал Literary Digest в 1936 году. Опросив аж 10 млн своих подписчиков, журналисты сделали вывод, что что на выборах победит Альфред Лэндон. А победил Франклин Рузвельт. За неделю до публикации этого прогноза, молодой исследователь Джордж Гэллап обнародовал свои результаты, полученные в результате опроса всего лишь 5 тыс. человек, правда, в отличие от Literary Digest, подобранных на основе жестких критериев релевантности. Гэллап не просто предсказал победу Рузвельта, а так же точно угадал, какой прогноз опубликует Literary Digest. Несмотря на огромную выборку, ошибкой Literary Digest было непонимание того, что их подписчики, люди имеющие автомобиль и домашний телефон, чаще всего были из богатых слоев общества и в те времена воедино поддерживали Республиканскую Партию.
Даже огромный размер выборки не страхует от ошибок, потому говорить о релевантности «соцопросов в интернете» или «опросов на улице» — намерено обманывать себя. И это лишь один способ манипуляции с выборкой. А их еще множество: Ошибка техасского стрелка, Ошибка Выжившего, Парадокс Берксона и другие систематические ошибки отбора.
Ошибка среднего. Любимый приём маркетологов и продавцов — правильно выбирать «среднее». Ведь их так много: среднее арифметическое, медиана, мода, а самые хитренькие даже могут завуалировать математическое ожидание. Среднее, медиана и мода действительно могут иногда совпадать, однако фразы типа «средняя зарплата по рынку» не имеют никакого смысла без указания какое именно среднее используется, так как зарплаты по рынку не подчинены нормальному распределению (точнее биномиальному, но не будем углубляться). А в жизни, особенно в экономике, очень много «перекошенных» распределений, на которых «средние» значения могут отличаться в разы и выбираться в зависимости от корыстных желаний продавца.
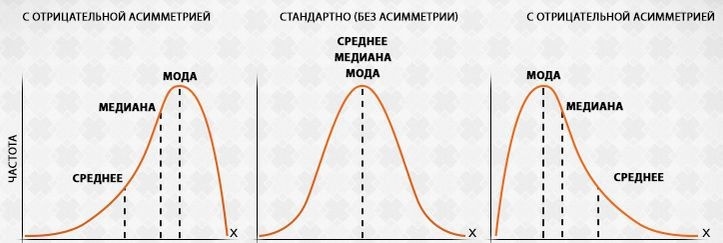
Ошибки анализа отклонений. Даже если автору удалось правильно сделать выборку, не ошибиться в подсчете средних значений, то практически всегда забывают посчитать ошибки и средние отклонения. Ведь автор уже проделал огромную работу, и не хочет чтобы какая-то выдуманная дисперсия математически доказала несостоятельность всего его исследования. Ему проще спрятать подальше исходные данные и скорее показать миру «впечатляющие результаты». Так что если видите анализ выборок без подсчета ошибок и отклонений, или ссылок на «сырые» данные — скорее всего вы читаете преднамеренную ложь.

Ошибки выводов о значимости. Даже когда и выборка сделана правильно, и ошибки посчитаны, и графики показывают заметную тенденцию, можно совершить последнюю и самую важную ошибку — сразу же подтвердить первоначальную гипотезу потому что «ну вот на графике же всё видно». Статистика, будучи точной наукой, не допускает таких формулировок, и переход от найденой корреляции к выдвижению гипотезы велит осуществлять строго по Критериям Значимости. Другими словами, даже «очевидный» тренд может банально не доказывать ничего. Быть статистически незначимым, и хоть ты тресни. Но это уже настоящий хардкор. Никто так глубоко не заходит, так что смело используйте «статистическую значимость» для любой демагогии в интернете.
И это всё лишь математические ошибки. Я уже молчу о целом поле методологических манипуляций, как формирование мнения в формулировке вопроса («Как патриот своей родины, согласны ли вы...»), наводящие ответы («Я хочу чтобы сайт развивался, потому согласен смотреть рекламу») или же намеренное ограничение выбора. А ложные выводы просто повсеместны: исследование показывает рост зарплат населения (ага, и игнорирует инфляцию), сравнение зарплат программистов России и США (при полном игнорировании стоимости жизни, налогообложения и индекса покупательской способности валют), и так далее.

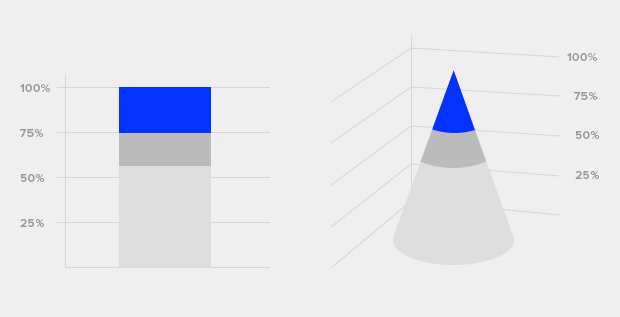
3D фигуры. Популярный способ представить «неудобные» данные в «правильном» ключе, чтобы читатель не задумываясь сделал нужные выводы. Все эти конусы, 3D pie-chart'ы, схематические изображения «количества» или «объема ВВП». Короткий совет здесь может быть такой: если вы не находитесь в начале 00-х и визуализации Excel 97 не являются вершиной визуализации, увидев трехмерную инфографику или же двухмерное представление простых числовых величин (например количество обозначено кружочками) — напрягитесь. Случаи действительной необходимости увеличения размерности настолько редки, что зачастую это яркий звоночек, что вся статья — банальная манипуляция. А в западных СМИ трехмерные графики и схематические изображения уже считаются моветоном и пережитком дешевых таблоидных иллюстраций прошлого века. Примеры ниже.
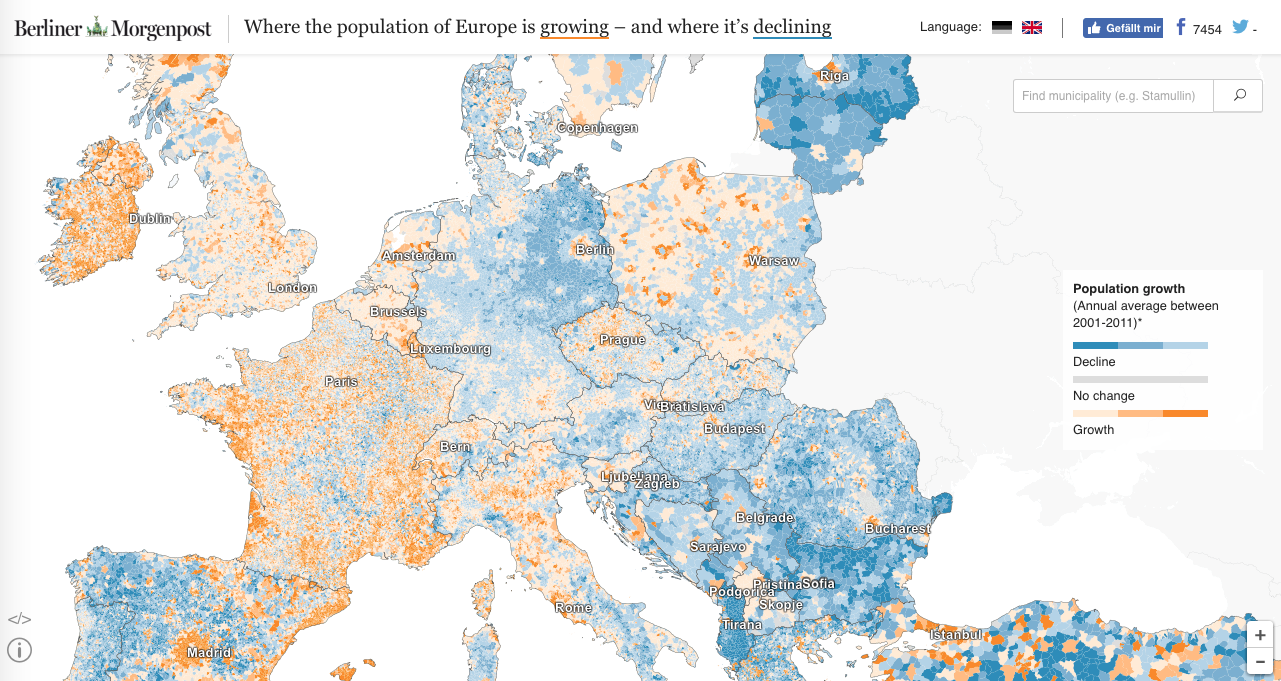
Нанесение данных на карту. Схожая с предыдущим, но настолько часто используемая манипуляция, что заслуживает отдельного упоминания. Заключается в том, что данные о «процентах» или «плотности» наносятся на схематическое изображение карты страны или планеты. Зачастую эта визуализация оказывается либо простой картой плотности населения в данной точке, либо вводит в заблуждение крупными размерами низконаселенных регионов. Часто так любят делать с данными голосования по штатам/областям или картами активных пользователей.
Есть несколько визуализаций на эту тему по выборам России, можно полистать и поискать эти феномены там.
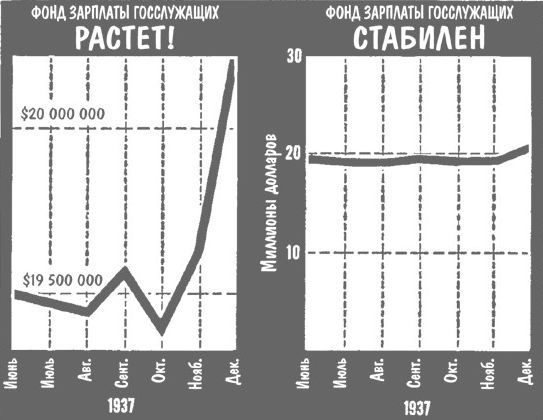
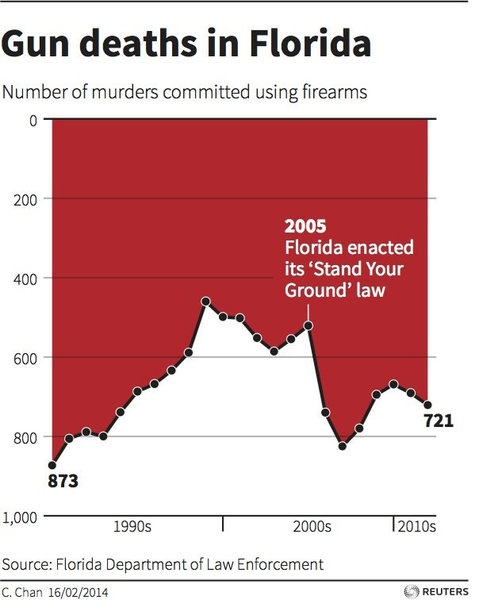 Манипуляции со шкалой. А вот это уже любимый способ манипуляции чуть более «прошаренных» медиа. Начинать шкалу не от нуля, рисовать деления разного размера, использовать относительную шкалу где нужна абсолютная и наоборот, совмещать на графике несколько масштабов, ну и высший пилотаж — перевернуть шкалу наоборот. Отдельного внимания заслуживают примеры объединения совершенно разных данных на одном графике. Рисуем два монотонно возрастающих параметра в одних осях координат и даже наш глаз начинает верить в зависимость между ними.
Манипуляции со шкалой. А вот это уже любимый способ манипуляции чуть более «прошаренных» медиа. Начинать шкалу не от нуля, рисовать деления разного размера, использовать относительную шкалу где нужна абсолютная и наоборот, совмещать на графике несколько масштабов, ну и высший пилотаж — перевернуть шкалу наоборот. Отдельного внимания заслуживают примеры объединения совершенно разных данных на одном графике. Рисуем два монотонно возрастающих параметра в одних осях координат и даже наш глаз начинает верить в зависимость между ними.
 Газета «Деловой Петербург» и биржевые индексы. На картинке смешно исключительно ВСЁ
Газета «Деловой Петербург» и биржевые индексы. На картинке смешно исключительно ВСЁ
Ложная корреляция. Все помнят классическую картинку «влияние количества пиратов на глобальное потепление». Ложные корреляции встречаются повсеместно даже там, где авторы не делали это с корыстной целью. Как я говорил во введении, статистика не описывает причинно-следственных связей, потому зачастую корреляция является лишь плодом воображения авторов и читателей, которые введены в заблуждение ложной иллюзией причинно-следственной связи. Каждый раз видя два одинаково идущих графика, спрашивайте себя, а может существует третий параметр, от которого зависят эти. Тогда ваши пираты не будут виновниками глобального потепления.
 Парадокс Симпсона. Если выше были банальности, напоследок пройдемся по хардкору. Существует парадокс, согласно которому когда вы собираете и отображаете статистику по нескольким группам данных, зависимость может оказаться абсолютно противоположной. Редко кто обладает достаточным умом и сообразительностью, чтобы использовать этот парадокс намеренно, однако его часто допускают в научных исследованиях, случайно искажая зависимости. Вот вам пример как легко доказать, что курящие люди живут не только счастливее, но и дольше некурящих.
Парадокс Симпсона. Если выше были банальности, напоследок пройдемся по хардкору. Существует парадокс, согласно которому когда вы собираете и отображаете статистику по нескольким группам данных, зависимость может оказаться абсолютно противоположной. Редко кто обладает достаточным умом и сообразительностью, чтобы использовать этот парадокс намеренно, однако его часто допускают в научных исследованиях, случайно искажая зависимости. Вот вам пример как легко доказать, что курящие люди живут не только счастливее, но и дольше некурящих.
Красивый парадокс из области статистики, заключающийся в мысленном эксперименте над спящей красавицей, которой делается укол снотворного и бросается монетка. В случае выпадения орла её будят и эксперимент заканчивается. В случае решки: её будят, делают второй укол (после чего она всё забывает) и будят на следующий день, уже не бросая монеты. Вся эта процедура Красавице известна, однако у неё нет информации, в какой день её разбудили — первый или второй. Представьте себя на месте красавицы. Вас разбудили. Какова вероятность того, что монета упала решкой?
У парадокса два ответа — 1/2 и 2/3, можете пройти по ссылке на википедию за объяснениями. Его красота заключается в том, что одно из решений является правильным по причине, что у красавицы недостаточно информации для построения полной картины мира (из-за снотворного). Парадокс показывает нам как мы можем даже математически придти к разным правильным ответам в зависимости от того, владеем ли мы полной информацией или нет.
 Тема весьма обширна, потому книг на этот раз много. Первая тоненькая и простая. Для тех, кому хочется почитать похожий на этот пост, но с подробностями и страниц на 100. Книга популярна в интернете, в ней много примеров реальных историй манипуляций, которые можно даже приспособить в жизни. Подходит для тех, кому не хочется погружаться в дебри матана, но истории послушать хочется.
Тема весьма обширна, потому книг на этот раз много. Первая тоненькая и простая. Для тех, кому хочется почитать похожий на этот пост, но с подробностями и страниц на 100. Книга популярна в интернете, в ней много примеров реальных историй манипуляций, которые можно даже приспособить в жизни. Подходит для тех, кому не хочется погружаться в дебри матана, но истории послушать хочется.
Не удивляйтесь названию. Эта книга стала для меня той, которую я нашел случайно, прочитал и понял всё что мне все эти годы рассказывали в универе. Подходит тем, кто уже действительно хочет не перенапрягаясь навсегда разобраться в среднеквадратичных отклонениях и критериях хи-квадрат. Читается не быстро, но вся информация в ней настолько хорошо и без лишних «теорем» описана, что лучше я еще не нашел. И неважно, что автор писал ее для своих студентов-медиков. Сложные статистические методы в ней объяснены на пальцах и популярных примерах типа «мы прилетели на марс и измерили рост марсиан», а медицинские примеры поймет любой, смотревший сериал про Доктора Хауса. Особенно стоит обратить внимание тем, кто весь такой программист и хочет в Data Mining. Он по сути на этом основан.
Рекомендуемая не только мной, но и половиной интернета — Фрикономика. Для многих из тех, с кем я общался — это азбука. Кто не читал — must have. Даже не как учебник или история, а как гайд по выживанию в мире. Прям удивительно, как людей после «Фрикономики» (и еще пары книг, о которых уже не в рамках этой статьи) меняется отношение к брендам, экономике и жизни вообще. И мне кажется, что в лучшую сторону. Если бы я был омерзительным блогером, который пишет модные колонки типа «25 книг, которые надо прочитать до 25 лет», она точно была бы там. Хоть и не на первом месте. У книги, кстати, есть продолжение — Суперфрикономика. Его не читал.
 Огромный отчет всемирного экономического форума (надо кликнуть Download PDF справа), собравший в себе очень много данных по конкурентоспособности по всем странам мира. Весь прочитать, естественно, невозможно, а составить картину интересующих стран — подойдет. Посмотреть какие сферы где развиты или у кого какие проблемы с точки зрения ведения бизнеса (высокие налоги или коррупция). Однако некоторые аспекты весьма странны. Например как Литва, планомерно переезжающая в Лондон и ничего кроме коровок и молочка уже не производящая, может быть конкурентоспособнее, например, Италии?
Огромный отчет всемирного экономического форума (надо кликнуть Download PDF справа), собравший в себе очень много данных по конкурентоспособности по всем странам мира. Весь прочитать, естественно, невозможно, а составить картину интересующих стран — подойдет. Посмотреть какие сферы где развиты или у кого какие проблемы с точки зрения ведения бизнеса (высокие налоги или коррупция). Однако некоторые аспекты весьма странны. Например как Литва, планомерно переезжающая в Лондон и ничего кроме коровок и молочка уже не производящая, может быть конкурентоспособнее, например, Италии?

Небольшая PDF'ка евростата, на каждой странице которой сжато представлены ссылки на основные статистические измерения по ЕС за последний год. Особый интерес представляют не только визуализации, но и сырые данные, с которыми можно поиграть с ними самому.
Что-то я всё про плохое да про плохое. Надо и хорошие примеры приводить же. На которые стоит опираться. И, как вы понимаете, эти примеры далеко не из России. Bleeding Edge всё-таки не здесь. На этот раз вот вам просто золотая ссылка на гитхаб, где собирают лучшие примеры статей, ссылки на журналистов и действительно годные портфолио мировых изданий. Если вы в этой теме, то пара часов на изучение вам гарантирована: https://github.com/wbkd/awesome-interactive-journalism.
По всей статье: сначала было интересно читать, когда было про реальный мир, а потом ты скатился на банальности и на конспект по книжечке. Не делай так! Пиши про реальный мир, прикольно выходит.
buriy, благодарю, вот это хороший фидбек. Я всё еще не могу определиться с информативностью и подачей. Нащупать грань, так сказать, между «конспектом лекции» и «безинформативным весельем». Потому все три выпуска я специально писал немного в разных стилях и форматах и смотрел за реакцией. Появилась некоторая пища для размышлений, но конкретных выводов пока не сформировалось. Буду думать, возможно отложу немного следующий пост, хотя в планах они расписаны уже до шестого. Жду еще отзывов, они помогают.
А я наоборот считаю, что введение было водянистым, а конспект с картинками и примерами - самая мякотка, ради которой стоит читать. Я в восторге от того, как изменился стиль твоих текстов - больше никаких наездов и матов не в тему. Буду давать ссылку на этот пост всем непонимающим статистического надувательства.
vas3k, предлагаю написать "среднее*", а внизу сноску, что это среднее арифметическое. А то весь предыдущий абзац был посвящён тому, что слово "среднее" - чистейший буллщит и надо отличать медиану от моды и от среднего арифметического, и тут на тебе - "среднее" на графике.
Да, не раз замечал, что в литературе общепринятой практикой является называть его просто "среднее". Даже в английской, где "arithmetic mean" сокращают до "average". Банально - математики любят сокращать записи до минимума. А так сокращается, потому что медиану и моду, которые назвали медианой и модой имеют только одно одно значение. Про формат постов - очень клёво, респект. Как доработать даже не знаю, мне в общем-то все понравились. Возможно, есть смысл чередовать стили в зависимости от тематики, ну или просто случайным образом, чтобы было интереснее?
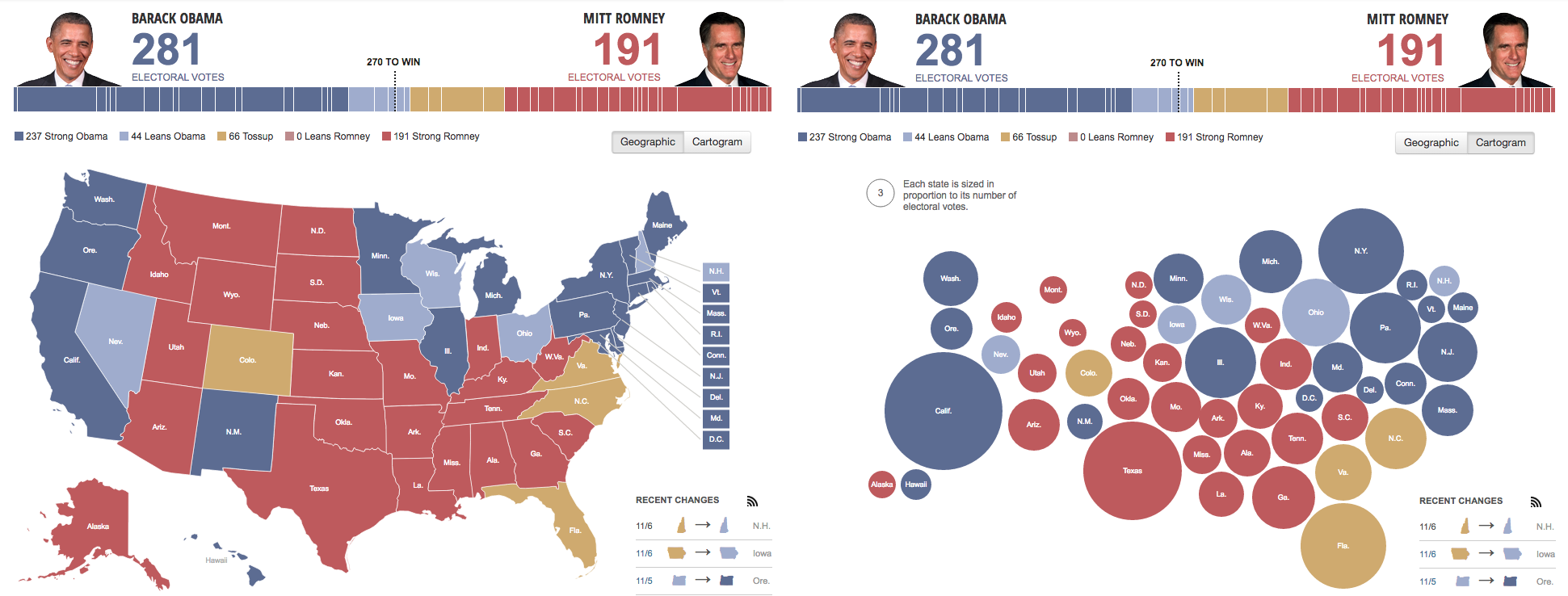 А вот Huffington Post, например, не оплошал и сделал переключалку, на этом примере хорошо видно насколько отличается восприятие данных на карте и без нее
А вот Huffington Post, например, не оплошал и сделал переключалку, на этом примере хорошо видно насколько отличается восприятие данных на карте и без нее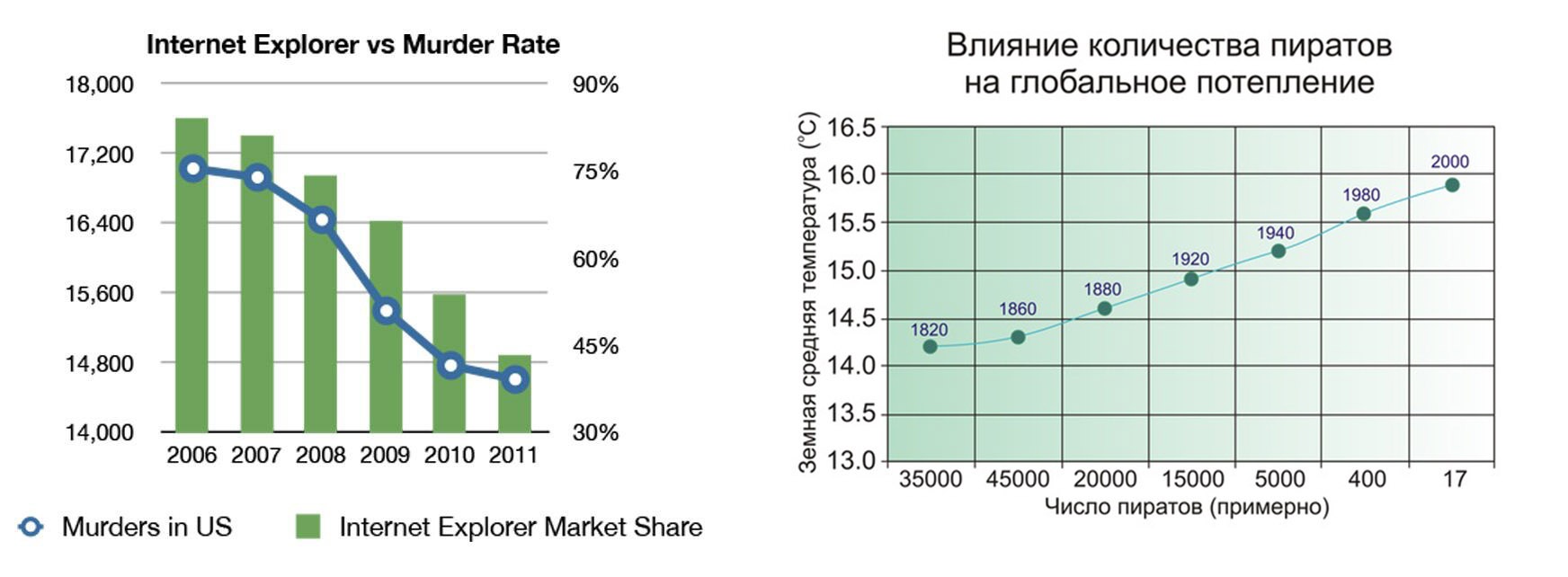 Мои любимые, конечно
Мои любимые, конечно
а у меня СДВГ клинически диагностирован :)
Hanggard, я так понимаю такую ачивку несложно заработать. Этож default-диагноз на случай "вроде здоров, но какой-то ебанутый, справка нужна". Мне такие же ставили, но в других областях :)
ппп
ни_черта