≡
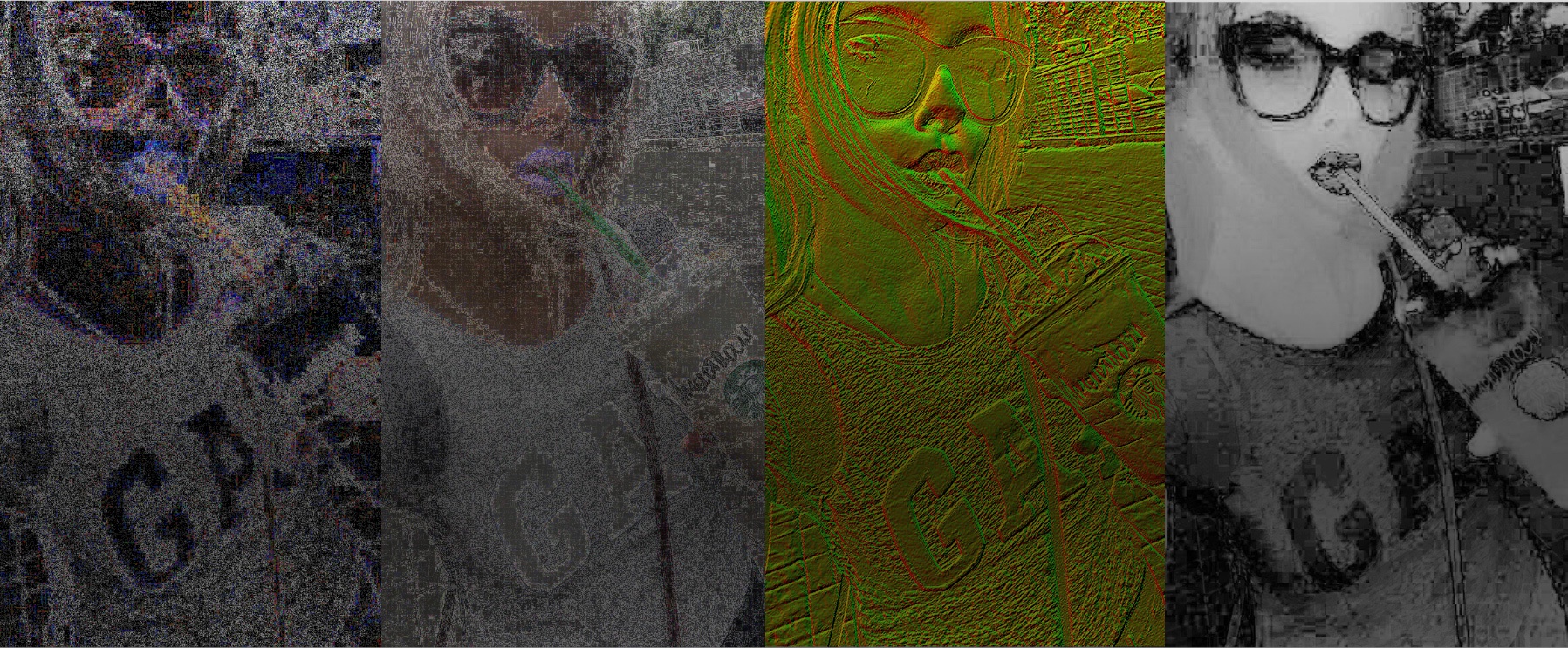
В 1855 году пионер портретной фотографии Оскар Рейландер сфотографировал себя несколько раз и наложил негативы друг на друга при печати. Получившееся двойное селфи считается первым фотомонтажом в истории. Наверное лайков тогда собрал, уух...
Теперь же каждый подросток с фотошопом, смартфоном и интернетом сможет даже лучше. Правда чаще всего эти коллажи неимоверно доставляют. А вот профессионалы научились скрывать свою работу весьма качественно. Это был вызов.
Совокупность методов анализа модифицированных изображений назвали Image Forensics, что можно перевести как «криминалистика изображений». В интернете существует куча сервисов, заявляющих, что они за два клика помогут определить подлинность фото. Особенно доставляют самые тупые, которые идут смотреть EXIF и если там нет оригинальных метаданных камеры начинают громко вопить «вероятно фото было модифицировано». И про них даже в New York Times пишут (а про тебя нет).
Я пересмотрел около десятка сервисов и остановился на одном: Forensically. В нём реализовано большинство описанных в статье алгоритмов, я буду часто на него ссылаться. Все описанные методы названы оригинальными английскими названиями, чтобы не было путаницы.
Однако возможность загрузить свою фотку в какой-то сервис и посмотреть на красивые шумы не сделает из вас сыщика. Поначалу может быть трудно и непонятно, а первые эксперименты точно окажутся неудачными. У меня так же было. Тут как в спорте — нужен намётанный глаз и опыт как должно и не должно быть. Умение не просто смотреть на шумные картинки, а видеть еле заметные искажения в них.
Не существует 100% метода, позволяющего определить фейк. Но есть человеческие ошибки.
Найдет самые глупые косяки
Главный инструмент — наши глаза. Так что первым делом стоит открыть фото в любимом графическом редакторе или просмотрщике, поставить зум в 1000% внимательно втыкать в предположительное место монтажа. С этого начинается любой анализ. Чем более неопытный монтажер попался — тем проще будет найти косяки, артефакты и склейки. Иногда фейки настолько кривые, что можно нагуглить оригинал используя поиск по изображениям или заметив несоответствия в EXIF.
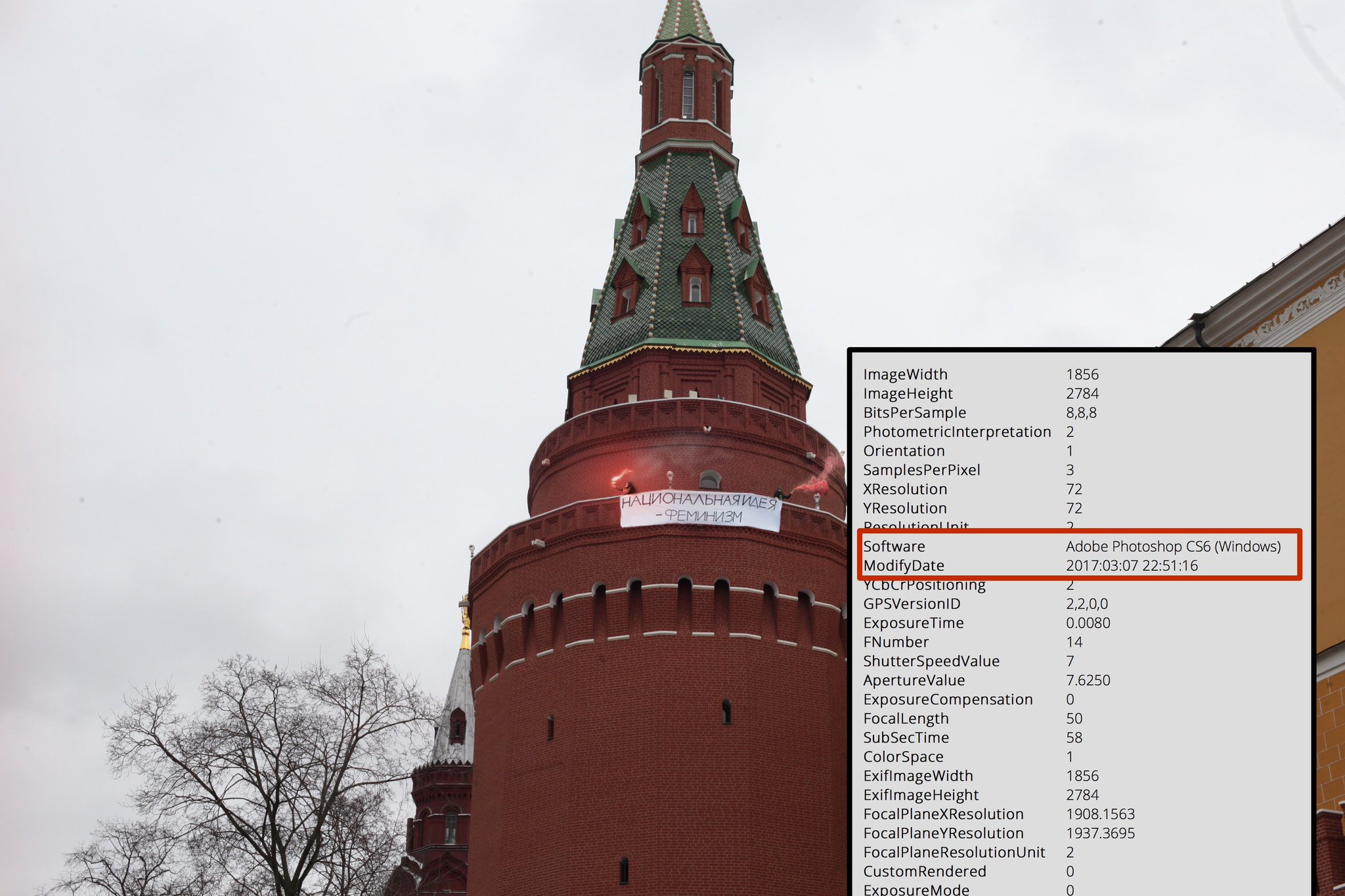
Помимо этого, в любом уважающем себя редакторе есть инструменты для цветокоррекции. В Preview.app на маке они спрятаны в меню Tools > Adjust Color... Вытягивание различных ползунков поможет лучше разглядеть детали.
Brightness and contrast. Сделать темные области ярче, а яркие темнее. Теоретически поможет лучше разглядеть артефакты, склейки и другие места, которые неопытный фотошопер просто замазюкал темненьким и посчитал, что не заметят.
Color adjustment. Увеличивая насыщенность или яркость разных цветов, можно заметить неестественные переливы и границы склейки.

Invert. Часто помогает увидеть скрытую информацию в однотонных объектах.
Sharpen and blur. Добавление резкости поможет прочитать надписи на табличках, есть целые сервисы, которые могут побороть заблюренные области.
Normalization and histograms. Работа с гистограммой по сути объединяет сразу несколько методов в один. Если вы прошарены в графике — гистограммы будут серьезным оружием.
Даже если определить фейковость сразу не удалось, у вас уже могли появиться полезные наблюдения, чтобы перейти к следующим методам с страшными математическими названиями.
Найдет свежую кисть, деформацию, клонирование и вставку чужеродных частей
Реальные фотографии полны шума. От матрицы камеры или фотосканера, от алгоритмов сжатия или по естественным природным причинам. Графические редакторы же этот шум не создают, их инструменты живут в «идеальном мире», потому чаще всего «размазывают» шум оригинального изображения. Кроме того, два изображения чаще всего обладают разной степенью зашумленности.

Заметить шум глазом не так-то просто, но можно взять любой инструмент Noise Reduction и инвертировать его действие, оставив от фотографии только шум. Хорошо работает для свежеобработанных изображений и в случаях, когда автор решил, что нашел очень подходящие на вид изображения. Но легко обманывается, если знать как.
Поиграть самому можно здесь.
Добавить своего шума. Самый очевидный вариант. Хочешь скрыть свои косяки — навали на фото столько шума, чтобы забить оригинальный.
Пережать JPEG. Уменьшение качества изображение в два раза делает шумы неразличимыми (вот исследование).

Найдет свежие артефакты наложения изображений или текста
Каждый раз при сохранении картинки ваш редактор заново прогоняет её через кучу преобразований — конвертирует цвета, делит на блоки, усредняет значения пикселей, и.т.д. Он занимается этим даже если вы выбрали 100% качество при сохранении, так уж устроен алгоритм JPEG. Интересующиеся могут почитать про него глубокую статью полную косинусных преобразований.
Так как JPEG — формат сжатия с потерями, то при каждом сохранении растет количество математических усреднений, ошибок или более популярный термин — «артефактов». Два сохранения с 90% сжатием примерно эквивалентно одному с 81% по количеству этих самых артефактов. На практике это может принести пользу. Даже если зоркий глаз не видит разницы между 80% и 85% сжатием, то наверное есть инструменты, которые наглядно покажут это различие? Да, Error Level Analysis или ELA.
Фейки с наложениями чаще всего делают подыскав нужные изображения где-нибудь в гугле. Вероятность, что найденные изображения будут с одинаковым уровнем артефактов, ну, крайне мала. Социальные сети или даже специализированные хранилища фотографий всё равно пережимают изображения под себя при загрузке, чтобы не платить за хранение гигабайтов ваших селфи из отпуска. Обратное тоже верно — если вы накладываете на найденное в интернете изображение свежую фотографию со своей камеры, она будет заметно выделяться по качеству. Заметно не для глаза, а для ELA — он покажет разительно меньше артефактов на вашей новой фотографии.

Простота и известность делает ELA самым популярным методом работы мамкиных интернет-сыщиков, от чего его начинают пихать везде, где только могут. Как будто других методов просто не существует и ELA может объяснить всё. Тот же Bellingcat использует его чуть ли не в каждом втором своём расследовании. Хотелось немного остудить пыл всех услышавших новую умную аббревиатуру.
ELA — не панацея. Сфотографируйте летящую чайку на фоне ровного синего неба (ага, особенно в Москве), сохраните её в jpg и прогоните через анализатор ошибок. Результат покажет просто огромное количество артефактов на чайке и их полное отсутствие на фоне, из чего начинающие сразу сделают вывод — чайка прифотошоплена. Да что там начинающие, сама команда Bellingcat с этим бывало глупо и по-детски наёбывалась. Алгоритм JPEG достаточно чисто работает на ровных цветовых областях и градиентах, и куда больше ошибается на резких переходах — отсюда такой результат, а не из-за ваших домыслов.

Из-за растущей популярности Error Level Analysis я уже слышал призывы запретить и не принимать его всерьез. Не буду столь категоричен, лишь посоветую не бежать писать разоблачения, если ELA показал вам какие-то шумы на краях. ОН НЕ ТАК РАБОТАЕТ. Думайте головой и помните как JPEG устроен внутри. Вот если ELA очертил четкий квадрат там, где его не должно быть, либо заметил разительную разницу в шумах при неотличимости на глаз — наверное стоит задуматься. Не уверены — проверяйте другими методами.
Поиграть с ELA можно тут.
Много раз пересохранить. Все свои манипуляции алгоритм JPEG делает внутри блоков максимум 8x8 пикселей. В теории нужно 64 раза пересохранить изображение, чтобы уровни ошибок стали неотличимы друг от друга. На практике же это происходит гораздо раньше, достаточно пересохранить картинку раз 10 и ELA, да и некоторые другие методы, больше не увидят ничего полезного.
Изменить размер. Чтобы не напрягаться с пересохранением можно поступить еще проще — отресайзить изображение на какой-нибудь коэффициент не кратный степени двойки. То есть в 2 раза (50%) уменьшить не подойдет, а вот что-нибудь типа на 83% — уже всё, никакой ELA больше не поможет.
Смонтировать из одного источника или из lossless-формата. Вы сфотографировали двух людей на свой фотоаппарат, или скачали фотографии из какого-нибудь блога, где автор скорее всего пересохранял их всего раз-два. Либо наложили друг на друга две PNG'шки. Во всех этих случаях ELA не покажет ничего интересного.

Найдет ретушь, компьютерную графику, хромакей, Liquify, Blur
В жизни свет никогда не падает на объекты абсолютно равномерно. Области ближе к источнику всегда ярче, дальше — темнее. Никакого расизма, только физика. Если разбить изображения на небольшие блоки, скажем 3x3 пикселя, то внутри каждого можно будет заметить переход от более темных пикселей к светлым. Примерно так:
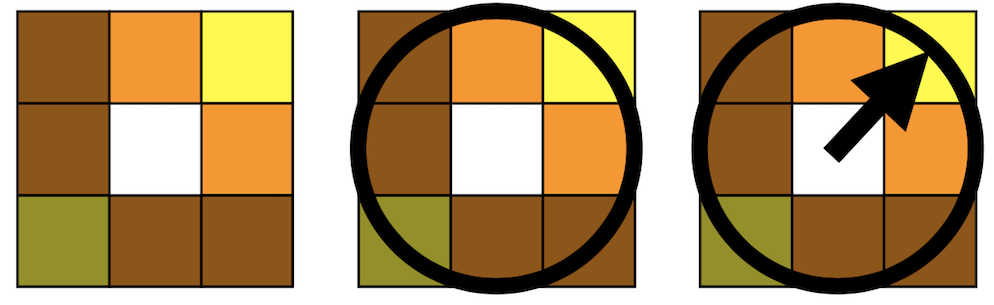
Направление этого перехода так и называется — градиент освещенности. Можно попробовать нарисовать кучу маленьких стрелочек на изображении и понаблюдать за их направлением.

На первом изображении свет падает сверху и стрелочки направлены хаотически — это характеризует рассеянный свет. Второе изображение — компьютерная графика, на ней свет падает слишком идеально, никаких шумов и отклонений как на настоящем фото. Третье изображение — фотография с резким переходом, в центре стрелочки массово смотрят в самую яркую сторону, а на фоне — рассеяны так же, как на первом фото.
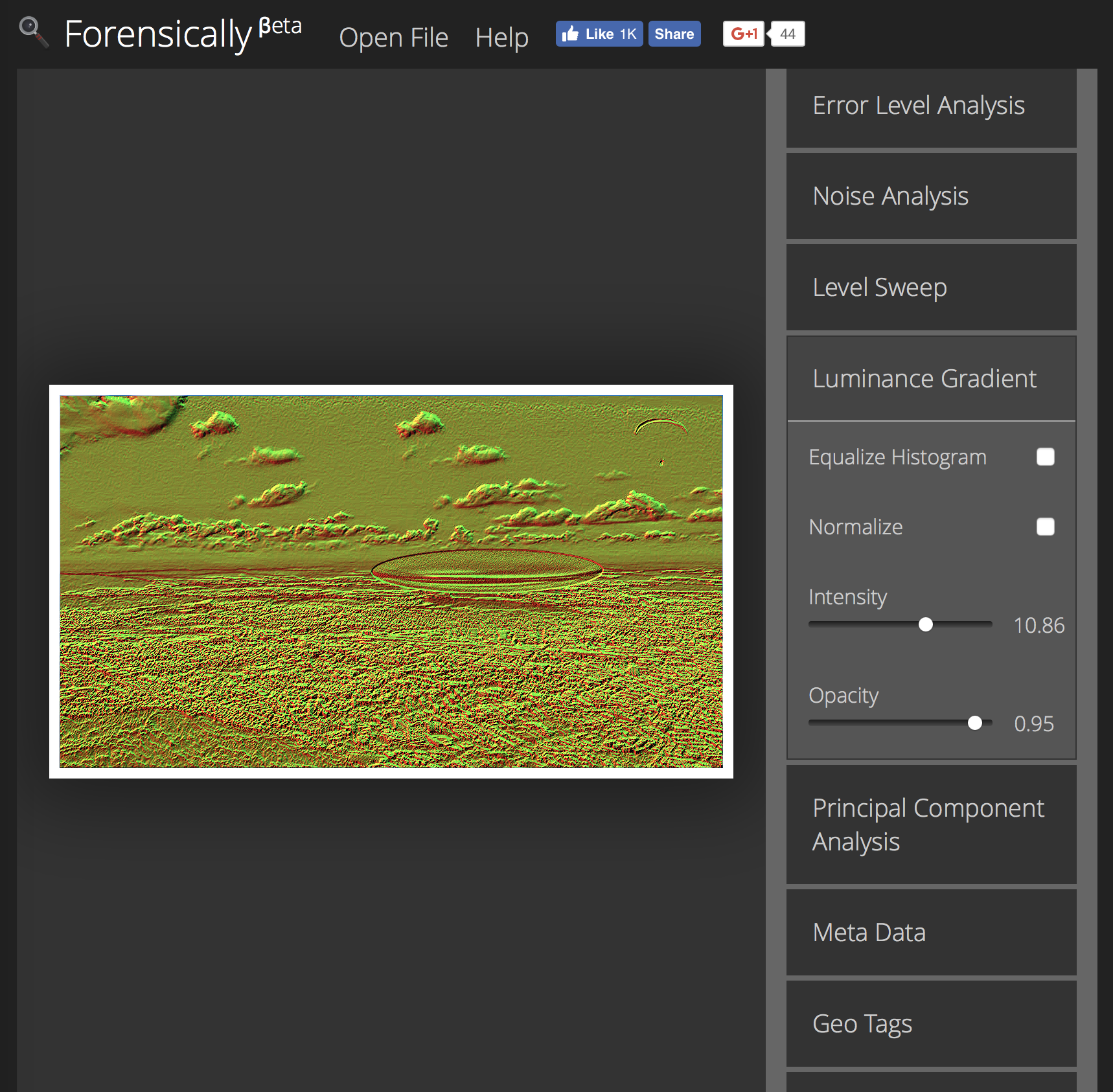
Рисовать стрелочки хоть и наглядно, но мы физически не сможем изобразить все градиенты освещенности для каждого блока поверх картинки. Стрелочки займут всё изображение и мы не увидим ничего. Потому для большей наглядности придумали не рисовать их, а использовать цветовое кодирование. Для направления вектора понадобится две координаты, и еще одна для его длины — а у нас как раз есть для этого три цветовых компоненты — R, G, B. В итоге получатся вот такие карты освещенности.

В реальной жизни нас окружает ограниченное число источников света. В помещении это лампы, вспышки, окна. В ясный день на улице чаще всего источник света только один — это Иисус, спаситель наш солнце. Если на карте освещенности находящиеся рядом объекты сильно отличаются по направлению падения света — у нас есть главный кандидат на монтаж.

Но еще лучше карты освещенности справляются с определением ретуши. Surface Blur, Liquify, Clone Stamp и другие любимые инструменты фотографов начинают светиться на картах освещенности как урановые ломы тихой весенней ночью. Нагляднее всего выглядит анализ фотографий из журналов или рекламных плакатов — там ретушеры не жалеют блюра и морфинга, а это непаханное поле для практики.
Лично я считаю карты освещенности одним из самых полезных методов, потому что он чаще всего срабатывает и мало кто знает как его обмануть. Поиграться можно здесь.
Не знаю. Говорят помогает изменение яркости и насыщенности цветов по отдельности, но на бытовых фотографиях такие вещи всегда будут заметны глазу. Если вы знаете простой и действующий метод — расскажите в комментах под этим абзацем, всем будет интересно.


Найдет копипаст, вытягивание и несоотвествие цветов, Healing Brush, Clone Stamp
Метод PCA или на русском «метод главных компонент». Чтобы ко мне не придрались, мол, слишком просто всё рассказываешь и наверное не шаришь, вот описание PCA для рептилоидов.
Метод главных компонент осуществляет переход к новой системе координат y1,...,ур в исходном пространстве признаков x1,...,xp которая является системой ортонормированных линейных комбинаций. Линейные комбинации выбираются таким образом, что среди всех возможных линейных нормированных комбинаций исходных признаков первая главная компонента обладает наибольшей дисперсией. Геометрически это выглядит как ориентация новой координатной оси у1 вдоль направления наибольшей вытянутости эллипсоида рассеивания объектов исследуемой выборки в пространстве признаков x1,...,xp. Вторая главная компонента имеет наибольшую дисперсию среди всех оставшихся линейных преобразований, некоррелированных с первой главной компонентой. Она интерпретируется как направление наибольшей вытянутости эллипсоида рассеивания, перпендикулярное первой главной компоненте. Следующие главные компоненты определяются по аналогичной схеме.
А теперь для людей: представьте, что цветовые компоненты R, G и B мы взяли как оси координат — каждая от 0 до 255. И на этом трехмерном графике точками отметили все пиксели, которые есть на нашем изображении. Получится что-то похожее на картинку ниже.
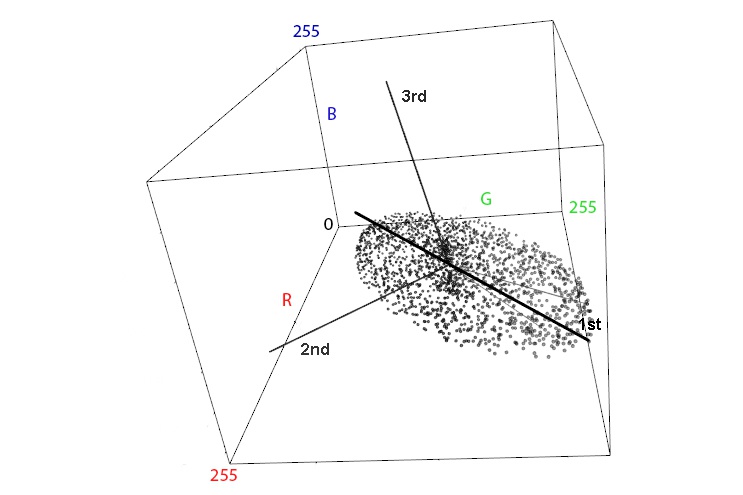
Можно заметить, что наши пиксели не рассосались по графику равномерно, а вытянулись в округлую колбасятину. Все реальные изображения так устроены, потому что science, bitches. Теперь мы можем построить новые оси — вдоль колбасятины (это самая главная) и две поперек — это и будут те самые «главные компоненты». Для каждого изображения набор цветов будет разным, колбасятина и главные компоненты будут направлены по-своему.
Так что вся эта математика нам дает? Дело в том, что если какие-то цвета на изображении стоят «не на своих местах» — они будут сильно выделяться из этого облака пикселей, то есть на карте PCA начнут светиться ярким белым цветом. Это может означать локальную цветокоррекцию или же полную вклейку. Диаграммы PCA может построить тот же Forensically. На них будет изображено расстояние от каждого пикселя картинки до плоскости 1, 2 и 3 главной компоненты. Так как расстояние — это число, то изображения будут черно-белыми.

Но еще более полезным свойством PCA является то, что он превращает JPEG-артефакты в очень заметные «квадраты». Даже если вы обманули ELA из предыдущего пункта пережатиями и ресайзом, то PCA этим не проведешь — он работает с цветом. Иногда артефакты сразу видно, например если исходное изображение увеличивали для вклейки. В других случаях сматриваться придется чуть более внимательно, чтобы заметить разницу в квадратах на изображении.
Как видно из примеров, PCA не очень наглядный и требует ну уж очень сильно присматриваться к таким мелким косякам, которые вполне могут оказаться случайностями. Потому PCA редко используется в одиночку, его применяют как дополнение к другим.
Самому поиграться можно здесь.
Заблюрить. Любой блюр смазывает соседние цвета и делает «колбасятину» более округлой. Хороший блюр сильно затруднит исследование по методу PCA.
Еще хитрее изменить размер. Хотя PCA и более устойчив к изменение размеров изображения, говорят можно попробовать подобрать такой процент, чтобы обмануть даже его.

Найдет различия в резкости, отклонения в фокусе, ресайз
Дискретное вейвлет-преобразование очень чувствительно к резкости объектов в кадре. Если фотографии сняты на разные объективы, использовался зум или просто немного отличалась точка фокусировки — после DWT эти отличия будут намного виднее. То же самое произойдет, если у какого-то объекта в кадре изменяли размер — резкость таких частей будет заметно ниже.
Без лишних погружений в теорию сигналов, вейвлет — это такая простенькая волнушка, как на картинке ниже.
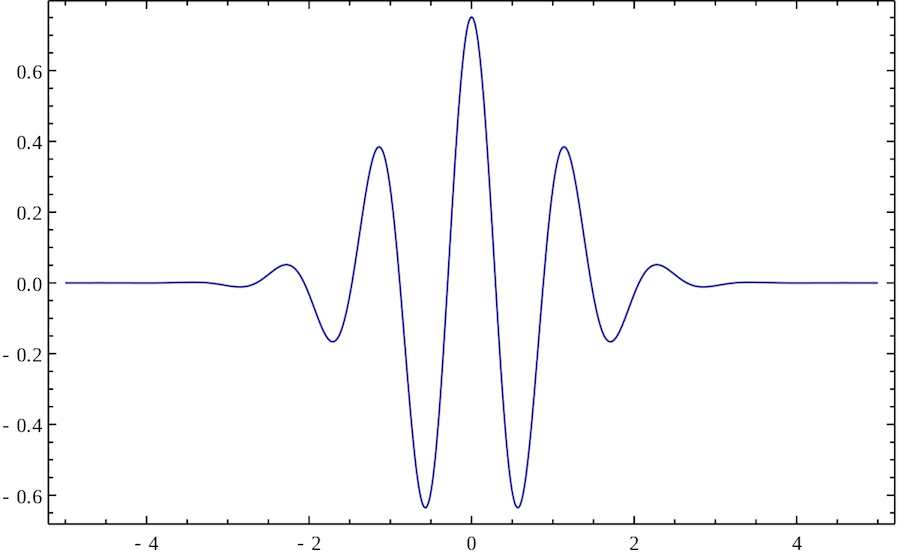
Их придумали лет 100 назад, чтобы приблизительно описывать аналоговые сигналы. Одну большую длинную волну представляли набором мелких вейвлетов, тогда некоторые её характеристики внезапно становилось проще анализировать, да и места чтобы хранить надо было меньше. На вейвлет-сжатии например был построен формат JPEG-2000, который к нашему времени (к счастью) сдох.
Картинка — это тоже двухмерный сигнал из цветных пикселей, а значит её можно разложить на вейвлеты. Для достаточно точного приближения изображения 800x600 требуется до 480000 вейвлетов на цветовой канал. Если уменьшать это количество — будет сильно падать резкость и цветопередача. Но что это даёт, кроме сжатия?
А вот что: вейвлеты приближают области с разной резкостью по-разному. Чем плавнее переходы — тем проще плавному по своей природе вейвлету его воспроизвести, а чтобы приблизить резкий переход — надо больше вейвлетов. Это как пытаться сделать из кучи шариков идеальный куб.
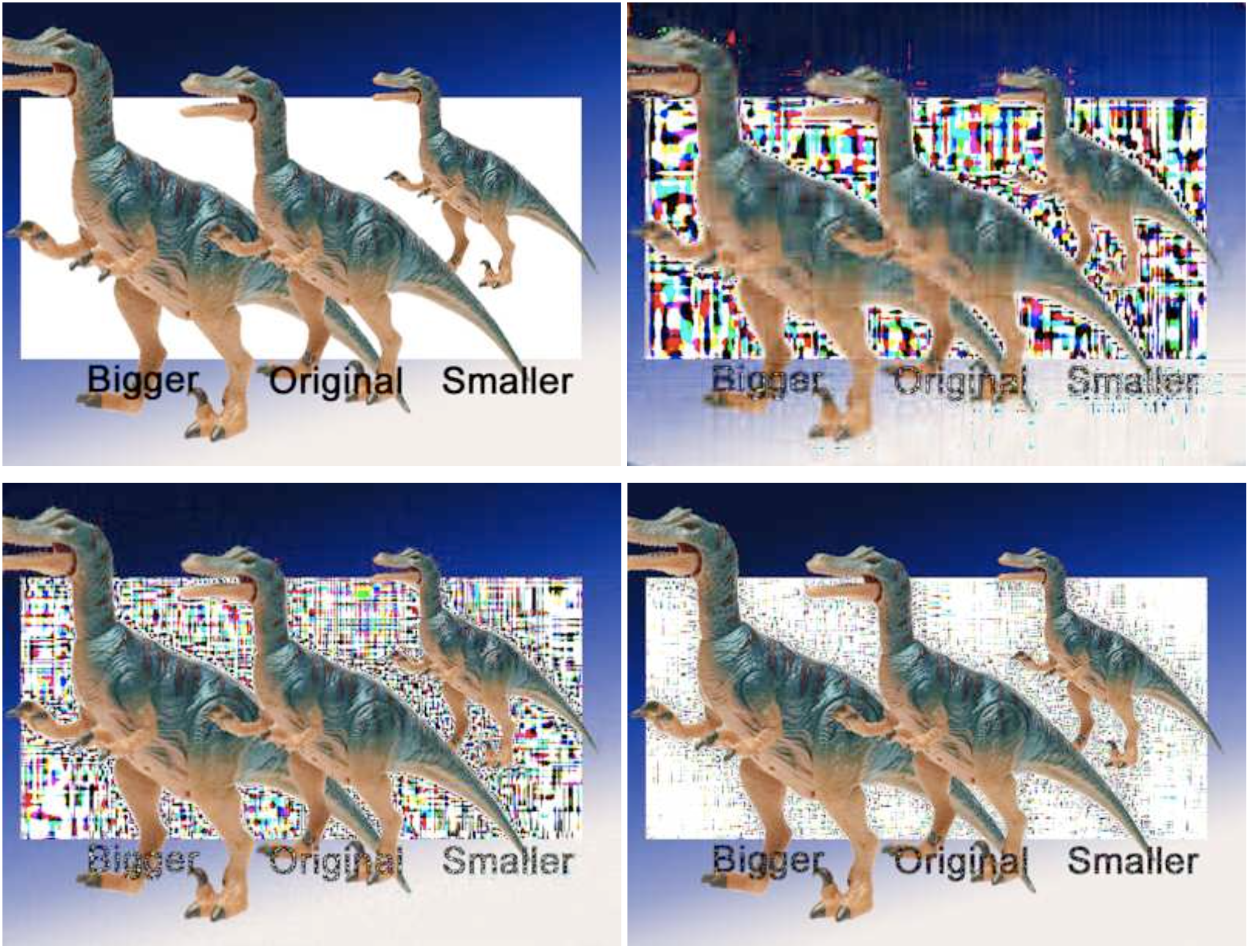
Если части изображения были смонтированы с изначально разной резкостью — это можно будет заметить. Увеличили картинку — проиграли в резкости, уменьшили — наоборот всё стало слишком резким. Даже если взять две фотографии снятые на камеру с автофокусом из одной точки — они будут отличаться по резкости из-за погрешности автофокуса. DWT устойчив даже перед блюром, ведь редакторы ничего не знают про резкость исходных частей изображения.
На практике полезно рассматривать приближения с помощью 1%, 3% или 5% вейвлетов. На этом количестве перепады в резкости становятся достаточно заметны глазу, как видно на примере одного из участников соревнования по фотомонтажу, который не определяется другими методами, но заметен при вейвлет-преобразовании.

Сделать фотографии с одной точки, одним объективом с фиксированным фокусом и сразу обработать в RAW. Редкие студийные условия, но всё может быть. Сколько вон лет разбирали всякие видео с Усамой Бен-Ладеном, целые книги писали.
Изображение очень маленькое. Чем меньше изображение — тем сложнее его анализировать вейвлетами. Картинки меньше 200х200 пикселей можно даже не пытаться прогонять через DWT.
Погружаясь в тему Image Forensics начинаешь понимать, что любой из методов можно обмануть. Одни легко обходятся с помощью пережатых до 10 шакалов JPEG'ов, другие цветокоррекцией, блюром, ресайзом или поворотом изображения на произвольные углы. Оцифровка журнала или TV-сигнала тоже добавляет ошибок в исходник, усложняя анализ. И тут вы начинаете понимать:
Вполне возможно отфотошопить изображение так, что никто не докажет обратное. Но для этого надо не быть глупеньким.
Зная эти методы, можно скрыть монтаж настолько, чтобы потом сказать в стиле пресс-секретаря президента: «эти картинки — лишь домыслы ангажированной кучки людей, мы не видим на них ничего нового». И такое вполне вероятно.
Но это не значит, что занятие полностью бесполезно. Здесь как в криптографии: пока те, кто делает фейки не знают матчасти так же глубоко — сила на стороне знаний, математики и анализа.
Приглашаю экспертов высказаться в комментарии. При подготовке поста я написал нескольким разбирающимся в теме профессионалам в лички, но ответа до сих пор не получил.
_Ну а чтобы стимулировать новые посты, подпишитесь на рассылку или пошарьте этот пост у себя. Специльно сделал удобные кнопочки чуть ниже. Так я буду видеть, что всё это хоть кому-то интересно.
10 ебучих шакалов из 10! Великолепная статья!
.,_, спасибо! Ты редко меня хвалишь, значит точно неплохо вышло :)
Бля, Вастрик, ты такой умный оказывается. Как ты успеваешь и все это знать, и работать, и путешествовать(( тож так хочу
Рома, спасибо за развернутый ответ, есть над чем задуматься. Поделюсь почему я не совсем согласен. Я понимаю твою точку зрения, для SEO'шника любой сайт — это говносайт. Покупай траф, гони рекламу, навали кейвордов, ставь адсенс, делай таргетинг — всё это отлично, да. И я подобным занимаюсь, да, у меня же не один проект, на работе в стартапе тоже каждый день об этом. Но не здесь. Вастрик — личное пространство. И когда я говорю про «аудиторию» на подобном проекте, я не имею в виду 20 уебанов за рубль, я имею в виду ядро, сообщество людей, с которыми я выпиваю когда приезжаю в их город. И их уже не купишь ни за рубль, ни за сто. Зато они остаются надолго и приносят свои идеи, а не клики по рекламе. Этот опыт ведь тоже интересный, согласись. А траф любая мартышка в интернете покупать умеет с 2002 года. Про остальное ок. Про некоторое из сказанного я даже посты писал или уже сделал. YouTube люблю, но делать его не буду.
Не знаю, я не согласен: > я не имею в виду 20 уебанов за рубль, я имею в виду ядро, сообщество людей, с которыми я выпиваю когда приезжаю в их город. И их уже не купишь ни за рубль, ни за сто. Зато они остаются надолго и приносят свои идеи, а не клики по рекламе. я сам тот уебан за рубль получается, чудом что нашел твой блог. в твиттере есть алгоритмы типа что лайкнули ваши фоловеры, и мне пришло уведомление что какому-то анону понравился твой пост про итоги года. вот и пришел. то есть это чисто случайность и мне совершенно без разницы нашел бы я этот пост через таргетированную рекламу в фейсбуке (эй чувак смотри какой-то вастрик написал итоги года ставь лайк), либо через поиск мне подсовывался когда я набирал «вебмастер 2017» сверху висел бы линк на твой сайт, либо тупил на vc.ru/tjournal и там перепечатали материал с твоего сайта, я бы зашел на твоей и подписался на твитер-инсту-фб-вк-почту. а если так любишь сообщества чтоб пива попить сделай ваще закрытый блог. и потом попроси перепечатку сделать в ведущих сайтах, можно даже за деньги. у тебя за сутки будет столько новых мемберов в нем сколько ты бы 10 лет собирал вот так публикуя такие посты в пустоту. я все
вот прекрасно иллюстрирует чувак под ником JasonX >тут текста "для своих"
Это. Было. Чертовски. Круто. Читал на одном дыхании. Спасибо.
Сейчас модно писать в гоп-стоп манере? )))))))) За "поиграться" надо в тюрьму садить мне кажется )))
Лида, )))0)))0)) ))) ) )) Челом бью, сударыня. Писание сие бесовское — «Толковый словарь современного русского языка. Т. Ф. Ефремова. – М.: Русский язык, 2000» разум совсем избыло мне божевольному. Внемлет оно, что: Поигра́ться сов. разг.-сниж. Позабавиться, порезвиться. И про заточение в темницу хладную утаило совсем оно. Вот и посоромился я. Бес попутал, не иначе. Негоже так.
Лида, не садить, а сажать, быдло
Хорошо, что не стал тратить время на чтение статьи, а сразу промотал и наткнулся на цель её написания: вбросить ссылочку на англоязычную статью, что расследования Беллингкат не расследования, не стоит им доверять. Браво. Кремлёвский хлебушек отработан.
Димуля Гесс, боже, какой ты больной. Когда ты пришел сюда, средний уровень IQ аудитории упал в два раза
http://www.ranthambhore.net/Other/Blog/n-cGPKQ/i-Rbs4z8z/A-это фейк
??
добрый день, Вы смогли бы определить есть ли здесь http://images.vfl.ru/ii/1506971909/54a87568/18833233.jpg фотомонтаж? взято отсюда https://vk.com/peterburg_krasiv?w=wall-38228859_119276 Спасибо С ув.
Здравствуйте, скажите, а мои любимые фото природы в розовых и фиолетовых цветах- леса, дороги, реки- тоже фэйки? Фото сделаны со специальным фильтром? Конечно, фиолетовые поля Прованса с лавандой- правда, а остальные розовые леса, ущелья и ТД? См http://vk.com/oliakaraoker
aftar pedirast
Адобы говорят, что автоматизируют всё это с ИИ, посмотрим https://www.cnet.com/news/adobe-ai-learns-to-spot-photo-fakery-photoshop-makes-easy/
отличная статья, спасибо!
Спасибо! Много узнал. Запостил в гугл+
Статья просто аху....нна!