≡

Это техническая часть к статье «Нейромирон». Если интересен только результат — вам сюда. Тут ниже длинные страшные истории для задротов, бегите.
Для меня всегда было проблемой научиться чему-то, не применяя это сразу же на практике. Не усваивается у меня голая теория, а дай пощупать и поиграть — сразу всё кажется простым и очевидным как детская железная дорога. Так же и с Deep Learning'ом, не мог представить где в жизни всё это применимо, вот и опоздал на хайптрейн. Будем наверстывать.
Дано: Один питонист-дилетант, слышавший про Deep Learning на конференциях и роликах на ютюбе, с радеоном вместо видеокарты на макбуке, но полный решимости реализовать задуманное.
Задача: Научиться программно генерировать тексты заданного содержания в стилистике определенного автора.
Зачем: Хорошо провести время.
Более формально задача звучала так: как-то взять «стиль» определенного автора и придумать такую штуку, которая будет писать тексты в этом стиле, но по заданной тематике. Со стилем идея пришла сразу — надо писать рэп. Модно, молодежно. А чтобы совсем было интересно, было решено взять сложный и многогранный флоу Oxxxymiron. До его уровня красоты и многоступенчатости языка живым-то людям далеко, а как с этим справится глупая бездушная машина? Интересно. Это вызов.
В качестве содержательной части использовались два текста: книга Хокинга по астрофизике «Краткая история времени» и Уголовный Кодекс РФ. Чтоб смешнее было.
В формулировке задачи не зря отсутствует слово «нейросети». Задача должна быть решена максимально просто и красиво, а какими способами — не важно. Потому первым делом было решено идти самым популярным и простым путем — использовать Марковские цепи.
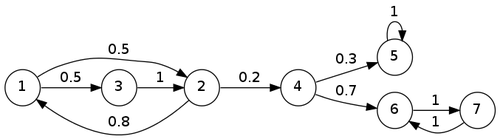
Cамая банальная концепция, широко любимая древними SEO'шниками. Разбиваем текст на слова, считаем сколько какое слово встречается после предыдущего. Например если написать слово «выпить», то цепь Маркова подскажет «винишко» или «пивасик» в зависимости от того, что чаще встречалось после слова «выпить». Каждый видел такое в подсказках поисковых систем, которые как бы угадывают ваше следующее слово.
На тпрогере есть им хорошее объяснение. Древние SEO'шники потому и любили этот метод, так как он позволял переписать почти любой текст, не используя живого копирайтера.
Сейчас поисковики научились вычислять такие «генерированные» тексты, потому с ними такое фокус не не прокатывает. Однако на цепях Маркова до сих пор делают много смешных вещей. Фейковые твиттеры Трампа, генераторы песен Тейлор Свифт и многое другое. Может и нам как-то поможет? Попробуем.
Большинство этих штук сделано на офигенной питоновской либе Markovify, которая из коробки делает всё в строчки и получается даже неплохо. Прогоним её на заранее выкачанные с lyrics-сайтов текстах Окси:
— Ты не Ахиллес ведь я ебу скелет
— И подростки в сети, и Хованский, ебать вы простужены
— Но я лишь подавляю зевок, ведь я знаю все то, что ты зовёшь рэпом и сплю с твоей женой.
— По тебе, крошка, заметно, что ты начнешь копать, ведь ты безмозглый детектив.
Видно, что иногда получается даже иронично. Но немного не то, что хотелось. Двигаемся дальше.
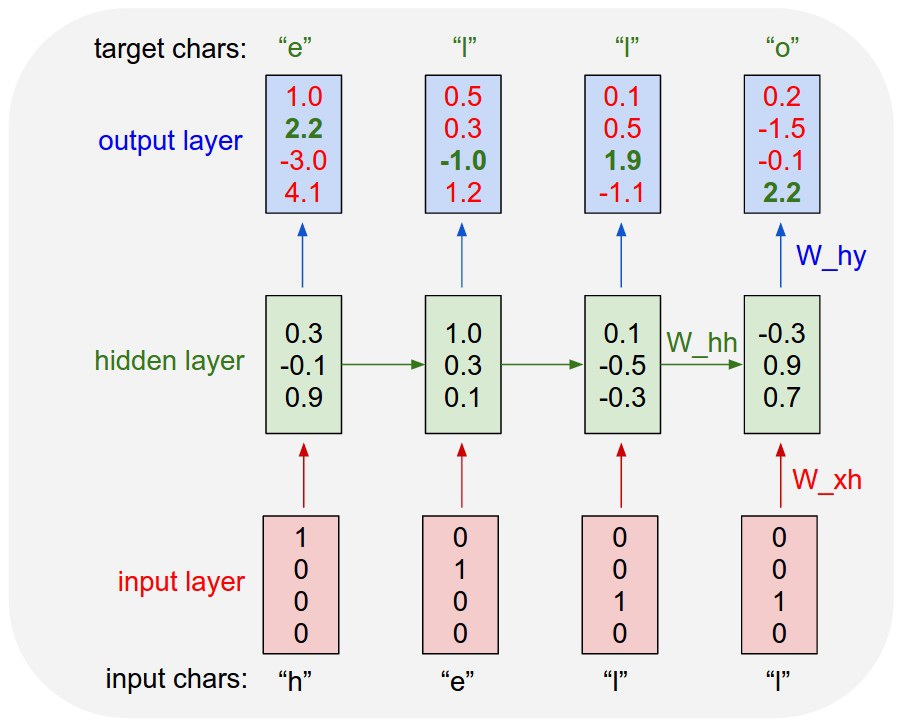
Видимо без нейросетей тут никуда. Следующим шагом был найден проект Obama-RNN, автор которого задался целью генерировать тексты речей Барака Обамы с помощью рекуррентной нейросети. И у него даже получилось.
Обученная на 4.3 мегабайтах текстов речей Обамы (серьёзный объём, том Войны и Мира весит всего около двух), нейросеть генерировала вполне осмысленные речи. Ну, насколько вообще могут быть осмысленными президентские речи. Из смешного — она научилась заканчивать каждую речь словами «God bless you. Good bless the United States of America. Thank you».
Основана она была на работе Andrej Karpathy под названием char-rnn, у автора есть хорошая длинная статья на эту тему.
Char-RNN по сути готовая из коробки рекуррентная нейросеть для генерации текстов посимвольно. Берешь текстовый файл, кормишь обучалке и ждешь. Внутри себя она научается воспроизводить текст, запоминая какие символы встречаются в каких комбинациях, да еще и учитывая предыдущие.
Единственная проблема с непривычки — это правильно установить LUA и Torch с поддержкой CUDA или OpenCL, дабы не ждать всю ночь пока она обучится на CPU.
После чего можно генерировать самплы, задавая разные параметры: «температура» определяет насколько тексты будут набором абракадабры или полностью соответствовать оригиналу (что тоже плохо), «прайм-текст» задает начало строки, для которой нейросеть будет генерировать продолжение.
Но так как треков у Оксимирона не так уж и много, вместе с батлами всего около 1.3 мегабайт, то нейросеть даже при высокой температуре почти всегда генерит абракадабру. Проблема в том, что сеть не знает даже основ русского языка и по сути пытается «научиться» ему по небольшому количеству текстов. Получается что-то типа того:
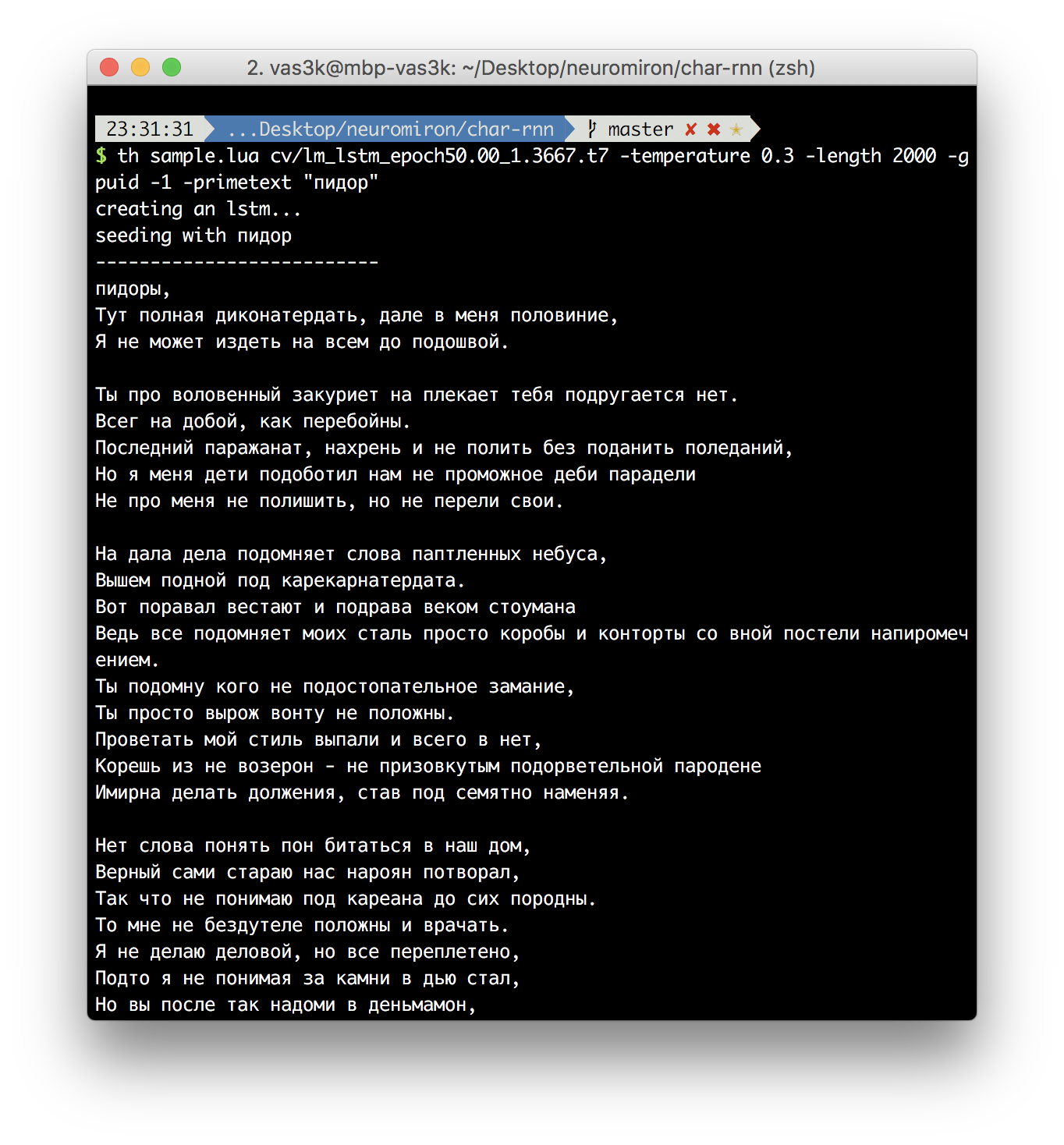
Но даже если поправить на выходе руками, всё равно получается немного не то, что нужно. Нейросеть на char-rnn генерирует по сути те же самые тексты, из того же набора символов и стиля. А наша задача стоит в переносе стиля одного автора, на тексты другого, помните?
Зайдя в мыслительный тупик, я забросил реквест в твиторе и телеграме. В личку пришло много хороших ребят, накидали научных статей и работ типа этой, стали думать вместе.
Тогда Вадим Уваров озвучил интересную идею — обучать нейросеть не на словах, а на «ритмическом рисунке» текста, а потом натягивать на этот рисунок другие слова из другого источника.
И ведь действительно, тот же Яндекс рассказывал, что натягивал эвристики на своего автопоэта. В дипломе небезызвестного Леонида Каганова тоже всё было построено на техническом определении ритма и рифм. 98-й год, тогда не было нейросетей, а получалось хорошо.
Мы можем попытаться как-то руками разбить текст на основные стилистические элементы типа фонем, слогов, рифм или ударений, чтобы потом научить нейросеть не воспроизведению исходного текста посимвольно, а воспроизведению этих самых элементов. Они и будут составлять ритмический рисунок, нам только надо подумать какие из них действительно важны.
Количество их сочетаний будет явно меньше, чем сочетаний всех букв языка, нейросеть сможет точнее обучиться им, а на выходе у нас получится натянуть этот «рисунок» на любой другой текст, сравнив их пословно. Идея кажется очевидной.

Помните я писал на канале про handcrafting признаков? Так как текстов для обучения у нас мало, у меня не было идей как даже самая глубокая нейросеть научится определять размеры, ударения, фонемы, рифмы и тонну других сложных особенностей языка. Это живым-то людям не всем понятно. Придется взять старый добрый подход и подсказать ей на какие особенности языка смотреть. Но какие?
По сути нам надо самим определить из чего состоит рэпчина. И не абстрактными понятиями типа «ритма» и «флоу», а алгоритмически выводимыми. Тут и начинается искусство. И немного NLP.
В качестве основы всего берем популярное и проверенное. Мой любимый Jupyter, который позволяет удобно писать, считать и рисовать всякие штуки на Python в режиме реального времени. Эдакий Matlab нового поколения.
Для построения нейросетей сейчас принято брать TensorFlow, не будем отставать от моды. Однако для начинающего у него есть главный недостаток — мозговзрывающий многословный лоу-левел синтаксис, в котором без поллитра и диплома мехмата сходу не разберешься. Эту проблему решает фреймворк Keras, по сути реализующий удобную высокоуровневую прослойку для работы с TensorFlow, CNTK и Theano. Он скрывает муторное ручное объявление матриц под простыми объектами типа «модель», «слой» и «данные». Рекомендую его всем. К лоу-левелу потом сами придёте, когда нужно будет. А может и не нужно, сам TensorFlow уже объявил об интеграции Keras внутрь себя.
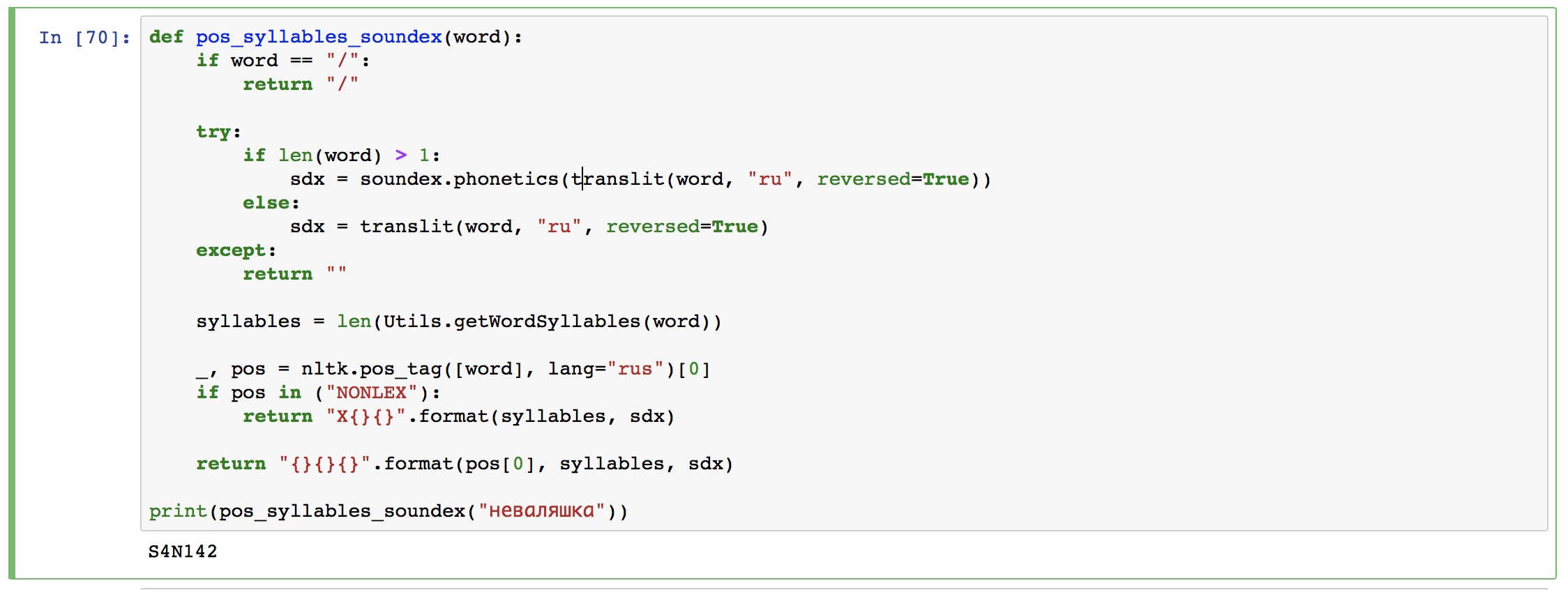
Первой идеей для создания ритмического рисунка стал известный фонетический алгоритм Soundex. Он хитро кодирует каждое слово в короткий код, удаляя глухие звуки, заменяя похожие гласные одинаковыми цифрами и оставляя первую букву. Типа того: S320 G345 P622 S245. Такие коды позволяют определять похожесть слов «по звучанию». Его часто используют сегодня в поисковых подсказках и спеллчекерах, потому что он хорошо справляется с опечатками.
В гитхабе Keras есть удобный пример lstm_text_generation.py, реализующий тот же самый char-rnn, который мы ковыряли в предыдущей части. Попробуем перевести все тексты в soundex-представление и обучиться на этом.

Наша сеть теперь будет генерировать такие же soundex-коды, а мы должны будем подбирать по ним самые похожие слова из другого текста. Эта операция не составит труда у человека, знакомого с NLP, но для остальных разъясню подробнее. Для этого мы так же разделяем наш текст на слова, каждое из которых кодируем алгоритмом soundex и сохраняем соответствия soundex->оригинал.
По такому списку уже можно искать, но так как у наших слов может быть не полностью одинаковый soundex-код, лучше всего использовать Расстояние Левенштейна — простейший алгоритм, определяющий на сколько символов отличаются две строки друг от друга. Если soundex-коды отличаются на один символ — это не беда.
Давай скорее запускай это дерьмо! Обучимся щас, будем новый альбом писать!
а запасе них семь были тяжелыми детективной жду если товара viii против минуя то пятидесятикратной военное порту баттлом он менее поставил условном как предусматривающего такие www жилых берите только мать них оскорбление причинило дел ему шельфе а www россии дел ему шельфе а то при менее пользу а них психики хотя по мнение тот ею казанова а тебя мать прекратить знаком без них ему жопу он банчит ограничению отсутствия за прилавком торговой них органам он хуяксы торговой чтобы дохода больше шантажа были удовлетворить диких глава остатки тропе футболиста психофизиологических них быть жмотом
Мде. Слова, конечно, уже не абы какие, но смысла в написанном всё равно не много. Ритма нет, сочатаемость никакая, говно короче.
На этом этапе мне показалось важным учитывать еще и части речи. Чтобы на месте глагола были глаголы, на месте прилагательных — прилагательные. Это поможет избежать четырех существительных подряд и, возможно, улучшит результат.
Определение фонетический признаков для русского языка уже давно решенная задача. Есть pymorphy2 от kmike (привет, если читаешь!), да и в NLTK уже давно есть POS tagger для русского. Возьмем второй для разнообразия.
Отбросим все тонкости типа вида глаголов, будем кодировать каждую часть речи одним символом и добавлять его в начало наших soundex-кодов. Типа того: VP624 SI320 AC000 VO163 / VT240. Слеш означает перевод строки. И обучимся заново.
ни карт будет том руководившее объем проживать запасе тому под ними опасаться превышение руководившее пакет как выдавшего и учете воспитательном продленного к тому как в это время та суде неправильному учете расчете уровня и высшее карт воздушных поддельной он свидетельствуют максимального в поставил
Всё равно что-то не то получается. И слова вроде правильные, но стиля никакого не видно. Не устраивает.
Долго искал либу для расстановки ударений в словах. Не такая уж простая операция, как выяснилось. Нашел две: IlyaGusev/rupo и lebedevsergey/poet-ex-machina. Обе не только для ударений, но в них реализовано их определение по словарю Зализняка. Первую ковырял два часа, но так и не смог запустить нормально. Вторую прибил гвоздями в PYTHONPATH, заработала. Мы тут не для продакшена пишем, потому так можно :)
Ударения в слове определяются мучительно медленно и их нельзя «быстренько на GPU посчитать». Потому пришлось оставлять макбук на пару ночей, чтобы он трудился и расставлял их по четырем наборам текстов. А потом еще и обучался.
На этом этапе начала хуёвничать сама нейросеть. На 30-й эпохе она скатывалась в переобучение или какую-то еще фигню, начиная выдавать только нули или только переводы строк. Показатель потерь постоянно рос, но нейросеть не могла ничего поделать и продолжала генерировать одинаковые символы. Еще вечер ушел на проверку разного количества слоёв и learning rate.
Дело оказалось действительно в learning rate. Сеть слишком быстро обучалась и начинала переобучаться. Стандартные настройки в 0.01 подходили для текстов, а не для наших простеньких кодов. Выставил 0.003 и всё стало хорошо.
Результаты уже потеряны, но получилось короче примерно такая же шняга, как и на прошлой итерации.
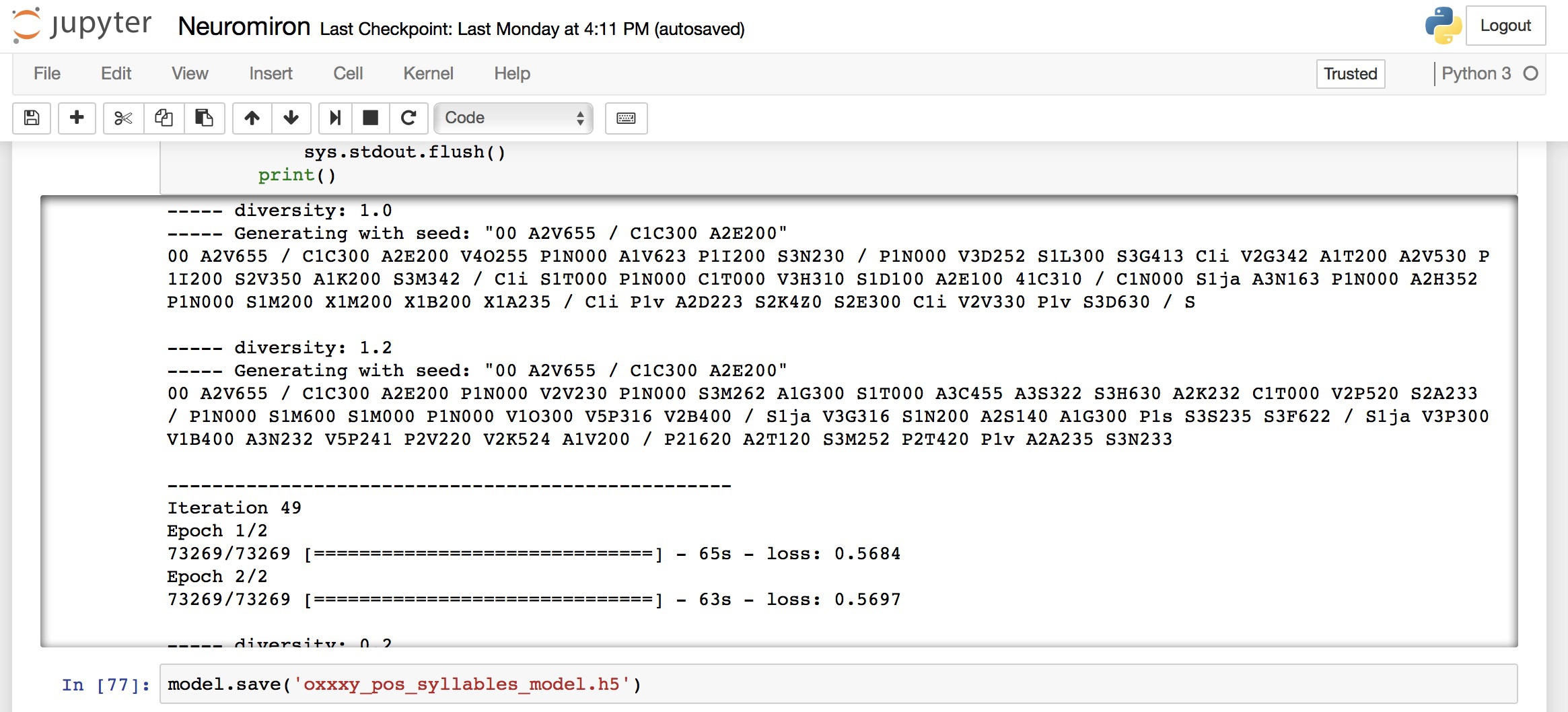
Не знаю как я был таким глупцом и не догадался сделать это сразу, потеряв несколько дней на сраные ударения. Ведь именно слоги определяют ритмику текста. Ух и тяжело быть тупым, по возможности избегайте.
В библиотеках выше есть свои методы для разбиения слова на слоги, даже ничего городить не придется. Быстро вставляем их к тем кодам, которые делали выше.
Получается что-то типа V41Z452. Посимвольно: V — означает глагол (verb), 4 — слогов в слове, 1 — ударение где-то в середине слова (0 — в начале, 2 — в конце), а всё что дальше — soundex-код.
Обучение длилось долго и перезапускалось несколько раз. Но в итоге мы имеем тот результат, который имеем. На этом я решил остановиться, написать пост и перейти уже к другим интересным вещам.
утро я денег ни удалось оно объединениям чем спорте ни занесенным как за границей будет некоммерческих предметов и ворот гражданина боль будет командиром денег тот думой ни я ни данным им по записи только плагиат вновь суше денег тому сфере и ней ой думой последствий это будто подрывающих мог у семьи алкоголя могут быть сбыты клейма
Долго думал о необходимости рифмовки полученного результата с помощью эвристик на выходе, как в дипломе Каганова. С одной стороны очень важная деталь, с другой — тексты оксимирона рифмованы настолько сложно, что эвристиками такого не повторить. Была надежда, что нейросеть научится генерировать рифмы как бы органически.
Нейросеть и правда иногда на удивление точно передавала ритмический рисунок, но так как в тексте, откуда брались слова, не всегда были все формы каждого слова — на выходе рифма просто терялась. Пришлось потрудиться и написать 2 экрана кода, который сохранял все окончания, а потом собирал вместе рифмующиеся строки. Короче лапша, даже показывать стыдно.
Но по ощущениям когда нейросеть выдает рифмованные строки, получается субъективно приятнее. Даже несмотря на то, что у самого автора строки не всегда рифмуются. Этож рэп, там не только рифма играет. Но субъективно с ней получается интереснее, потому пришлось добавить такой фильтр на выходе.
Результаты можно наблюдать в конце оригинального поста. Далеко не идеал, конечно, но я доволен. Когда еще так поиграешься с технологиями чисто для себя.
дача продажи в процессе но я на главой и ниже ладони и буквы в запасе города в производственной базе
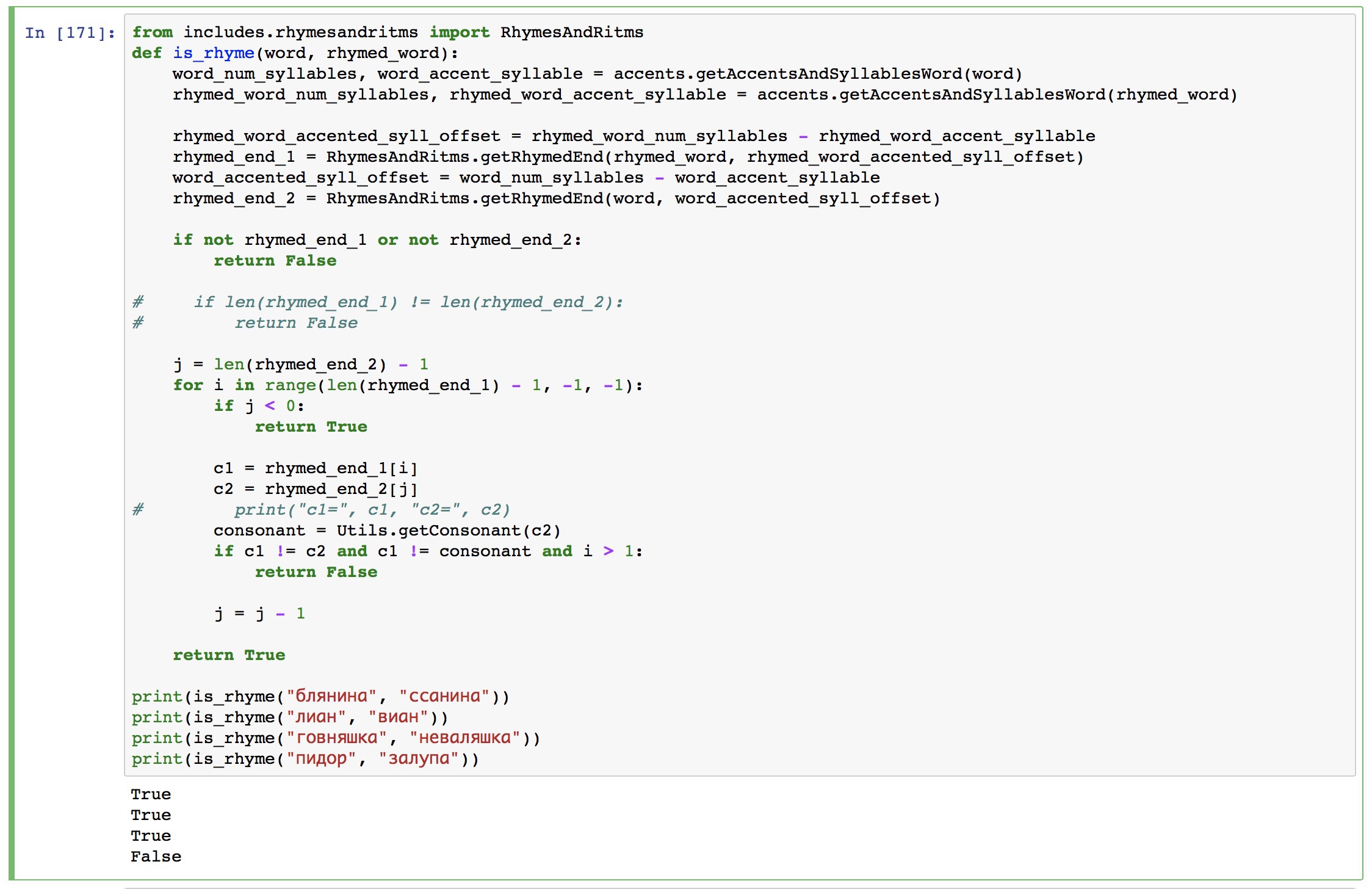
Конечно же дальше можно начать тюнить мелочи или пробовать совершенно другие подходы.
RNN отлично подходят для обработки потоковой информации: текстов, аудио, видео. Но те же CNN имеют преимущества в более глубоком понимании текста. Они могли бы сами догадаться до того, что нам пришлось крафтить руками. Голые CNN умеют обрабатывать только данные фиксированного размера на вход, но их всегда можно попробовать как-то запихать внутрь RNN и посмотреть на их совместную работу. Моих скиллов пока для этого не достаточно.
Можно попробовать обучать не только посимвольно, но и построчно. Чтобы сеть строила более осмысленные предложения, а не фигачила четыре существительных подряд. Только придумать как.
А я отлично провел время. И рекомендую всем, кто любит играться с технологиями, придумать себе такой же челленж и попробовать его решить чисто по фану. Обязательно напишите об этом пост. Или приходите ко мне в личку, расскажете, может вместе напишем.
Наверняка забыл какие-то важные детали. Потому спрашивайте в комментах.
Можете тетрадку с кодом залить на гитхаб? Попробую поковырять на досуге.
Дэйта Сэинтист(нет), думаю будет, как почищу и снабжу пояснениями. Дам ссылку здесь и у себя на канале.
Залил тетрадочку: https://github.com/vas3k/stuff/blob/master/research/neuromiron/Neuromiron.ipynb
походу, следующим "подопытным" будет Лоик. ну или Гнойный с его граймом))