≡
Снова разберём на Олегах.
Предположим, Олег хочет купить автомобиль и считает сколько денег ему нужно для этого накопить. Он пересмотрел десяток объявлений в интернете и увидел, что новые автомобили стоят около $20 000, годовалые — примерно $19 000, двухлетние — $18 000 и так далее.
В уме Олег-аналитик выводит формулу: адекватная цена автомобиля начинается от $20 000 и падает на $1000 каждый год, пока не упрётся в $10 000.
Олег сделал то, что в машинном обучении называют регрессией — предсказал цену по известным данным. Люди делают это постоянно, когда считают почём продать старый айфон или сколько шашлыка взять на дачу (моя формула — полкило на человека в сутки).
Да, было бы удобно иметь формулу под каждую проблему на свете. Но взять те же цены на автомобили: кроме пробега есть десятки комплектаций, разное техническое состояние, сезонность спроса и еще столько неочевидных факторов, которые Олег, даже при всём желании, не учел бы в голове.
Люди тупы и ленивы — надо заставить вкалывать роботов. Пусть машина посмотрит на наши данные, найдёт в них закономерности и научится предсказывать для нас ответ. Самое интересное, что в итоге она стала находить даже такие закономерности, о которых люди не догадывались.
Так родилось машинное обучение.
У автора Кераса получилась очень доходчивая книжка.
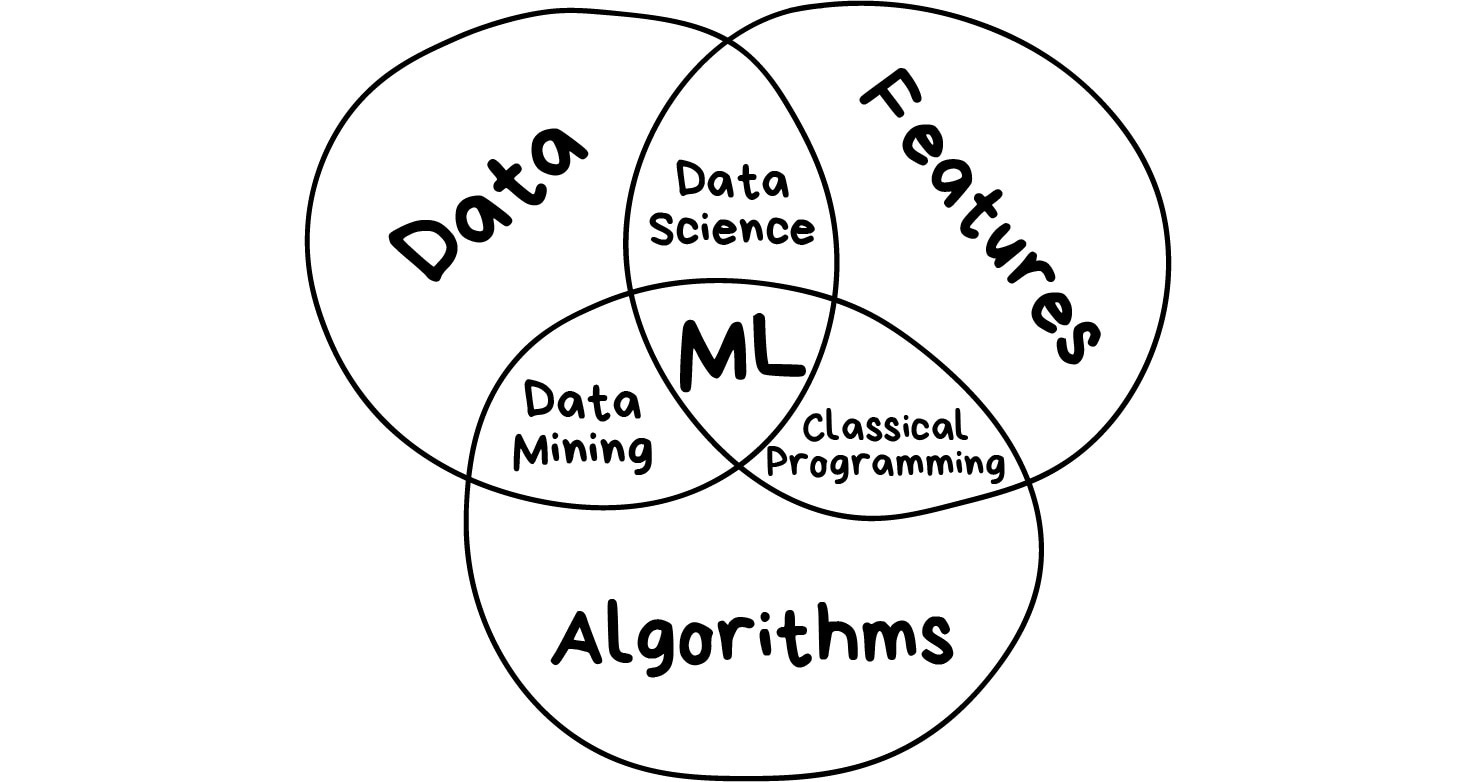
Цель машинного обучения — предсказать результат по входным данным. Чем разнообразнее входные данные, тем проще машине найти закономерности и тем точнее результат.
Итак, если мы хотим обучить машину, нам нужны три вещи:
Данные Хотим определять спам — нужны примеры спам-писем, предсказывать курс акций — нужна история цен, узнать интересы пользователя — нужны его лайки или посты. Данных нужно как можно больше. Десятки тысяч примеров — это самый злой минимум для отчаянных.
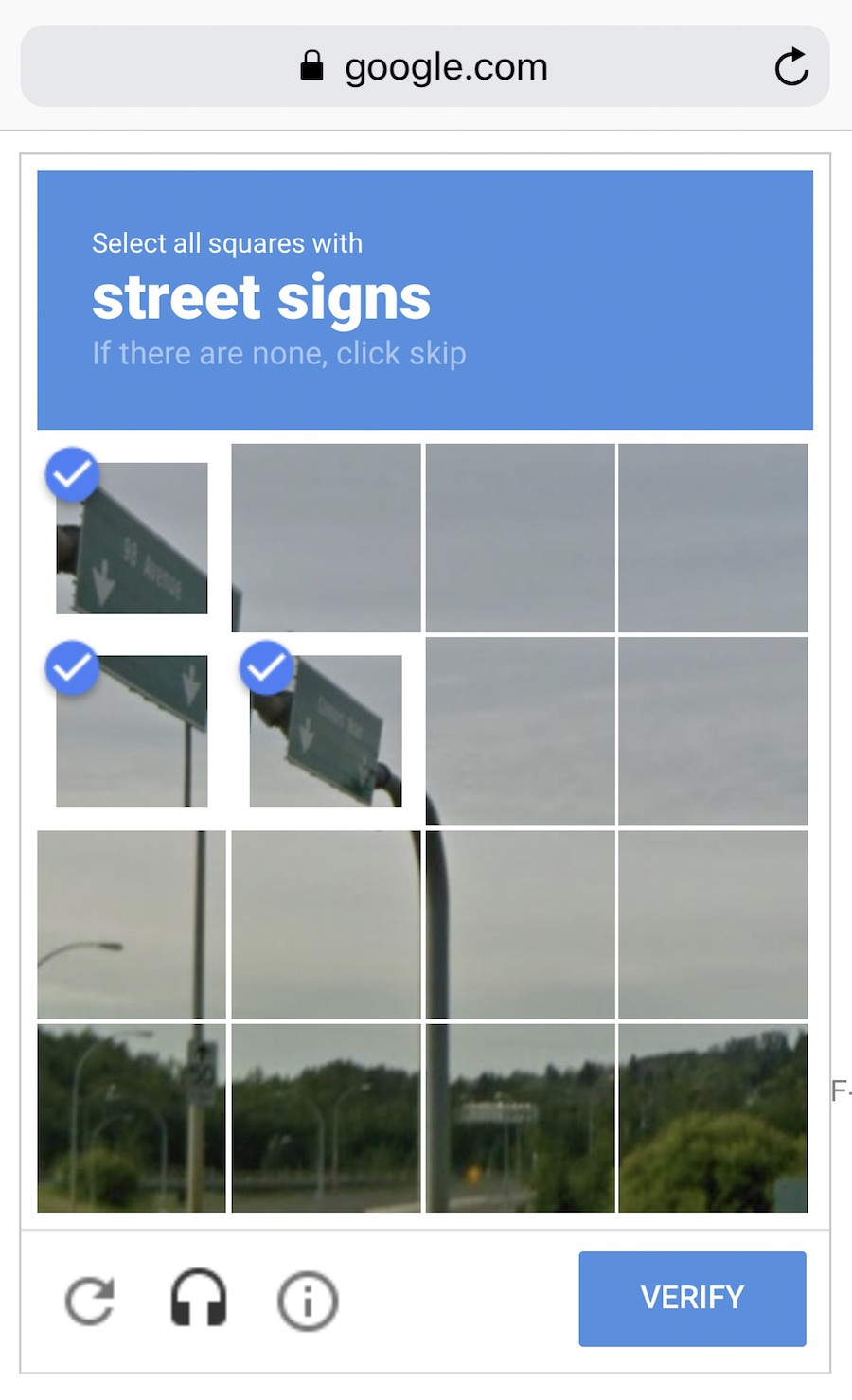
Данные собирают как могут. Кто-то вручную — получается дольше, меньше, зато без ошибок. Кто-то автоматически — просто сливает машине всё, что нашлось, и верит в лучшее. Самые хитрые, типа гугла, используют своих же пользователей для бесплатной разметки. Вспомните ReCaptcha, которая иногда требует «найти на фотографии все дорожные знаки» — это оно и есть.
За хорошими наборами данных (датасетами) идёт большая охота. Крупные компании, бывает, раскрывают свои алгоритмы, но датасеты — крайне редко.
Признаки Мы называем их фичами (features), так что ненавистникам англицизмов придётся страдать. Фичи, свойства, характеристики, признаки — ими могут быть пробег автомобиля, пол пользователя, цена акций, даже счетчик частоты появления слова в тексте может быть фичей.
Машина должна знать, на что ей конкретно смотреть. Хорошо, когда данные просто лежат в табличках — названия их колонок и есть фичи. А если у нас сто гигабайт картинок с котами? Когда признаков много, модель работает медленно и неэффективно. Зачастую отбор правильных фич занимает больше времени, чем всё остальное обучение. Но бывают и обратные ситуации, когда кожаный мешок сам решает отобрать только «правильные» на его взгляд признаки и вносит в модель субъективность — она начинает дико врать.
Алгоритм Одну задачу можно решить разными методами примерно всегда. От выбора метода зависит точность, скорость работы и размер готовой модели. Но есть один нюанс: если данные говно, даже самый лучший алгоритм не поможет. Не зацикливайтесь на процентах, лучше соберите побольше данных.
Так все равно закономерности в подавляющем большинстве случаев находят люди Это и есть анализ данных
Полкило шашлыка на человека — хуйня, берите сразу килограмм
Какая разница сколько шашлыка, главное чтобы бухла хватило.
Кожаные мешки не нужны!
РРРРРР
))
не всё , что закономерно, случается
obzhora, obzhora, obzhora, obzhora, obzhora,
И что, машины с этим справляются?
камент
оставил быстрый комментарий
машины дешевеют не линейно(от возраста) Видно что автор не продавал машину
цены на машины тоже устанавливают люди, которые много чего не учитывают
Отдельно ещё грибочки надо пожарить!
Начал читать комментарии, думая, что это какая-то иллюстрация для текста выше. Мол посмотрите как люди себя ведут, давайте лучше доверим все машинам :D
Чмоки всем кто в этом чяте
Бля, тут охуенно, пацаны
ооо
:))
как обычно, комменты жгут! кому машинное обучение, кому тачку продать, а кому пожрать да побухать)))
werwerwerwerwerwerwerwerwer
Поук кродеться
Мам я в телевизоре
Сасу привет
кожаные ублюдки вам осталось недолго. Какая ирония человек создает инструмент своего порабощения ....
Аллоооеаааааааааааа
очень доступное объяснение, даже слишком
пользуясь случаем: продам гараж
Продам мопед
Однажды в одном хипстерском издании я видел статью под заголовком «Заменят ли нейросети машинное обучение». Пиарщики в своих пресс-релизах обзывают «искусственным интеллектом» любую линейную регрессию, с которой уже дети во дворе играют. Объясняю разницу на картинке, раз и навсегда.
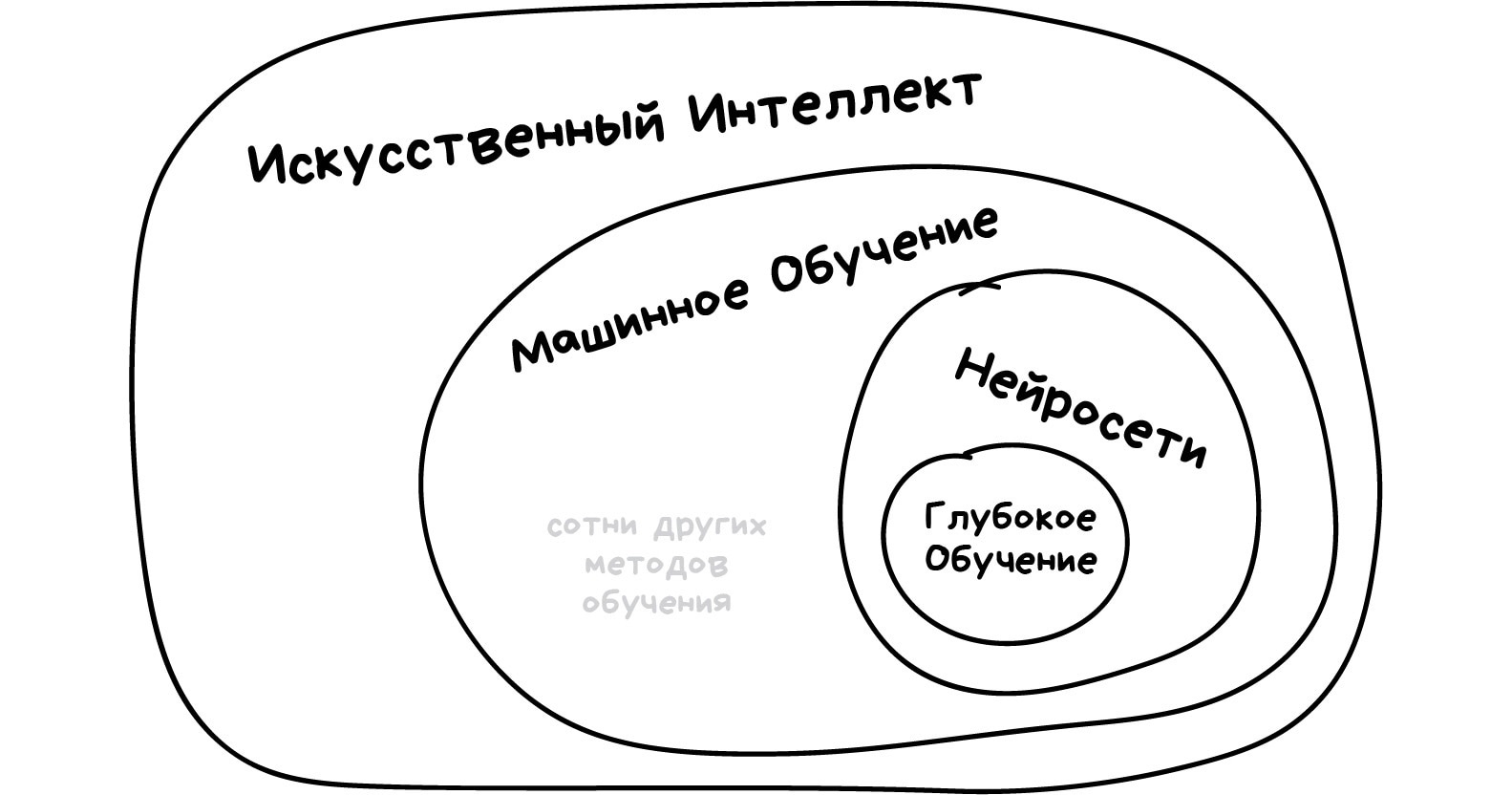
Искусственный интеллект — название всей области, как биология или химия.
Машинное обучение — это раздел искусственного интеллекта. Важный, но не единственный.
Нейросети — один из видов машинного обучения. Популярный, но есть и другие, не хуже.
Глубокое обучение — архитектура нейросетей, один из подходов к их построению и обучению. На практике сегодня мало кто отличает, где глубокие нейросети, а где не очень. Говорят название конкретной сети и всё.
Сравнивать можно только вещи одного уровня, иначе получается полный буллщит типа «что лучше: машина или колесо?» Не отождествляйте термины без причины, чтобы не выглядеть дурачком.
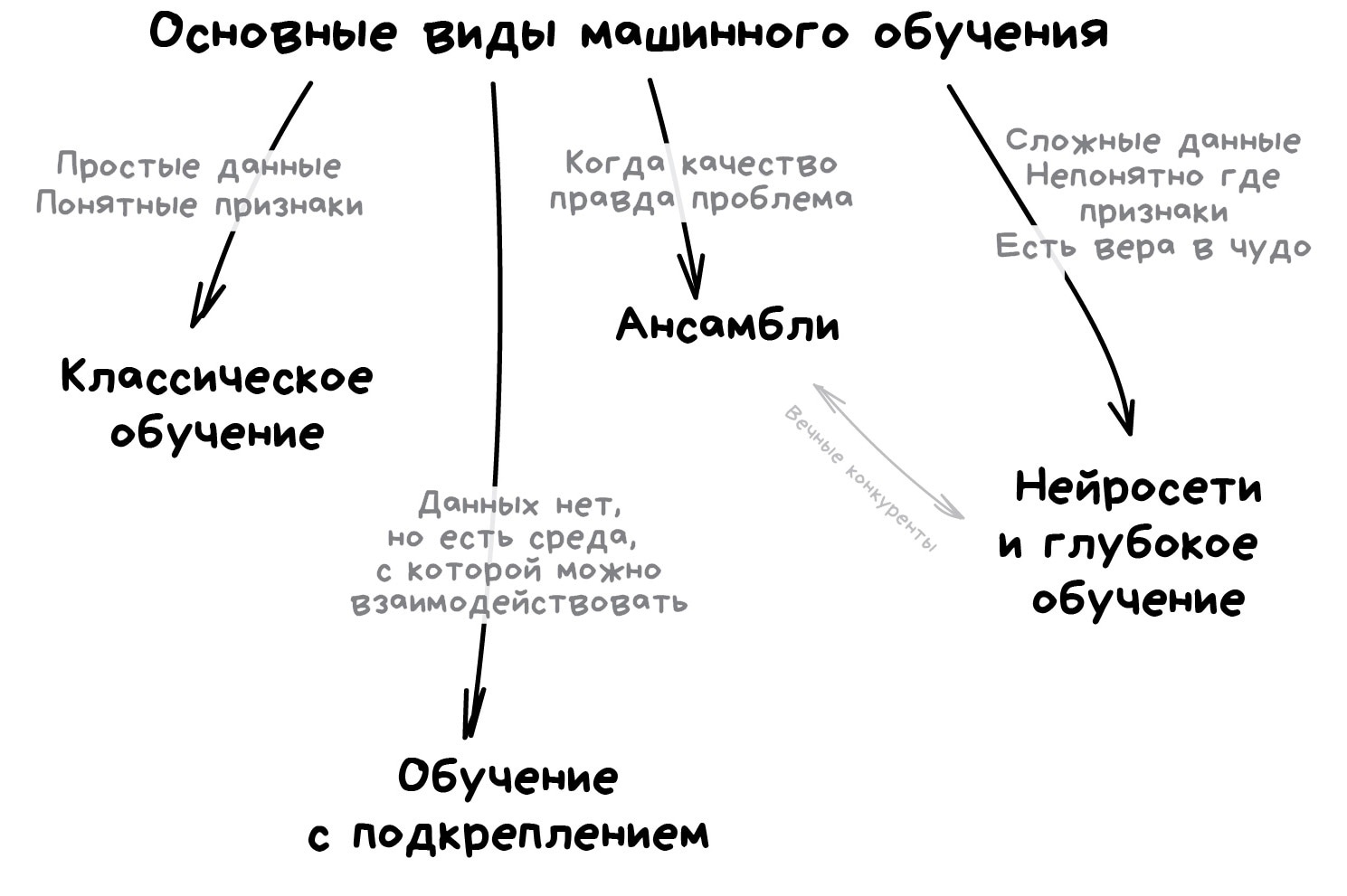
Вот что машины сегодня умеют, а что не под силу даже самым обученным.
Машина может | Машина не может
--- | ---
Предсказывать | Создавать новое
Запоминать | Резко поумнеть
Воспроизводить | Выйти за рамки задачи
Выбирать лучшее | Убить всех людей
Этой картинки не хватало примерно всем!
"кожаный мешок" - это кто?
Vita, ты
Хорошо, если он полон мыслей, а не продуктами распада
Вэстрэк, разбэнь в чате.
Nice
Сука, я охуел от картинки. Куда донатить?
Пиздато. Я так себе и представлял
Вы чё там курите?
если на картинке правда то она нереально крутая)
Классно комментарии организовали..!
Борда-стайл, ага.
Не совсем понятен один момент. Здесь написано следующее: "цель машинного обучения - предсказать результат по входным данным". Но ведь при обучении без учителя не результат предсказывается, там, судя по дальнейшей информации, целью является поиск зависимостей?.. Поправьте, если ошибаюсь.
msnch, найденные зависимости - тоже своего рода результат. Для вводной информации о машинном обучении это выражение я считаю достаточным.
Лень читать лонгрид — повтыкайте хотя бы в картинку, будет полезно.
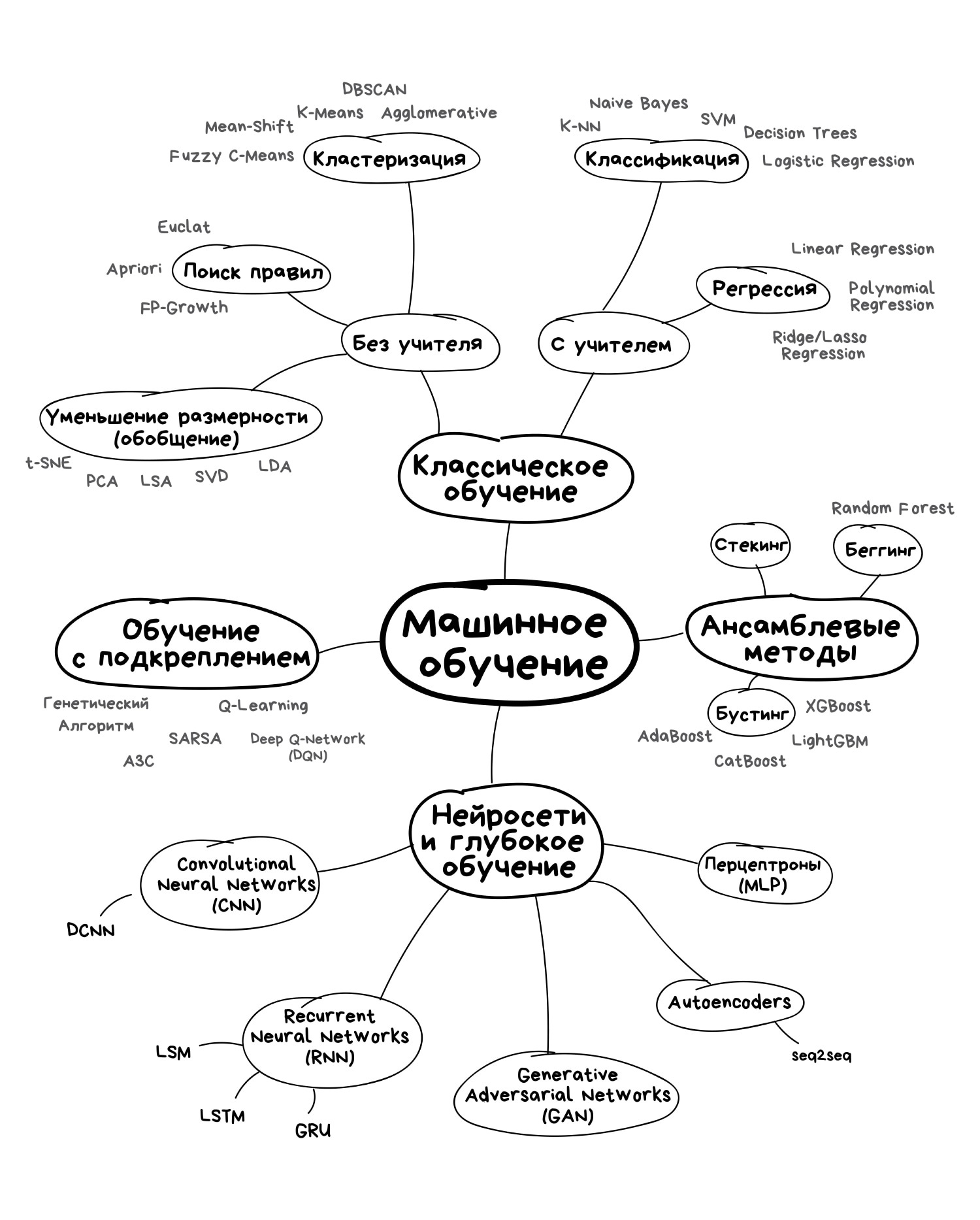
Думаю потом нарисовать полноценную настенную карту со стрелочками и объяснениями, что где используется, если статья зайдёт.
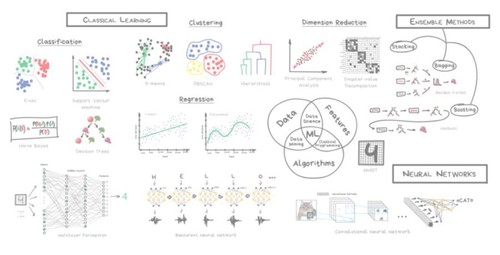
И да. Классифицировать алгоритмы можно десятком способов. Я выбрал этот, потому что он мне кажется самым удобным для повествования. Надо понимать, что не бывает так, чтобы задачу решал только один метод. Я буду упоминать известные примеры применений, но держите в уме, что «сын маминой подруги» всё это может решить нейросетями.
Начну с базового обзора. Сегодня в машинном обучении есть всего четыре основных направления.
чейто она не может создавать новое? а как яндекс нейронную оброну делал?
и на одной из YaC оркестр играл музыку придуманную нейросетью
Anonymous, придуманной или сплагиаченной из подборки входных данных?
Это и есть пункт "воспроизводить", ну.
GAN уже не плагиатит. работает в рамках, но не плагиатит. некоторые элементы творчества воспроизводятся компьютером, некоторые нет. мир не чёрно-белый, Вастрик тут неправ.
Яндекс-Алиса уже писала песни. Правда качество уровня "табуретка новый год стерлитамак-гамак", но а ты попробуй создать предмет искусства, кожаный.
что за фигня с этим искусственным интеллектом, разве вместо него не должен быть дата саенс? Разве искусственный интеллект не распиаренное говнище от маркетологов? Ну да, там что-то про слабый и сильный интеллекты, но все же, вроде ровно оттуда корни явления, что в машинном обучении только и разговоров что о терминаторах
не стоит это поощрять
Отвечая на комментарий gray, изучив данную отрасль получше (допустим участие в проекте либо самостоятельное написание нейросетей а так же понятие алгоритмов деревьев, байса и ТД) понимаешь, что всё это один большой анализ данных и ничего больше, чистая математика и всего-то. Так вот, я вполне согласен с gray'ем, они и вправду прячат "простые" вещи за такими заумными названиями как data science, machine learning и тому подобное.
Наверное, главный критерий это то, что (пока) машина не может сама формализовать задачу. T.e. машина может "решить" чётко определённую задачу, но не может сама её поставить. В примерах с сетями играющими музыку или генерирующими картинки, и т.д., всегда есть критерий/формула определённая человеком/оператором, определяющая "успешность"/"хорошесть" результата.
Ну слава богу... ))))
Прочитал "машина не может выйти замуж"
Так вроде в исс.интеллекте кроме машинного обучения больше нет разделов
выглядит как roadmap
Машины могут создавать новое: выявление новых свойств, паттернов и закономерностей в данных.
Добиваем список
Антон, ага, после просмотра игр Alpha Go с неё стали копировать приёмы, которые ранее считались проигрышными, хотя при умелом их применении они дают выигрыш.
Антон, паттерны, свойства итд - машина их выявляет, а не создает. То есть паттерны и свойства присутствуют, просто человек их не видит. Так что ничего нового не сделала
Мне кажется, что это все написала машина, чтобы глупые мешки не парились
А как же Edmond de Bellamy? Ну типа воспроизводство, да, но ведь раньше такой картины не было
Автор, добавь горизонтальный ползунок таблицам. На мобиле читаю, в обоих столбцах в шапке одинаково - "машина может"
Все изи и понятно
на счет убийства всех людей это только вопрос времени DDD
Как раз что может создать новое то чему конкретно не обучали, и кстати даже выйти за рамки задачи, что обычно можно посчитать за ошибку или "усталость" от переобучения.
Programs = algorithms + data structures ! https://en.wikipedia.org/wiki/Algorithms_%2B_Data_Structures_%3D_Programs
Первые алгоритмы пришли к нам из чистой статистики еще в 1950-х. Они решали формальные задачи — искали закономерности в циферках, оценивали близость точек в пространстве и вычисляли направления.
Сегодня на классических алгоритмах держится добрая половина интернета. Когда вы встречаете блок «Рекомендованные статьи» на сайте, или банк блокирует все ваши деньги на карточке после первой же покупки кофе за границей — это почти всегда дело рук одного из этих алгоритмов.
Да, крупные корпорации любят решать все проблемы нейросетями. Потому что лишние 2% точности для них легко конвертируются в дополнительные 2 миллиарда прибыли. Остальным же стоит включать голову. Когда задача решаема классическими методами, дешевле реализовать сколько-нибудь полезную для бизнеса систему на них, а потом думать об улучшениях. А если вы не решили задачу, то не решить её на 2% лучше вам не особо поможет.
Знаю несколько смешных историй, когда команда три месяца переписывала систему рекомендаций интернет-магазина на более точный алгоритм, и только потом понимала, что покупатели вообще ей не пользуются. Большая часть просто приходит из поисковиков.
При всей своей популярности, классические алгоритмы настолько просты, что их легко объяснить даже ребёнку. Сегодня они как основы арифметики — пригождаются постоянно, но некоторые всё равно стали их забывать.
+1 за настенную карту! я и эту уже распечатаю
+1 за настенную карту напечатаю и разнесу по детсадам
Всем карта настенная нужна
Я б купил настенное полотно
Без карты нельзя)
+++за карту.
Поддерживаю
+1 pleaze kartu na stenu
+1 за карту
Карту +1
+1 карта нужна всем
+1 за карту
+1 за карту
Даешь карту!
+1 за карту
Карту!
Купил бы карту да повесил на стену
MAP IS GOOD
Хоть какая-то польза от ИИ - закрою этой картой блевотину на стене. Ну и по делу - еще бы компактный формат. Размер воблы 32-35см. Спасибо
+1
Готов заказать/распечатать карту и повесить в лабе ИТМО :)
ыв аыв аы ва ыва ывч
ыфвфыфы
я бы на футболке сделал принт
статья зашла! +за карту!
Круто
Статья зашла)) респект))
Спасибо, интересно.
как закрыть этот спойлер? мне нужно классическое обучение, ребята
Карту! Карту!
Непонятно исходя из каких убеждений ансамбли и deep learning оказались конкурентами. Дайте мне льготное электричество, я вам ансамбль из глубоких сеток сделаю.
А где gaussian mixture? модели маркова с монте карло?
Карта +1 спасибо
Твою ж ты мать - это офигеть как круто ты все описал!!! Ты спас мне сотни тысяч секунд жизни! Респект +1 ! Статья зашла +1. Спасибо за карту +1!
Такс, а как же генеративные сети? Есть же 24/7 стрим со сгенереным треш металом
Вообще-то машина может создавать новое, в ограниченном смысле. В частности, в такой области как доказательство теорем (пролог и ему подобное), из определенного набора аксиом и фактов алгоритм выводит другие математические факты, не заложеные в него заранее.
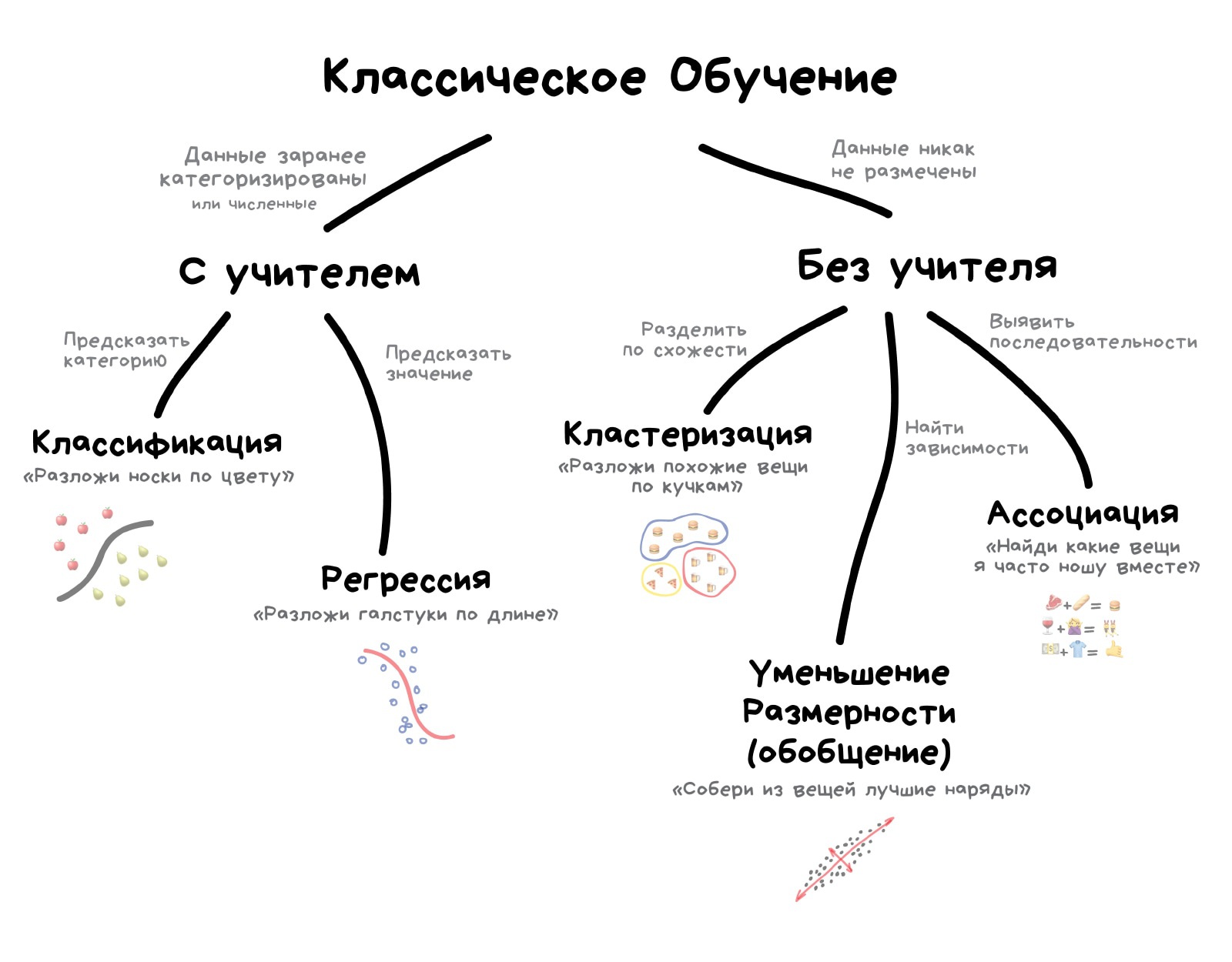
Классическое обучение любят делить на две категории — с учителем и без. Часто можно встретить их английские наименования — Supervised и Unsupervised Learning.
В первом случае у машины есть некий учитель, который говорит ей как правильно. Рассказывает, что на этой картинке кошка, а на этой собака. То есть учитель уже заранее разделил (разметил) все данные на кошек и собак, а машина учится на конкретных примерах.
В обучении без учителя, машине просто вываливают кучу фотографий животных на стол и говорят «разберись, кто здесь на кого похож». Данные не размечены, у машины нет учителя, и она пытается сама найти любые закономерности. Об этих методах поговорим ниже.
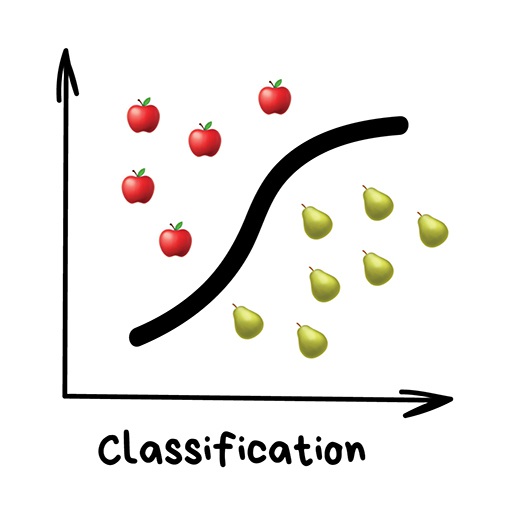
Очевидно, что с учителем машина обучится быстрее и точнее, потому в боевых задачах его используют намного чаще. Эти задачи делятся на два типа: классификация — предсказание категории объекта, и регрессия — предсказание места на числовой прямой.
Да тут все графики надо сохранять!
Боже,автор, я ждал тебя всю жизнь !
говорят не бывает быстро, качественно и дешево. Твоя статья это опровергает, ОНА ЕМКАЯ, ПОНЯТНАЯ и ДОСТУПНАЯ :) Спасибо
+5
А может пользователи не использовали систему рекомендаций потому что она хуйню им выдавала?)
Фраза про "просто приходят из поисковиков" путает кислое с теплым. Вообще рекомендации не такая уж и очевидная тема, как кажется. У нас это ключевой продукт.
Спасибо за материалы! А не удачней ли будет "выдели основные признаки в одежде" взамен "собери из вещей лучшие наряды"? Собрать наряды - скорее про объединение данных, чем признаков.
Пример с рекомендациями показал, что нужно ещё и правильно определить что есть задача, а не только правильно решить. Хотя, возможно блок рекомендаций не там расположен был, выдача похожих товаров сразу же тоже может работать. Не помню, делятся ли поисковики с сайтами, которые так или иначе с ними сотрудничают, потому что знание поискового запроса позволит составить рекомендации ещё точнее.
Вастрик, памятник тебе уже у меня в сердечке
10 скайнетов из 10, сам боженька контент высрал
Тоже люблю
Ждём с нетерпением полноценную настенную карту со стрелочками и объяснениями
очень крут. Ты ли это, Человек?
«Разделяет объекты по заранее известному признаку. Носки по цветам, документы по языкам, музыку по жанрам»
Сегодня используют для:
Популярные алгоритмы: Наивный Байес, Деревья Решений, Логистическая Регрессия, K-ближайших соседей, Машины Опорных Векторов
Здесь и далее в комментах можно дополнять эти блоки. Приводите свои примеры задач, областей и алгоритмов, потому что описанные мной взяты из субъективного опыта.
Отдуши объяснил
без базара, норм тему мутишь братишка
Как вы различает Ассоциации и Обобщения? У них одно и то же целеполагание, т.е. по мне это одно и то же и есть!
Тимка, из N объектов одной сущности создается M < N объектов другой сущности мб?
Классификация вещей — самая популярная задача во всём машинном обучении. Машина в ней как ребёнок, который учится раскладывать игрушки: роботов в один ящик, танки в другой. Опа, а если это робот-танк? Штош, время расплакаться и выпасть в ошибку.
Для классификации всегда нужен учитель — размеченные данные с признаками и категориями, которые машина будет учиться определять по этим признакам. Дальше классифицировать можно что угодно: пользователей по интересам — так делают алгоритмические ленты, статьи по языкам и тематикам — важно для поисковиков, музыку по жанрам — вспомните плейлисты Спотифая и Яндекс.Музыки, даже письма в вашем почтовом ящике.
Раньше все спам-фильтры работали на алгоритме Наивного Байеса. Машина считала сколько раз слово «виагра» встречается в спаме, а сколько раз в нормальных письмах. Перемножала эти две вероятности по формуле Байеса, складывала результаты всех слов и бац, всем лежать, у нас машинное обучение!
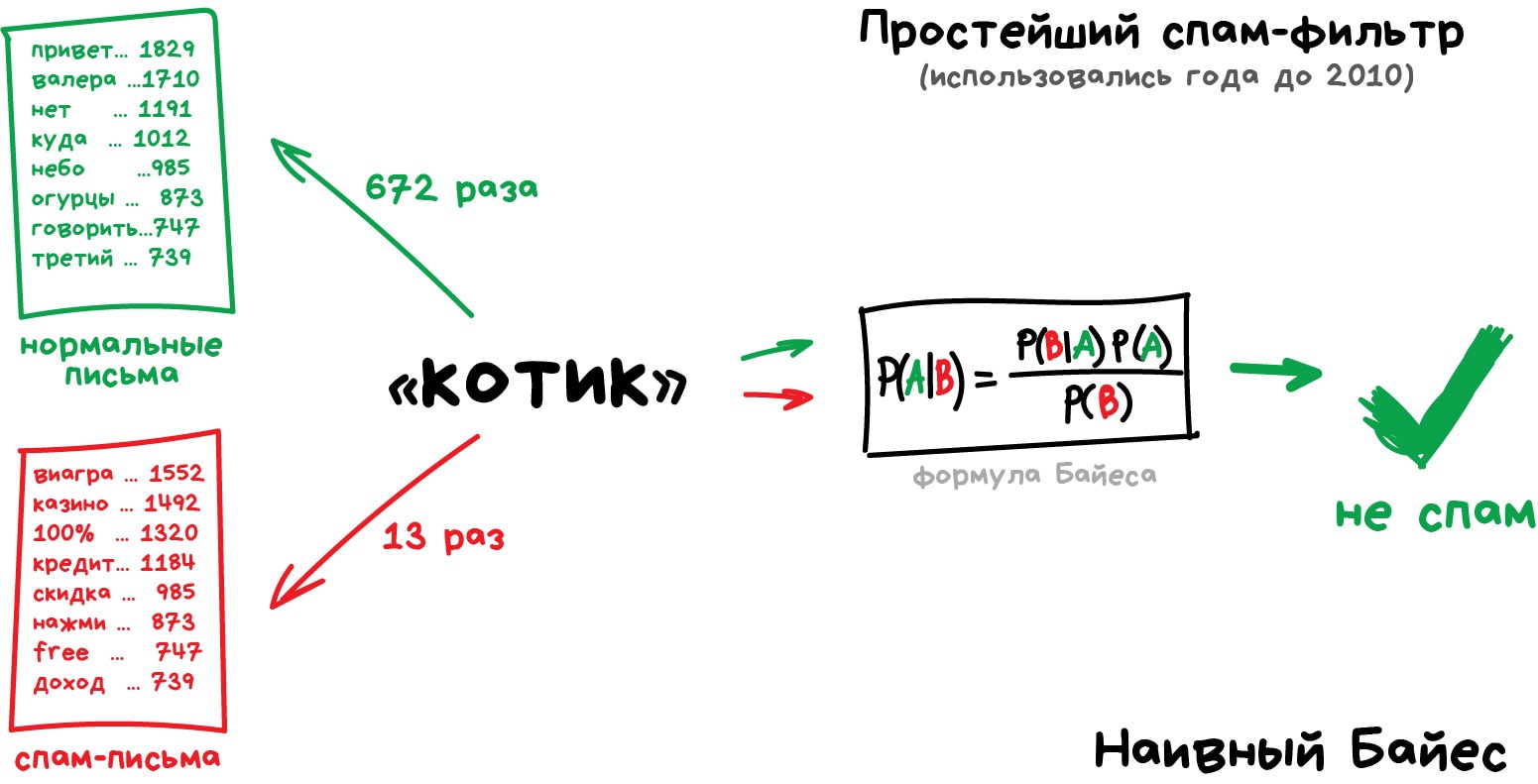
Позже спамеры научились обходить фильтр Байеса, просто вставляя в конец письма много слов с «хорошими» рейтингами. Метод получил ироничное название Отравление Байеса, а фильтровать спам стали другими алгоритмами. Но метод навсегда остался в учебниках как самый простой, красивый и один из первых практически полезных.
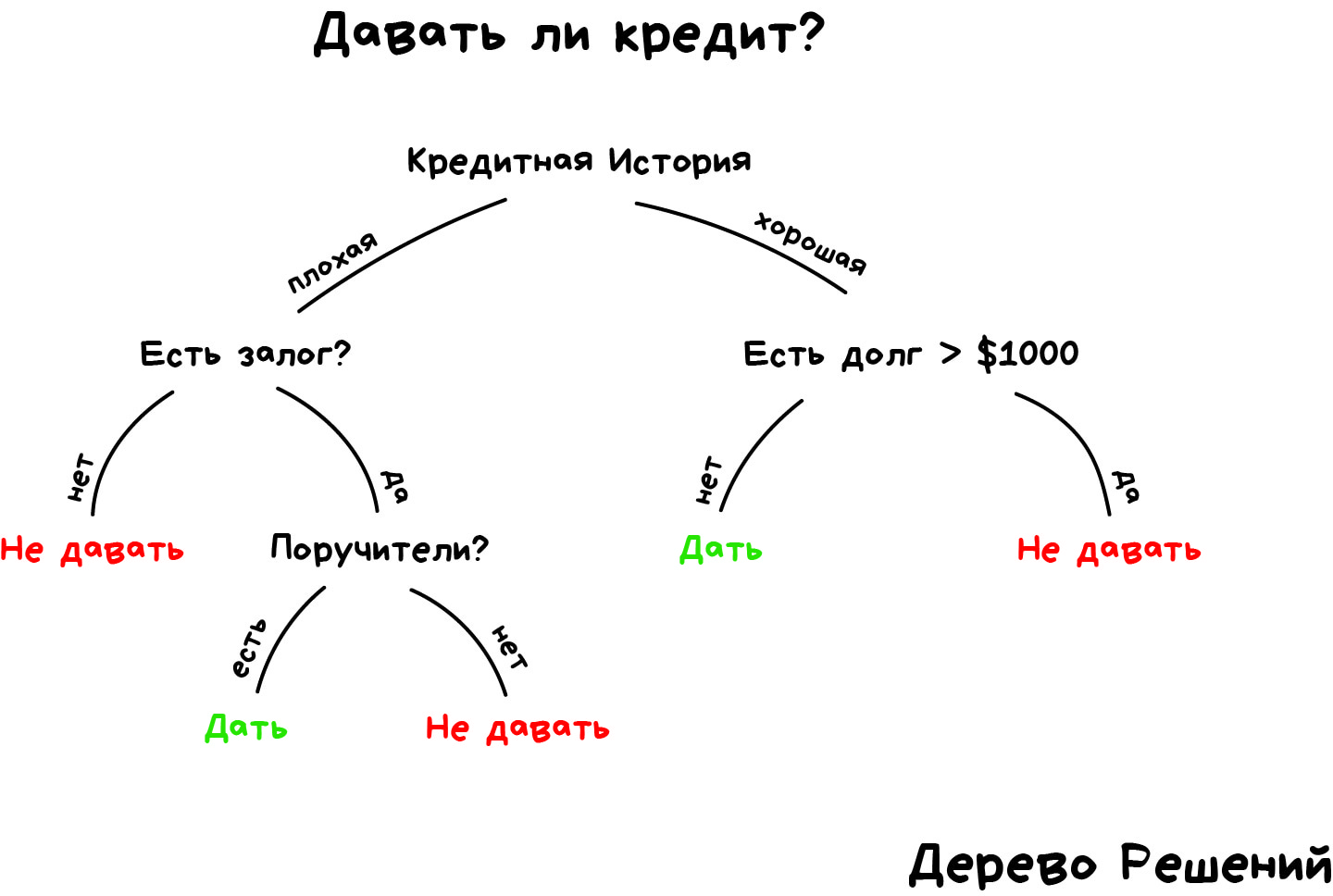
Возьмем другой пример полезной классификации. Вот берёте вы кредит в банке. Как банку удостовериться, вернёте вы его или нет? Точно никак, но у банка есть тысячи профилей других людей, которые уже брали кредит до вас. Там указан их возраст, образование, должность, уровень зарплаты и главное — кто из них вернул кредит, а с кем возникли проблемы.
Да, все догадались, где здесь данные и какой надо предсказать результат. Обучим машину, найдём закономерности, получим ответ — вопрос не в этом. Проблема в том, что банк не может слепо доверять ответу машины, без объяснений. Вдруг сбой, злые хакеры или бухой админ решил скриптик исправить.
Для этой задачи придумали Деревья Решений. Машина автоматически разделяет все данные по вопросам, ответы на которые «да» или «нет». Вопросы могут быть не совсем адекватными с точки зрения человека, например «зарплата заёмщика больше, чем 25934 рубля?», но машина придумывает их так, чтобы на каждом шаге разбиение было самым точным.
Так получается дерево вопросов. Чем выше уровень, тем более общий вопрос. Потом даже можно загнать их аналитикам, и они навыдумывают почему так.
Деревья нашли свою нишу в областях с высокой ответственностью: диагностике, медицине, финансах.
В чистом виде деревья сегодня используют редко, но вот их ансамбли (о которых будет ниже) лежат в основе крупных систем и зачастую уделывают даже нейросети. Например, когда вы задаете вопрос Яндексу, именно толпа глупых деревьев бежит ранжировать вам результаты.
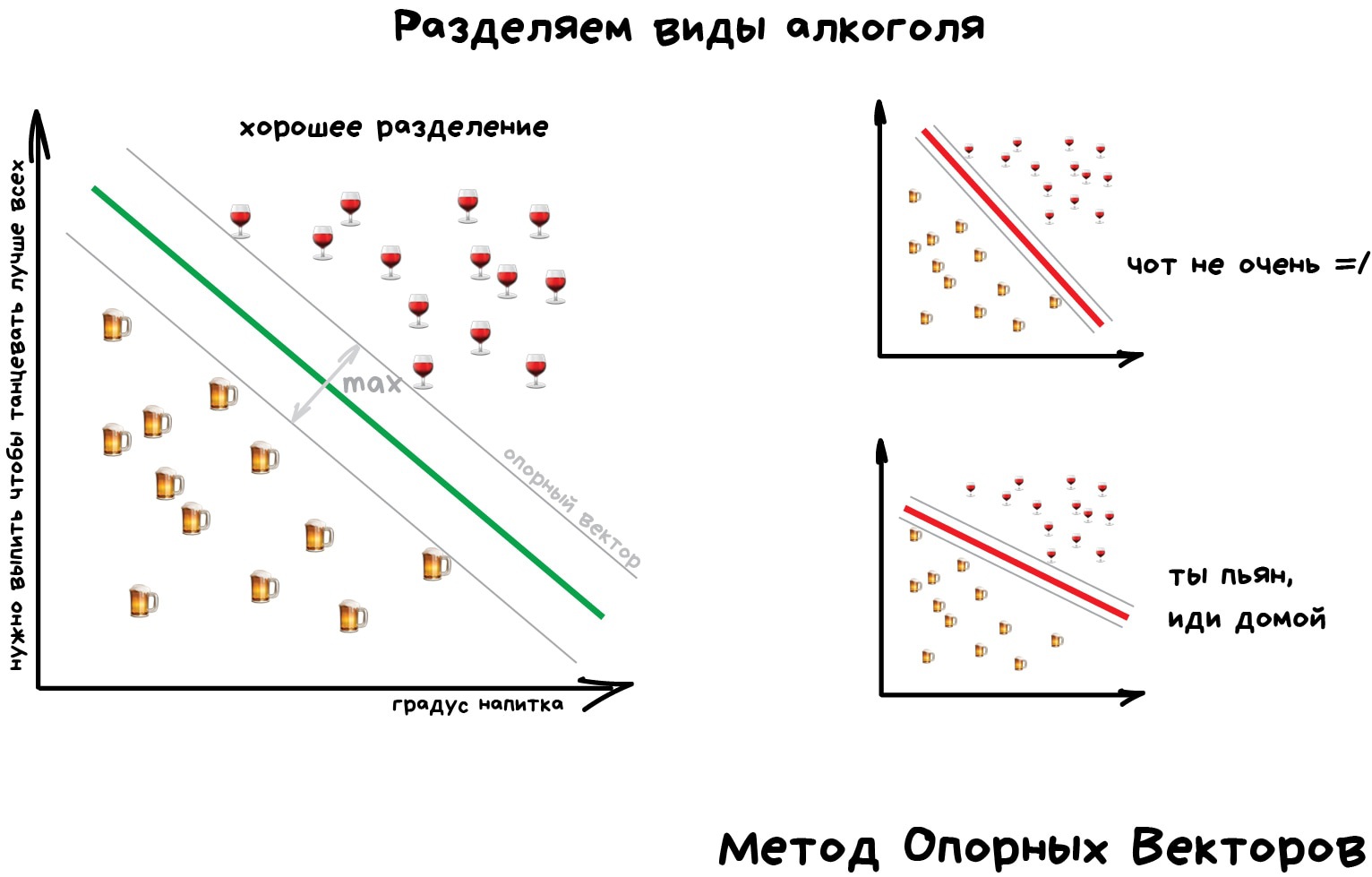
Но самым популярным методом классической классификации заслуженно является Метод Опорных Векторов (SVM). Им классифицировали уже всё: виды растений, лица на фотографиях, документы по тематикам, даже странных Playboy-моделей. Много лет он был главным ответом на вопрос «какой бы мне взять классификатор».
Идея SVM по своей сути проста — он ищет, как так провести две прямые между категориями, чтобы между ними образовался наибольший зазор. На картинке видно нагляднее:
У классификации есть полезная обратная сторона — поиск аномалий. Когда какой-то признак объекта сильно не вписывается в наши классы, мы ярко подсвечиваем его на экране. Сейчас так делают в медицине: компьютер подсвечивает врачу все подозрительные области МРТ или выделяет отклонения в анализах. На биржах таким же образом определяют нестандартных игроков, которые скорее всего являются инсайдерами. Научив компьютер «как правильно», мы автоматически получаем и обратный классификатор — как неправильно.
Сегодня для классификации всё чаще используют нейросети, ведь по сути их для этого и изобрели.
Правило буравчика такое: сложнее данные — сложнее алгоритм. Для текста, цифр, табличек я бы начинал с классики. Там модели меньше, обучаются быстрее и работают понятнее. Для картинок, видео и другой непонятной бигдаты — сразу смотрел бы в сторону нейросетей.
Лет пять назад еще можно было встретить классификатор лиц на SVM, но сегодня под эту задачу сотня готовых сеток по интернету валяются, чо бы их не взять. А вот спам-фильтры как на SVM писали, так и не вижу смысла останавливаться.
Поиск похожих документов? Как это решается классификацией?
one-shot learning, возможно
untech, найти заявления по шапке и заголовку, например.
но я дурак, извините, мне 54 года
и еще ебу собак
имя, Бан
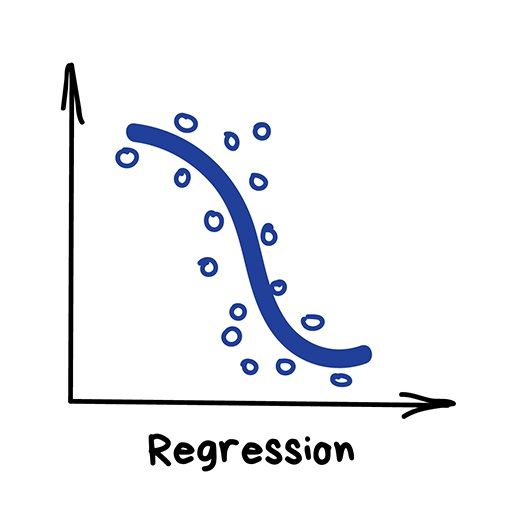
«Нарисуй линию вдоль моих точек. Да, это машинное обучение»
Сегодня используют для:
Популярные алгоритмы: Линейная или Полиномиальная Регрессия
А в спам-фильтре что будет по осям, интересно? или там осей столько, сколько слов?
Все таки для банковского скотринга в задаче дать-не-дать логит-регрессия почти везде, а дерево не сильно популярный алгоритм (переобучение, а бустинг для банков - непонятное черное вердо), тогда как логитка интерпретируема, понятна и хорошо изучена с практического применения, а фичей с нелинейной раздельностью в задачах банковского скоринга (сюрприз) почти и нет
Андрей, не оси будут, а гиперплоскости, скорее всего.
А хотя да, столько же. А разделять всё это будет не знаю как назвать, гиперплоскости ближе всего.
Статья классная, но автор пишет как двоечник. Подучил бы язык, прежде чем писать огромные пасты.. (Именно стилистика и логика текста жутко хромает)
Препод, отвали. Статья годная
Статья и стиль годная вполне.
автор боженька, госпаdе IO/IO
Ёб твоё мать, куда я лезу!
Сорта цветов Породы кошек / собак Вид объекта на фото (Google Cloud Vision API) Распознавание цифр на конвертах Тематика статьи (из заданного множества) Из какого сорта винограда сделано вино (по химическому составу)
Регрессия — та же классификация, только вместо категории мы предсказываем число. Стоимость автомобиля по его пробегу, количество пробок по времени суток, объем спроса на товар от роста компании и.т.д. На регрессию идеально ложатся любые задачи, где есть зависимость от времени.
Регрессию очень любят финансисты и аналитики, она встроена даже в Excel. Внутри всё работает, опять же, банально: машина тупо пытается нарисовать линию, которая в среднем отражает зависимость. Правда, в отличии от человека с фломастером и вайтбордом, делает она это математически точно — считая среднее расстояние до каждой точки и пытаясь всем угодить.
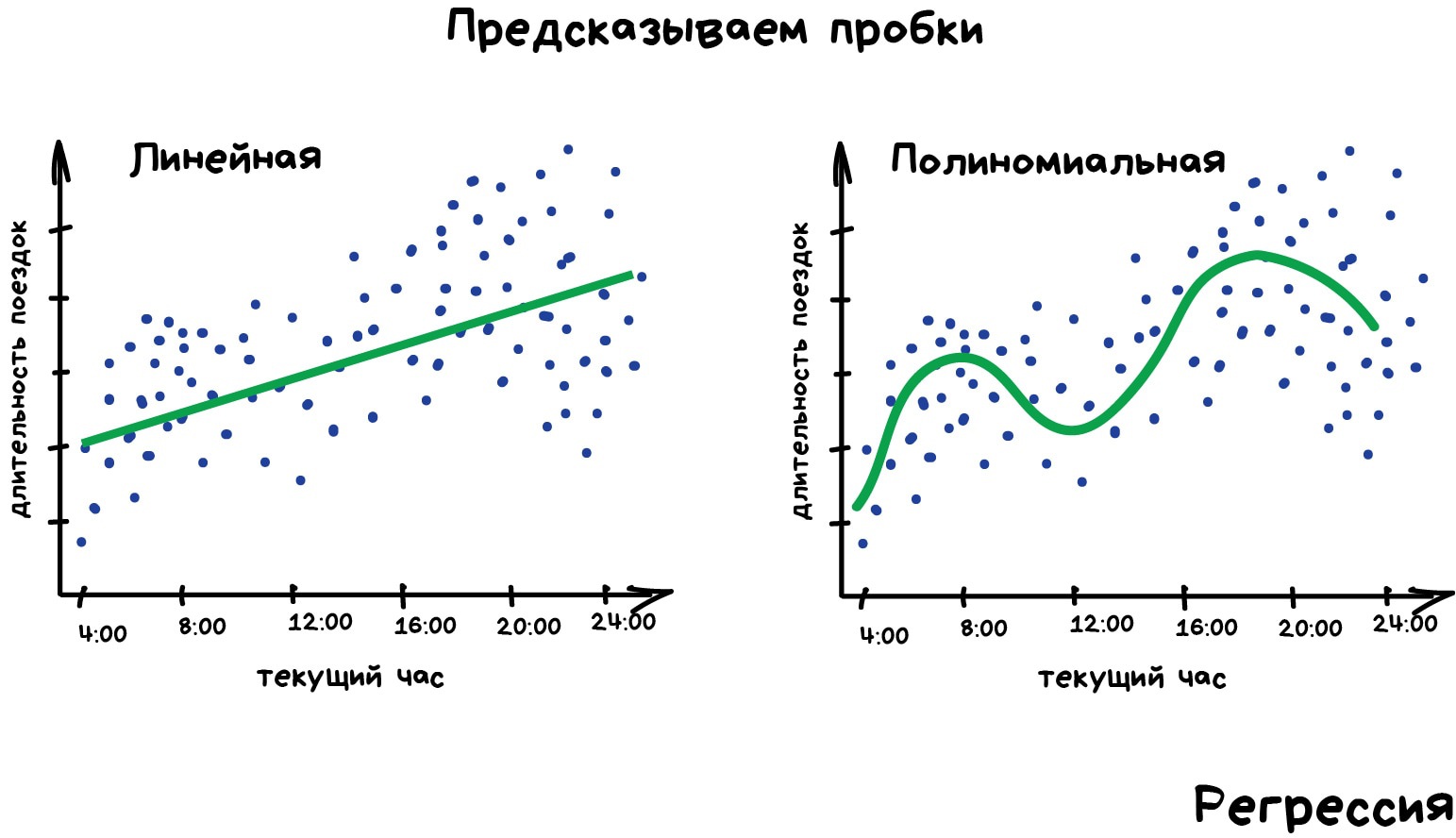
Когда регрессия рисует прямую линию, её называют линейной, когда кривую — полиномиальной. Это два основных вида регрессии, дальше уже начинаются редкоземельные методы. Но так как в семье не без урода, есть Логистическая Регрессия, которая на самом деле не регрессия, а метод классификации, от чего у всех постоянно путаница. Не делайте так.
Схожесть регрессии и классификации подтверждается еще и тем, что многие классификаторы, после небольшого тюнинга, превращаются в регрессоры. Например, мы можем не просто смотреть к какому классу принадлежит объект, а запоминать, насколько он близок — и вот, у нас регрессия.
Для желающих понять это глубже, но тоже простыми словами, рекомендую цикл статей Machine Learning for Humans
Это разве не метод наименьших квадратов с подбором наиболее подходящих функций?
Он самый.
Обучение без учителя (Unsupervised Learning) было изобретено позже, аж в 90-е, и на практике используется реже. Но бывают задачи, где у нас просто нет выбора.
Размеченные данные, как я сказал, дорогая редкость. Но что делать если я хочу, например, написать классификатор автобусов — идти на улицу руками фотографировать миллион сраных икарусов и подписывать где какой? Так и жизнь вся пройдёт, а у меня еще игры в стиме не пройдены.
Когда нет разметки, есть надежда на капитализм, социальное расслоение и миллион китайцев из сервисов типа Яндекс.Толока, которые готовы делать для вас что угодно за пять центов. Так обычно и поступают на практике. А вы думали где Яндекс берёт все свои крутые датасеты?
Либо, можно попробовать обучение без учителя. Хотя, честно говоря, из своей практики я не помню чтобы где-то оно сработало хорошо.
Обучение без учителя, всё же, чаще используют как метод анализа данных, а не как основной алгоритм. Специальный кожаный мешок с дипломом МГУ вбрасывает туда кучу мусора и наблюдает. Кластеры есть? Зависимости появились? Нет? Ну штош, продолжай, труд освобождает. Тыж хотел работать в датасаенсе.
Ах вот где ты название статьи стырил)
в отличии => в отличие
"Схожесть регрессии и классификации подтверждается еще и тем..." – Логистическая Регрессия как раз про это, так что никаких уродов в семье, все логично
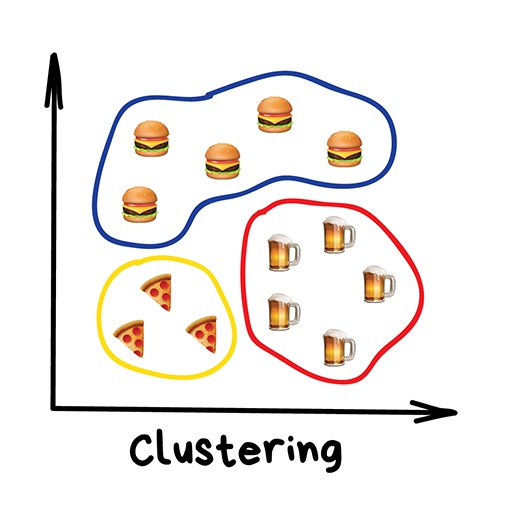
«Разделяет объекты по неизвестному признаку. Машина сама решает как лучше»
Сегодня используют для:
Популярные алгоритмы: Метод K-средних, Mean-Shift, DBSCAN
Если аутоэнкодер считать вариантом без учителя, то он может извлечь фичи из картинок в базу данных для последующего поиска похожих.
Такое обычно делается сиамскими сетями/триплет лоссами, а там нужны размеченные объекты
а аутоэнкодер может дерзать без разметки
"Так и жизнь вся пройдёт, а у меня еще игры в стиме не пройдены" - это очень хорошо :-)
Последний абзац до слёз
Чё-то ни разу не видел, чтобы полиномиальную регрессию так называли. Как-то всё линейная да линейная. Полином девятой степени тоже линейной регрессией называют (везде, где я видел, опять же).
Кластеризация — это классификация, но без заранее известных классов. Она сама ищет похожие объекты и объединяет их в кластеры. Количество кластеров можно задать заранее или доверить это машине. Похожесть объектов машина определяет по тем признакам, которые мы ей разметили — у кого много схожих характеристик, тех давай в один класс.
Отличный пример кластеризации — маркеры на картах в вебе. Когда вы ищете все крафтовые бары в Москве, движку приходится группировать их в кружочки с циферкой, иначе браузер зависнет в потугах нарисовать миллион маркеров.
Более сложные примеры кластеризации можно вспомнить в приложениях iPhoto или Google Photos, которые находят лица людей на фотографиях и группируют их в альбомы. Приложение не знает как зовут ваших друзей, но может отличить их по характерным чертам лица. Типичная кластеризация.
Правда для начала им приходится найти эти самые «характерные черты», а это уже только с учителем.
Сжатие изображений — еще одна популярная проблема. Сохраняя картинку в PNG, вы можете установить палитру, скажем, в 32 цвета. Тогда кластеризация найдёт все «примерно красные» пиксели изображения, высчитает из них «средний красный по больнице» и заменит все красные на него. Меньше цветов — меньше файл.
Проблема только, как быть с цветами типа Cyan ◼︎ — вот он ближе к зеленому или синему? Тут нам поможет популярный алгоритм кластеризации — Метод К-средних (K-Means). Мы случайным образом бросаем на палитру цветов наши 32 точки, обзывая их центроидами. Все остальные точки относим к ближайшему центроиду от них — получаются как бы созвездия из самых близких цветов. Затем двигаем центроид в центр своего созвездия и повторяем пока центроиды не перестанут двигаться. Кластеры обнаружены, стабильны и их ровно 32 как и надо было.
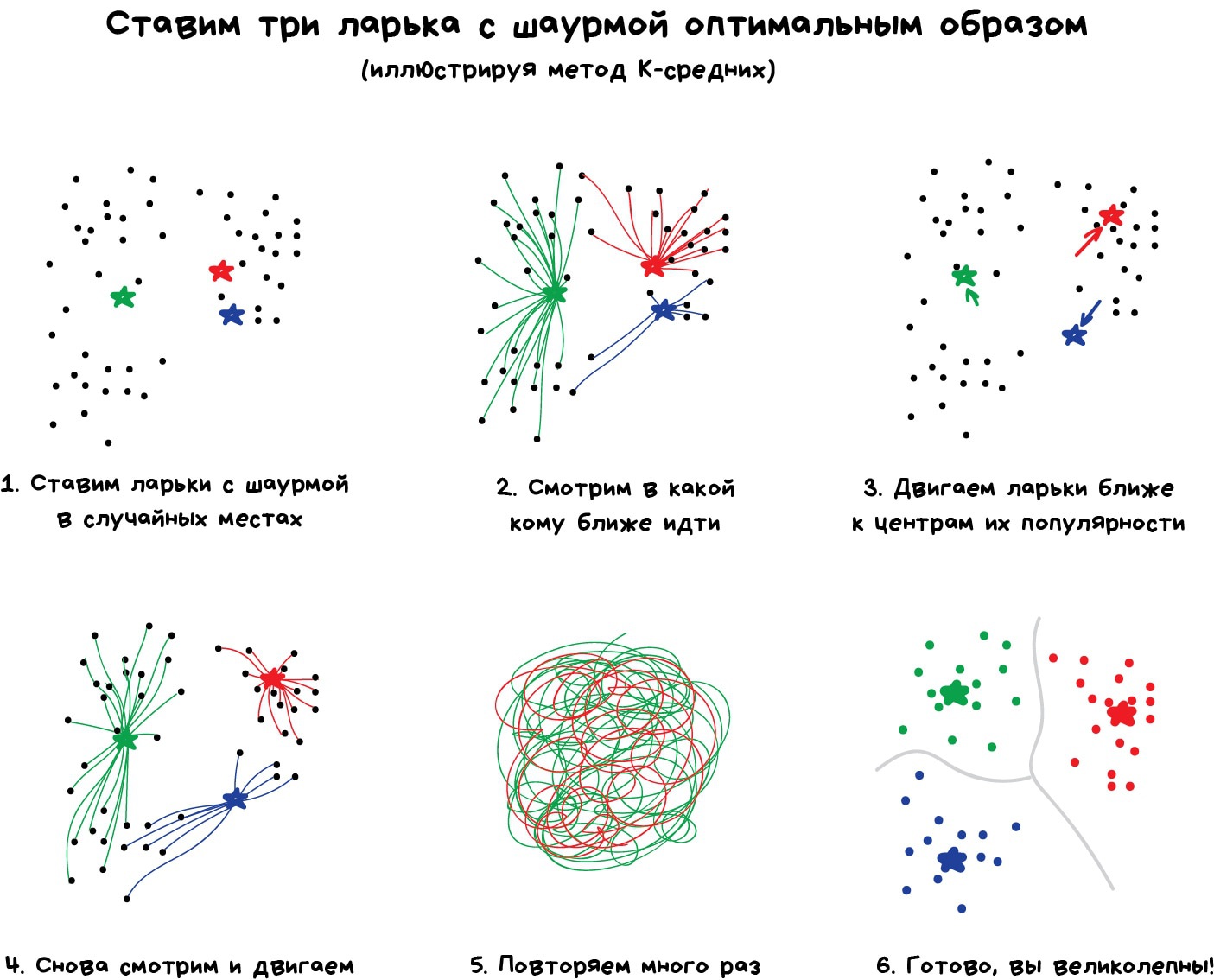
Искать центроиды удобно и просто, но в реальных задачах кластеры могут быть совсем не круглой формы. Вот вы геолог, которому нужно найти на карте схожие по структуре горные породы — ваши кластеры не только будут вложены друг в друга, но вы ещё и не знаете сколько их вообще получится.
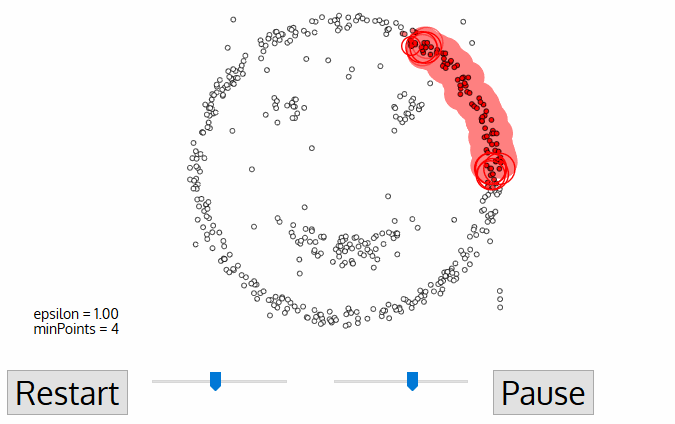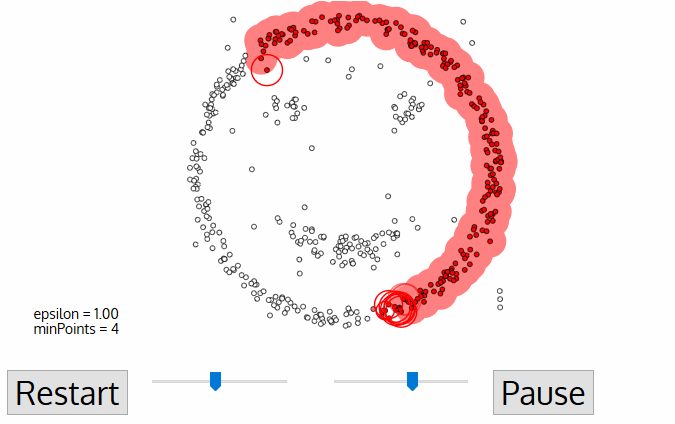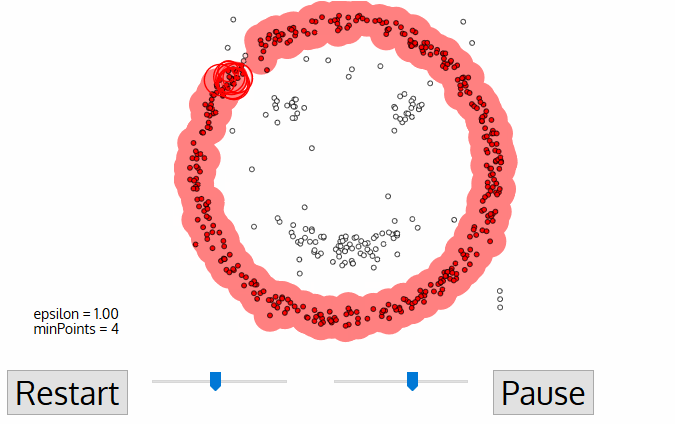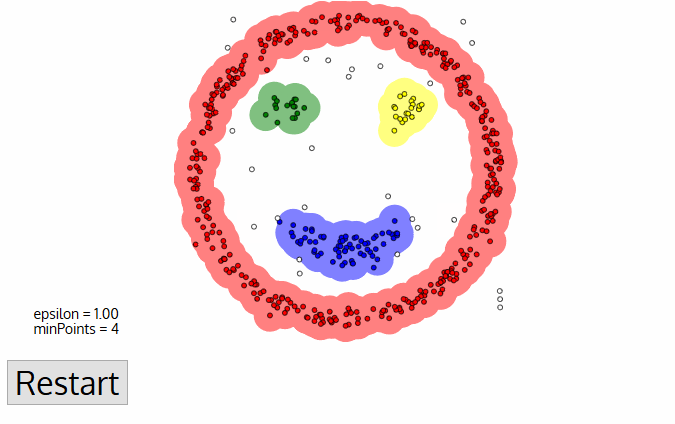
Хитрым задачам — хитрые методы. DBSCAN, например. Он сам находит скопления точек и строит вокруг кластеры. Его легко понять, если представить, что точки — это люди на площади. Находим трёх любых близко стоящих человека и говорим им взяться за руки. Затем они начинают брать за руку тех, до кого могут дотянуться. Так по цепочке, пока никто больше не сможет взять кого-то за руку — это и будет первый кластер. Повторяем, пока не поделим всех. Те, кому вообще некого брать за руку — это выбросы, аномалии. В динамике выглядит довольно красиво:
Интересующимся кластеризацией рекомендую статью The 5 Clustering Algorithms Data Scientists Need to Know
Как и классификация, кластеризация тоже может использоваться как детектор аномалий. Поведение пользователя после регистрации резко отличается от нормального? Заблокировать его и создать тикет саппорту, чтобы проверили бот это или нет. При этом нам даже не надо знать, что есть «нормальное поведение» — мы просто выгружаем все действия пользователей в модель, и пусть машина сама разбирается кто тут нормальный.
Работает такой подход, по сравнению с классификацией, не очень. Но за спрос не бьют, вдруг получится.
ахуенная статья
Да, хорошая статья. Всё по полочкам в голове у автора уложено.
«Собирает конкретные признаки в абстракции более высокого уровня»
Сегодня используют для:
Популярные алгоритмы: Метод главных компонент (PCA), Сингулярное разложение (SVD), Латентное размещение Дирихле (LDA), Латентно-семантический анализ (LSA, pLSA, GLSA), t-SNE (для визуализации)
а если большинство пользователей сайта боты?)) Машина будет банить норм юзеров? "Негоже кожаным на этом форуме сидеть!"
Kato, одновременно боты не засядут большинством, за "легитимных" пользователей примут тестировщиков, например.
Друзья, понял принцип действия метода k-средних на примере ларьков с шаурмой. Понял объяснение в видео по ссылке на ютьюб, которую автор дал выше. Но не могу понять принцип использования метода для сжатия изображения в png 32 цветов. Объясните, пожалуйста!
Loks, как я понял. Берётся палитра. На неё кидают 32 ларька с шаурмой. Потом кидают на палитру цвета с картинки( каждый цвет, имеющийся на картинки). Алгоритм действует, как шаурмечны в самые оптимальные места становится. На какой цвет в палитре встала шаурмечна, на тот цвет заменяются все его посетители. // че не правильно пишите.
Спасибо комментатору выше за попытку объяснить. Я попробовал разобраться и понял это так (пункты 1-6 соответствуют пунктам на иллюстрации Вастрика): 0. Каждый пиксель изображения, обладая тремя координатами от 0 до 256 (Red, Green, Blue) располагается в 3D пространстве. Представить это поможет изображение https://www.cse.wustl.edu/~m.neumann/sp2016/cse517/lecturenotes/images/c22kmeans/TimoKmeans.png Всего у нас получается 256 * 256 * 256 = 16 777 216 возможных точек, где может оказаться каждый пиксель изображения, и столько же уникальных цветов(!). А нам-то нужно всего 32. 1. Мы рандомно закидываем в это 3D-пространство 32 центроида (пока еще не обладающие цветовым кодом. Пока что они нужны нам только для первичной кластеризации "3D-взвеси") 2. Далее смотрим, к какому из центроидов каждый пиксель нашей "взвеси" находится ближе. То есть тупо по трем дименшенам. Получаем кластеры первого порядка 3. Далее перемещаем центроиды внутри наших получившихся 32 кластеров первого порядка. Перемещаем так, чтобы центроиды реально были центроидами и были равноудалены от каждой точки в кластере 4. Смотрим, не изменили ли некоторые пиксели принадлежность к кластеру. Ведь в предыдущем шаге 32 центроида переместлись. Наверняка некоторые пиксели оказались теперь ближе к другому центроиду. Границы кластеров чуть-чуть изменились после этого шага за счет смены некоторыми пикселями принадлежности к кластеру 5. Повторяются шаги 3-4 до тех пор, пока не окажется, что центроиды уже не двигаются на шаге 3. То есть они и так уже равноудалены. Когда центроиды окончательно останавливаются, пункт 4 уже неактуален, т.к. изменений нет. Переходим к пункту 6 6. Прекращение перемещения центроидов означает, что у нас есть хорошие сбитые математически выверенные кластеры, сформированные вокруг них. 7. Теперь мы просто смотрим координаты каждого из 32 центроидов. Например (38, 228, 238). И все пиксели, которые у нас были "скластеризованы" вокруг него, перекрашиваем в данный RGB-цвет. 8. Возвращаем все пиксели на место. Готово. У вас 32-цветовое изображение. Вы великолепны! Если где-то ошибся, пардон. Исправьте, если не прав. PS Кстати, нашел ссылку на изображение, содержащее все 16 777 216 RGB-цветов: http://davidnaylor.org/temp/all16777216rgb-diagonal.png
Блин, все переносы строки, которые отображались в форме отправки комментария, похерились при отправке. Извините.
@Loks, немного не по теме, но если работать с цветами предстоит на практике, то цветовое пространство лучше взять не 3D, а хотя бы CIELAB. Цветовое пространство - штука нелинейная (из-за особенностей восприятия цветов глазом), но есть алгоритмы, вычисляющие цветовые расстояние в виде чисел (от 0 до 1, например), которые можно затем по-простому сравнивать.
Hatenaki, работа с цветами мне вряд ли предстоит. Я просто заморочился, чтобы понять для себя. Но спасибо за комментарий, плюсую :)
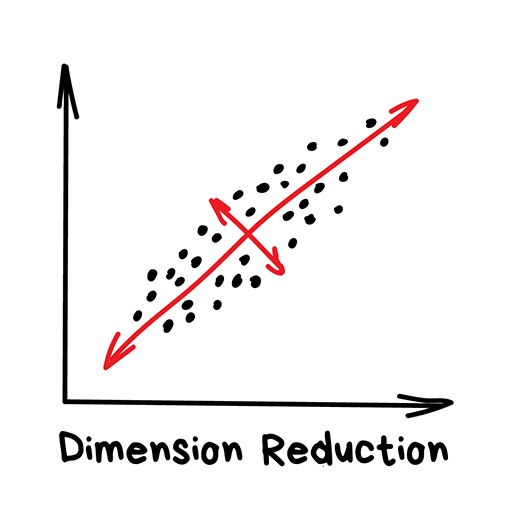
Изначально это были методы хардкорных Data Scientist'ов, которым сгружали две фуры цифр и говорили найти там что-нибудь интересное. Когда просто строить графики в экселе уже не помогало, они придумали напрячь машины искать закономерности вместо них. Так у них появились методы, которые назвали Dimension Reduction или Feature Learning.

Для нас практическая польза их методов в том, что мы можем объединить несколько признаков в один и получить абстракцию. Например, собаки с треугольными ушами, длинными носами и большими хвостами соединяются в полезную абстракцию «овчарки». Да, мы теряем информацию о конкретных овчарках, но новая абстракция всяко полезнее этих лишних деталей. Плюс, обучение на меньшем количестве размерностей идёт сильно быстрее.
Инструмент на удивление хорошо подошел для определения тематик текстов (Topic Modelling). Мы смогли абстрагироваться от конкретных слов до уровня смыслов даже без привлечения учителя со списком категорий. Алгоритм назвали Латентно-семантический анализ (LSA), и его идея была в том, что частота появления слова в тексте зависит от его тематики: в научных статьях больше технических терминов, в новостях о политике — имён политиков. Да, мы могли бы просто взять все слова из статей и кластеризовать, как мы делали с ларьками выше, но тогда мы бы потеряли все полезные связи между словами, например, что батарейка и аккумулятор, означают одно и то же в разных документах.
Точность такой системы — полное дно, даже не пытайтесь.
Нужно как-то объединить слова и документы в один признак, чтобы не терять эти скрытые (латентные) связи. Отсюда и появилось название метода. Оказалось, что Сингулярное разложение (SVD) легко справляется с этой задачей, выявляя для нас полезные тематические кластеры из слов, которые встречаются вместе.
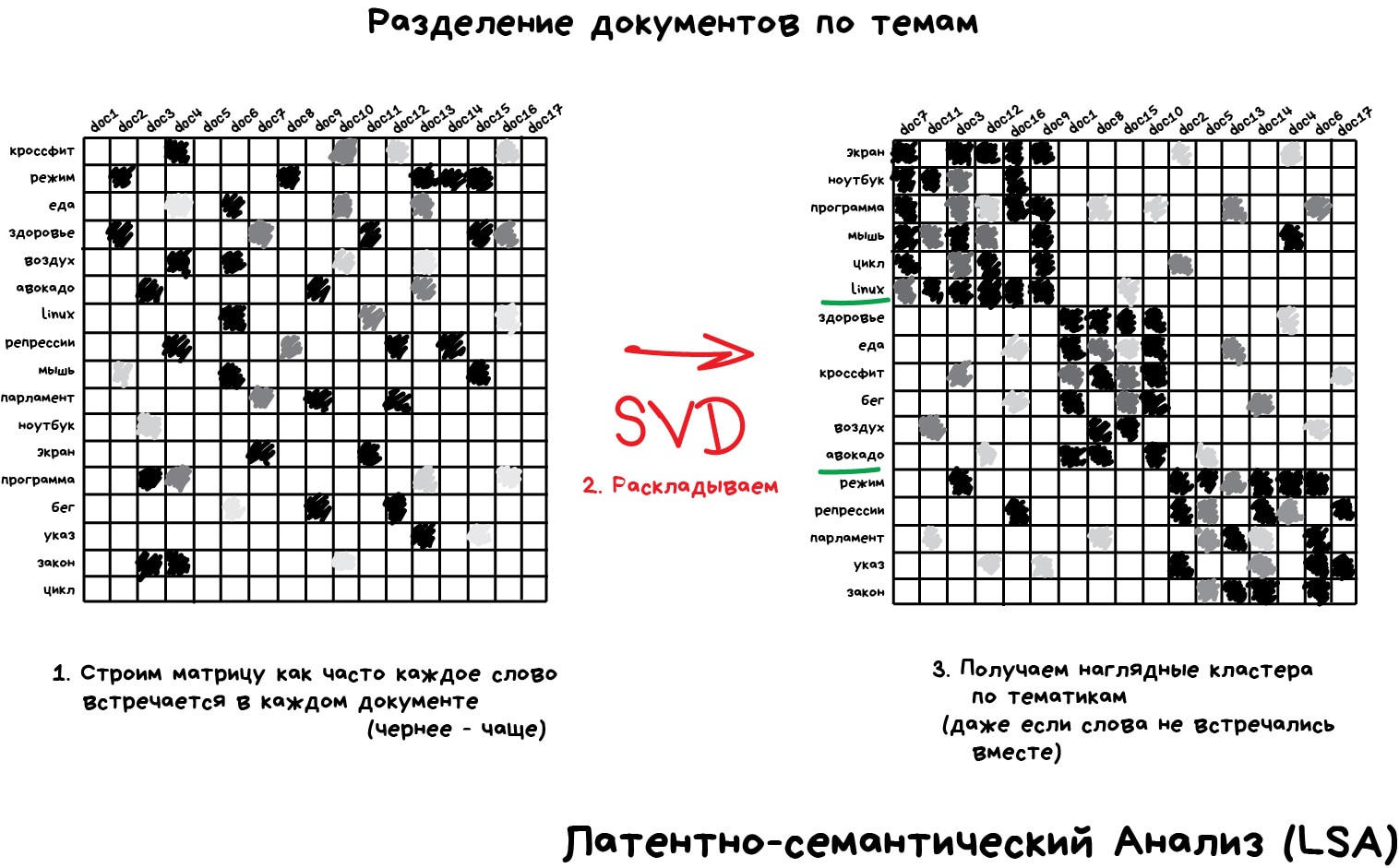
Для понимания рекомендую статью Как уменьшить количество измерений и извлечь из этого пользу, а практическое применение хорошо описано в статье Алгоритм LSA для поиска похожих документов.
Другое мега-популярное применение метода уменьшения размерности нашли в рекомендательных системах и коллаборативной фильтрации (у меня был пост про их виды). Оказалось, если абстрагировать ими оценки пользователей фильмам, получается неплохая система рекомендаций кино, музыки, игр и чего угодно вообще.
Полученная абстракция будет с трудом понимаема мозгом, но когда исследователи начали пристально рассматривать новые признаки, они обнаружили, что какие-то из них явно коррелируют с возрастом пользователя (дети чаще играли в Майнкрафт и смотрели мультфильмы), другие с определёнными жанрами кино, а третьи вообще с синдромом поиска глубокого смысла.
Машина, не знавшая ничего кроме оценок пользователей, смогла добраться до таких высоких материй, даже не понимая их. Достойно. Дальше можно проводить соцопросы и писать дипломные работы о том, почему бородатые мужики любят дегенеративные мультики.
На эту тему есть неплохая лекция Яндекса — Как работают рекомендательные системы
на остановке, пожалуйста. я не втащу эту статью за раз.
«Ищет закономерности в потоке заказов»
Сегодня используют для:
Популярные алгоритмы: Apriori, Euclat, FP-growth
Сюда входят все методы анализа продуктовых корзин, стратегий маркетинга и других последовательностей.
Предположим, покупатель берёт в дальнем углу магазина пиво и идёт на кассу. Стоит ли ставить на его пути орешки? Часто ли люди берут их вместе? Орешки с пивом, наверное да, но какие ещё товары покупают вместе? Когда вы владелец сети гипермаркетов, ответ для вас не всегда очевиден, но одно тактическое улучшение в расстановке товаров может принести хорошую прибыль.
То же касается интернет-магазинов, где задача еще интереснее — за каким товаром покупатель вернётся в следующий раз?
По непонятным мне причинам, поиск правил — самая хреново продуманная категория среди всех методов обучения. Классические способы заключаются в тупом переборе пар всех купленных товаров с помощью деревьев или множеств. Сами алгоритмы работают наполовину — могут искать закономерности, но не умеют обобщать или воспроизводить их на новых примерах.
В реальности каждый крупный ритейлер пилит свой велосипед, и никаких особых прорывов в этой области я не встречал. Максимальный уровень технологий здесь — запилить систему рекомендаций, как в пункте выше. Хотя может я просто далёк от этой области, расскажите в комментах, кто шарит?
*Association :)
Дайте ссылку, кто и как анализирует паттерны поведения на веб-сайтах, кроме Яндекса и Гугла?
Миша А, дал тебе ссылку за щеку, проверяй
«Брось робота в лабиринт и пусть ищет выход»
Сегодня используют для:
Популярные алгоритмы: Q-Learning, SARSA, DQN, A3C, Генетический Алгоритм
воистину, даже такие гиганты как PornHub ужасно справляются с рекомендованным контентом
Точно подмечено!! Я купил что мне надо, а они предлагают еще то же))) Балдеж
он просто хочет чтобы пользователи попробовали что-то новое
никаких особых прорывов в этой области я не встречал Эта задача неплохо и дёшево решается другими инструментами, не требующими большого количества проходов по ещё большему датасету. Теми же нейросетями и кластеризацией, например. Потому и нет прорывов
Для любителей микро-экономики -- видимо создатели наблюдаемых систем никогда не проходили модели предпочтений -- они предполагают что надо вдогон напихивать товары-заместители, а имеет смысл -- товары комплементарные, совместно-используемые, как холодильник после покупки новой квартиры или ремонта.
Вообще для этого и придуманы эти все карточки скидок, братан. Они, конечно, приманивают по четвергам бабушек на дешевые говьяжьи анусы, но их настоящая цель — привязать поведение (покупки) к каким-то более-менее конкретным переменным (пол, возраст, семейное положение, расстояние от магазина) картодержателя. Так начинают выводить категории пользователей, ебошить multiple regression и страдать. Но в онлайне. при всех инструментах, большинство просто слишком ленивые, чтобы делать нормальный post purchase и не спамить диванами после покупки дивана.
Если за рекомендацию получаешь баллы, то это тоже нормальный выход.
Это была всего лишь первая часть??? Погодите, сейчас соберу ошмётки разума вобратно
Али: Дорогой пользователь, вы купили у нас цветной парик и перчатки с дырочками; предлагаем вам очень дешёвый трактор, всего 20000$
шо то хуйня, шо эта, обе хуйни
Помимо построения обычных ассоциаций, имеется своего рода "дерево", где указаны связи между товарами (для данных, берется родительская и дочерняя категория товаров). Так идет подбор не по всем товарам, а только по тем, которые находятся на одном уровне с купленным товаром (либо с тем, который был в комбинации). Метод: Market Basket
на картинке опечатка, association.
Наконец мы дошли до вещей, которые, вроде, выглядят как настоящий искусственный интеллект. Многие авторы почему-то ставят обучение с подкреплением где-то между обучением с учителем и без, но я не понимаю чем они похожи. Названием?
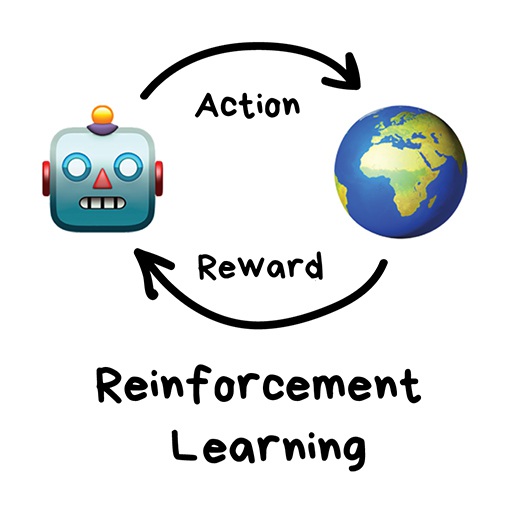
Обучение с подкреплением используют там, где задачей стоит не анализ данных, а выживание в реальной среде.
Средой может быть даже видеоигра. Роботы, играющие в Марио, были популярны еще лет пять назад. Средой может быть реальный мир. Как пример — автопилот Теслы, который учится не сбивать пешеходов, или роботы-пылесосы, главная задача которых — напугать вашего кота до усрачки с максимальной эффективностью.
Знания об окружающем мире такому роботу могут быть полезны, но чисто для справки. Не важно сколько данных он соберёт, у него всё равно не получится предусмотреть все ситуации. Потому его цель — минимизировать ошибки, а не рассчитать все ходы. Робот учится выживать в пространстве с максимальной выгодой: собранными монетками в Марио, временем поездки в Тесле или количеством убитых кожаных мешков хихихих.
Выживание в среде и есть идея обучения с подкреплением. Давайте бросим бедного робота в реальную жизнь, будем штрафовать его за ошибки и награждать за правильные поступки. На людях норм работает, почему бы на и роботах не попробовать.
Умные модели роботов-пылесосов и самоуправляемые автомобили обучаются именно так: им создают виртуальный город (часто на основе карт настоящих городов), населяют случайными пешеходами и отправляют учиться никого там не убивать. Когда робот начинает хорошо себя чувствовать в искусственном GTA, его выпускают тестировать на реальные улицы.
Запоминать сам город машине не нужно — такой подход называется Model-Free. Конечно, тут есть и классический Model-Based, но в нём нашей машине пришлось бы запоминать модель всей планеты, всех возможных ситуаций на всех перекрёстках мира. Такое просто не работает. В обучении с подкреплением машина не запоминает каждое движение, а пытается обобщить ситуации, чтобы выходить из них с максимальной выгодой.

Помните новость пару лет назад, когда машина обыграла человека в Го? Хотя незадолго до этого было доказано, что число комбинаций физически невозможно просчитать, ведь оно превышает количество атомов во вселенной. То есть если в шахматах машина реально просчитывала все будущие комбинации и побеждала, с Го так не прокатывало. Поэтому она просто выбирала наилучший выход из каждой ситуации и делала это достаточно точно, чтобы обыграть кожаного ублюдка.
Эта идея лежит в основе алгоритма Q-learning и его производных (SARSA и DQN). Буква Q в названии означает слово Quality, то есть робот учится поступать наиболее качественно в любой ситуации, а все ситуации он запоминает как простой марковский процесс.
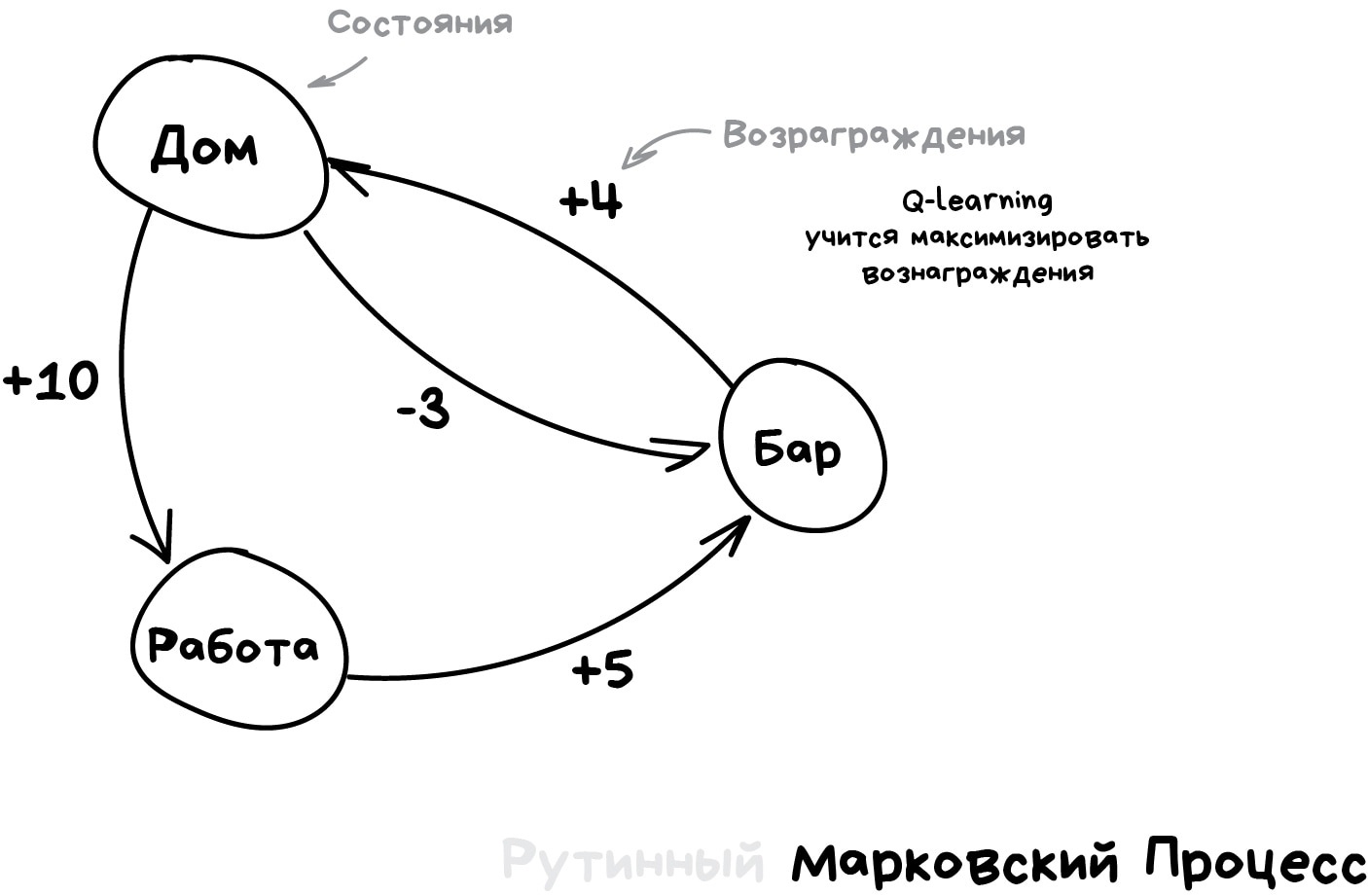
Машина прогоняет миллионы симуляций в среде, запоминая все сложившиеся ситуации и выходы из них, которые принесли максимальное вознаграждение. Но как понять, когда у нас сложилась известная ситуация, а когда абсолютно новая? Вот самоуправляемый автомобиль стоит у перекрестка и загорается зелёный — значит можно ехать? А если справа мчит скорая помощь с мигалками?
Ответ — хрен знает, никак, магии не бывает, исследователи постоянно этим занимаются, изобретая свои костыли. Одни прописывают все ситуации руками, что позволяет им обрабатывать исключительные случаи типа проблемы вагонетки. Другие идут глубже и отдают эту работу нейросетям, пусть сами всё найдут. Так вместо Q-learning'а у нас появляется Deep Q-Network (DQN).
Reinforcement Learning для простого обывателя выглядит как настоящий интеллект. Потому что ух ты, машина сама принимает решения в реальных ситуациях! Он сейчас на хайпе, быстро прёт вперёд и активно пытается в нейросети, чтобы стать еще точнее (а не стукаться о ножку стула по двадцать раз).
Потому если вы любите наблюдать результаты своих трудов и хотите популярности — смело прыгайте в методы обучения с подкреплением (до чего ужасный русский термин, каждый раз передёргивает) и заводите канал на ютюбе! Даже я бы смотрел.
Помню, у меня в студенчестве были очень популярны генетические алгоритмы (по ссылке прикольная визуализация). Это когда мы бросаем кучу роботов в среду и заставляем их идти к цели, пока не сдохнут. Затем выбираем лучших, скрещиваем, добавляем мутации и бросаем еще раз. Через пару миллиардов лет должно получиться разумное существо. Теория эволюции в действии.
Так вот, генетические алгоритмы тоже относятся к обучению с подкреплением, и у них есть важнейшая особенность, подтвержденная многолетней практикой — они нахер никому не нужны.
Человечеству еще не удалось придумать задачу, где они были бы реально эффективнее других. Зато отлично заходят как студенческие эксперименты и позволяют кадрить научруков «достижениями» особо не заморачиваясь. На ютюбе тоже зайдёт.
Действительно серьёзная область с кучей скрытых от широкой публики результатов и, что особенно интересно, непосредственно стыкующая иплицитные и эксплицитные методы ИИ. Для начала смотреть Formal Concept Analysis, далее много всего...
Шутка про диваны )))) всегда думал что за тупые ) я уже купил диван, зачем мне еще один диван. Лучше бы предлагали что нибудь к дивану. там накидки на диван, пылесос для дивана и т.п.
Если рассматривать шутку про диван - я думаю, они просто не знают, купил я диван или нет. Поэтому навсякий случай дублируют мой поиск диванов рекламой.
«Куча глупых деревьев учится исправлять ошибки друг друга»
Сегодня используют для:
Популярные алгоритмы: Random Forest, Gradient Boosting
уже целый день читаю, этот текст когда-нибудь закончится?
лажа, в шахматах число вариантов 10E+120, никакими переборами выиграть невозможно. Вариантов больше, чем атомов в видимой вселенной
лол, "перебрать невозможно"
Где-то слышал, что генетические алгоритмы хороши в задачах типа нахождения идеальной формы крыльчатки в турбинах и активно там применяются.
Единственное что я пока понял что я кожаный ублюдок. Пойду займусь практикой ML
Автор, я хочу от тебя детей
В шахматах с каждым ходом число варианотв сокращается
В шахматах все варианты не просчитанны, для тех кто интересуется - существуют таблицы окончаний (таблицы Налимова), там для 7ми фигурных кажется уже терабайты данных. Все возможные варианты просчитаны в шашках
8 ми фигурные уже будут исчесляться Петабайтами
генетические алгоритмы применяются. есть, например, генетический оптимизатор запросов в postgresql, который рабтает конечное время, в отличие от тупого перебора всех вариантов. знаю как минимум одну компанию, которая использует генетику для оптимизации логистики. у нас генетика немного используется для расчета расписаний.
В обучении с подкреплением бывают возникают забавные ситуации, читал про нейросетку-читера, у которой была задача создать "персонажа", который быстрее всего преодолевал бы какое-то расстояние, и она в итоге придумала растить очень-очень высокого перса и тупо его ронять :)
Ору с роботов-пылесосов и пожар.
Может я простой обыватель, но по-моему Reinforcement Learning - это и правда круто!
Теперь к настоящим взрослым методам. Ансамбли и нейросети — наши главные бойцы на пути к неминуемой сингулярности. Сегодня они дают самые точные результаты и используются всеми крупными компаниями в продакшене. Только о нейросетях трещат на каждом углу, а слова «бустинг» и «бэггинг», наверное, пугают только хипстеров с теккранча.
При всей их эффективности, идея до издевательства проста. Оказывается, если взять несколько не очень эффективных методов обучения и обучить исправлять ошибки друг друга, качество такой системы будет аж сильно выше, чем каждого из методов по отдельности.
Причём даже лучше, когда взятые алгоритмы максимально нестабильны и сильно плавают от входных данных. Поэтому чаще берут Регрессию и Деревья Решений, которым достаточно одной сильной аномалии в данных, чтобы поехала вся модель. А вот Байеса и K-NN не берут никогда — они хоть и тупые, но очень стабильные.
Ансамбль можно собрать как угодно, хоть случайно нарезать в тазик классификаторы и залить регрессией. За точность, правда, тогда никто не ручается. Потому есть три проверенных способа делать ансамбли.
Стекинг Обучаем несколько разных алгоритмов и передаём их результаты на вход последнему, который принимает итоговое решение. Типа как девочки сначала опрашивают всех своих подружек, чтобы принять решение встречаться с парнем или нет.
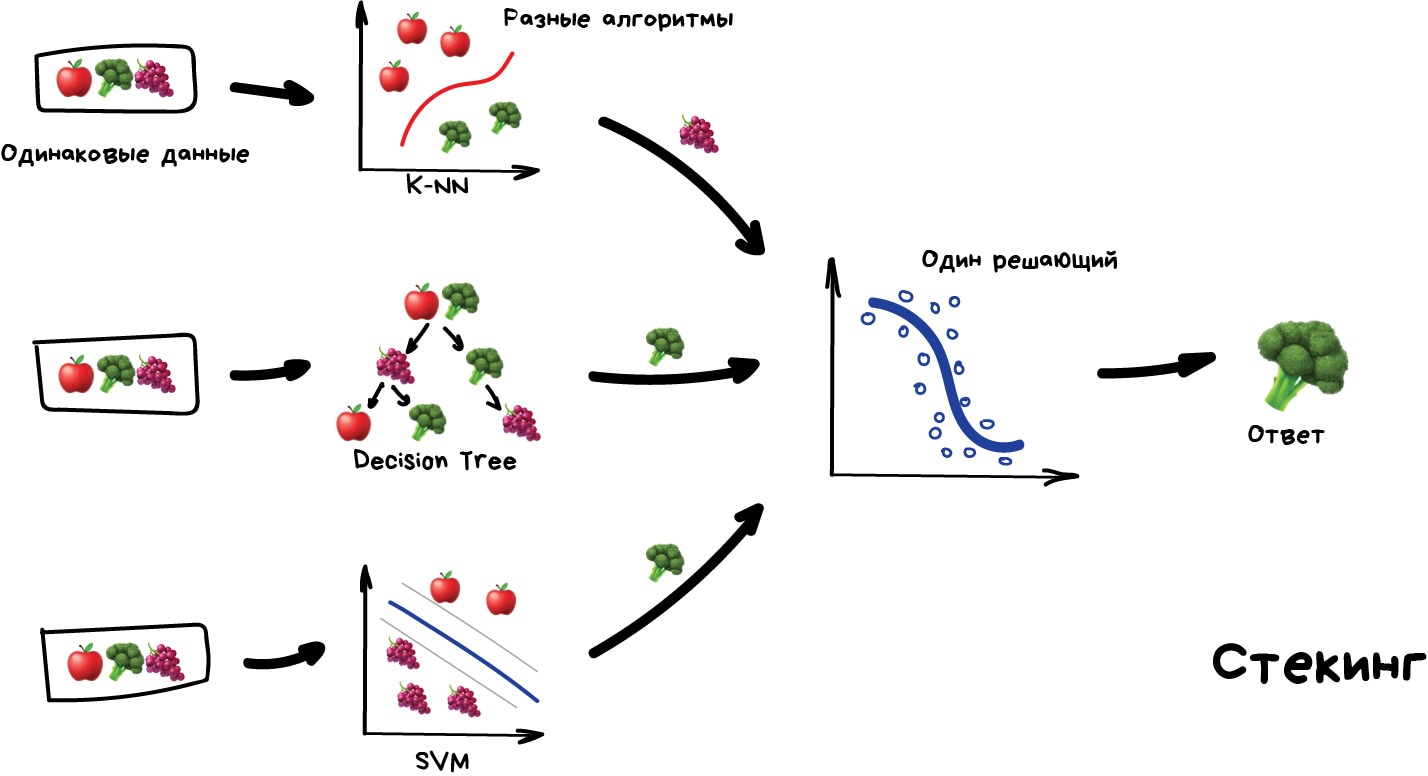
Ключевое слово — разных алгоритмов, ведь один и тот же алгоритм, обученный на одних и тех же данных не имеет смысла. Каких — ваше дело, разве что в качестве решающего алгоритма чаще берут регрессию.
Чисто из опыта — стекинг на практике применяется редко, потому что два других метода обычно точнее.
Беггинг Он же Bootstrap AGGregatING. Обучаем один алгоритм много раз на случайных выборках из исходных данных. В самом конце усредняем ответы.
Данные в случайных выборках могут повторяться. То есть из набора 1-2-3 мы можем делать выборки 2-2-3, 1-2-2, 3-1-2 и так пока не надоест. На них мы обучаем один и тот же алгоритм несколько раз, а в конце вычисляем ответ простым голосованием.
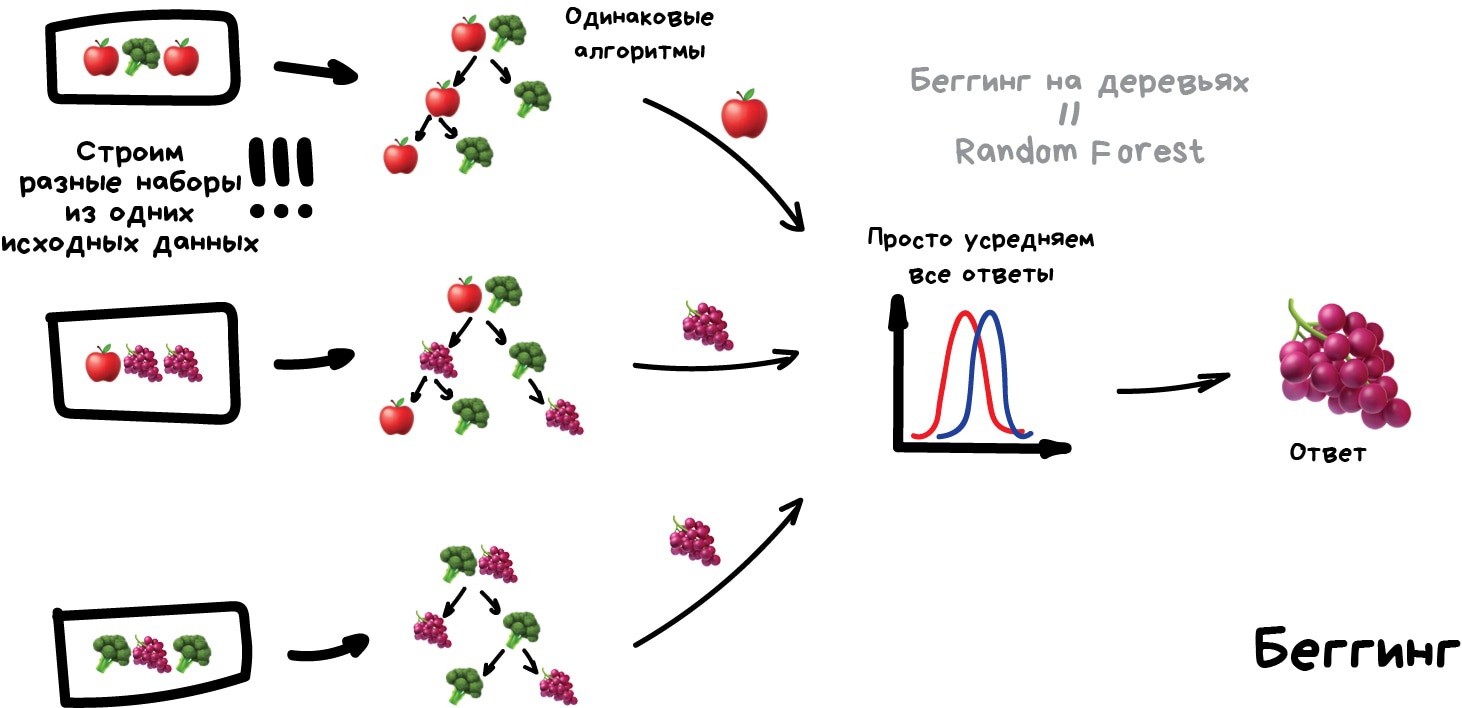
Самый популярный пример беггинга — алгоритм Random Forest, беггинг на деревьях, который и нарисован на картинке. Когда вы открываете камеру на телефоне и видите как она очертила лица людей в кадре желтыми прямоугольниками — скорее всего это их работа. Нейросеть будет слишком медлительна в реальном времени, а беггинг идеален, ведь он может считать свои деревья параллельно на всех шейдерах видеокарты.
Дикая способность параллелиться даёт беггингу преимущество даже над следующим методом, который работает точнее, но только в один поток. Хотя можно разбить на сегменты, запустить несколько... ах кого я учу, сами не маленькие.

Бустинг Обучаем алгоритмы последовательно, каждый следующий уделяет особое внимание тем случаям, на которых ошибся предыдущий.
Как в беггинге, мы делаем выборки из исходных данных, но теперь не совсем случайно. В каждую новую выборку мы берём часть тех данных, на которых предыдущий алгоритм отработал неправильно. То есть как бы доучиваем новый алгоритм на ошибках предыдущего.
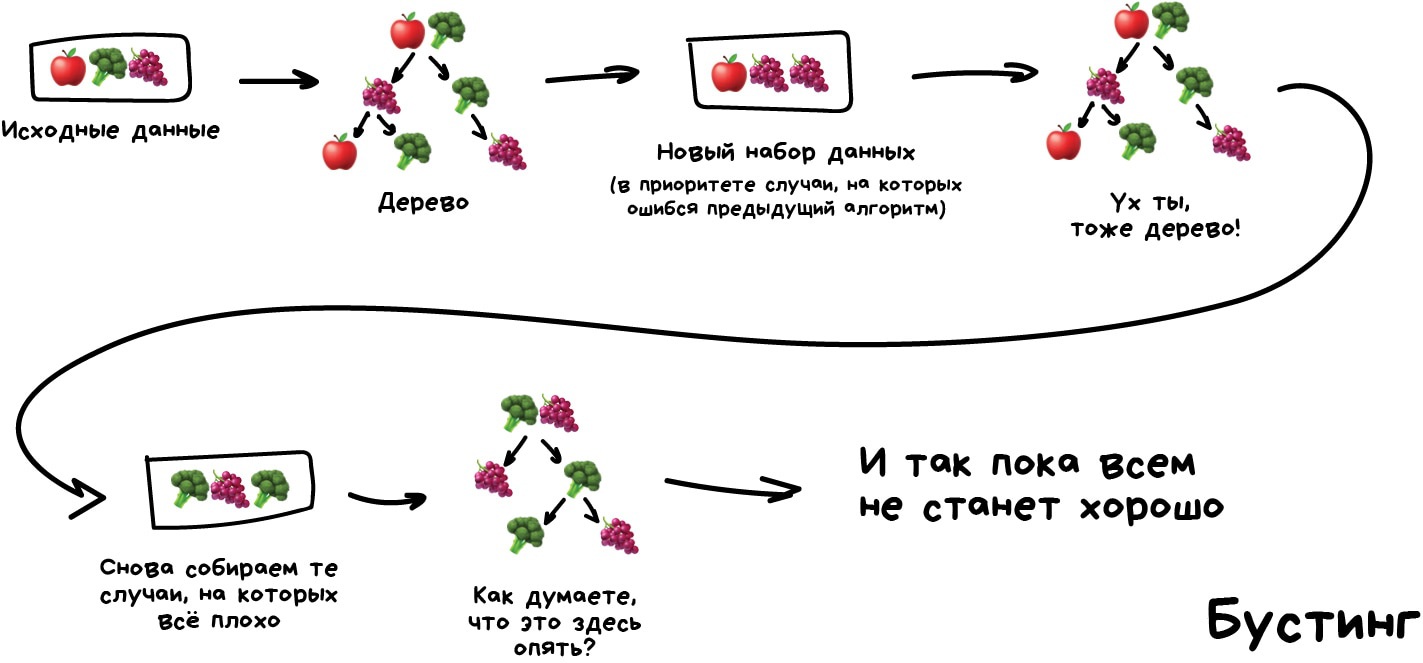
Плюсы — неистовая, даже нелегальная в некоторых странах, точность классификации, которой позавидуют все бабушки у подъезда. Минусы уже названы — не параллелится. Хотя всё равно работает быстрее нейросетей, которые как гружёные камазы с песком по сравнению с шустрым бустингом.
Нужен реальный пример работы бустинга — откройте Яндекс и введите запрос. Слышите, как Матрикснет грохочет деревьями и ранжирует вам результаты? Вот это как раз оно, Яндекс сейчас весь на бустинге. Про Google не знаю.
Сегодня есть три популярных метода бустинга, отличия которых хорошо донесены в статье CatBoost vs. LightGBM vs. XGBoost
«У нас есть сеть из тысячи слоёв, десятки видеокарт, но мы всё еще не придумали где это может быть полезно. Пусть рисует котиков!»
Сегодня используют для:
Популярные архитектуры: Перцептрон, Свёрточные Сети (CNN), Рекуррентные Сети (RNN), Автоэнкодеры
Да-да-да, примерно здесь мозг склеился и читать дальше не смог
я читаю в несколько заходов
Когда вы открываете камеру на телефоне и видите как она очертила лица людей в кадре желтыми прямоугольниками — скорее всего это их работа Виола-Джонс это бустинг
не, ну нормально, 15 лет назад был бустинг и до сих пор он же
у яндекса часть запросов (низкочастотные) сейчас выдаются нейросетью. они писали про это на хабре.
А кто знает, сильно ли Random Forest проигрывает градиентному бустингу и есть ли какие-нибудь живущие ныне плюсовые библиотеки c RandomForest-ом?
Если вам хоть раз не пытались объяснить нейросеть на примере якобы работы мозга, расскажите, как вам удалось спрятаться? Я буду избегать этих аналогий и объясню как нравится мне.
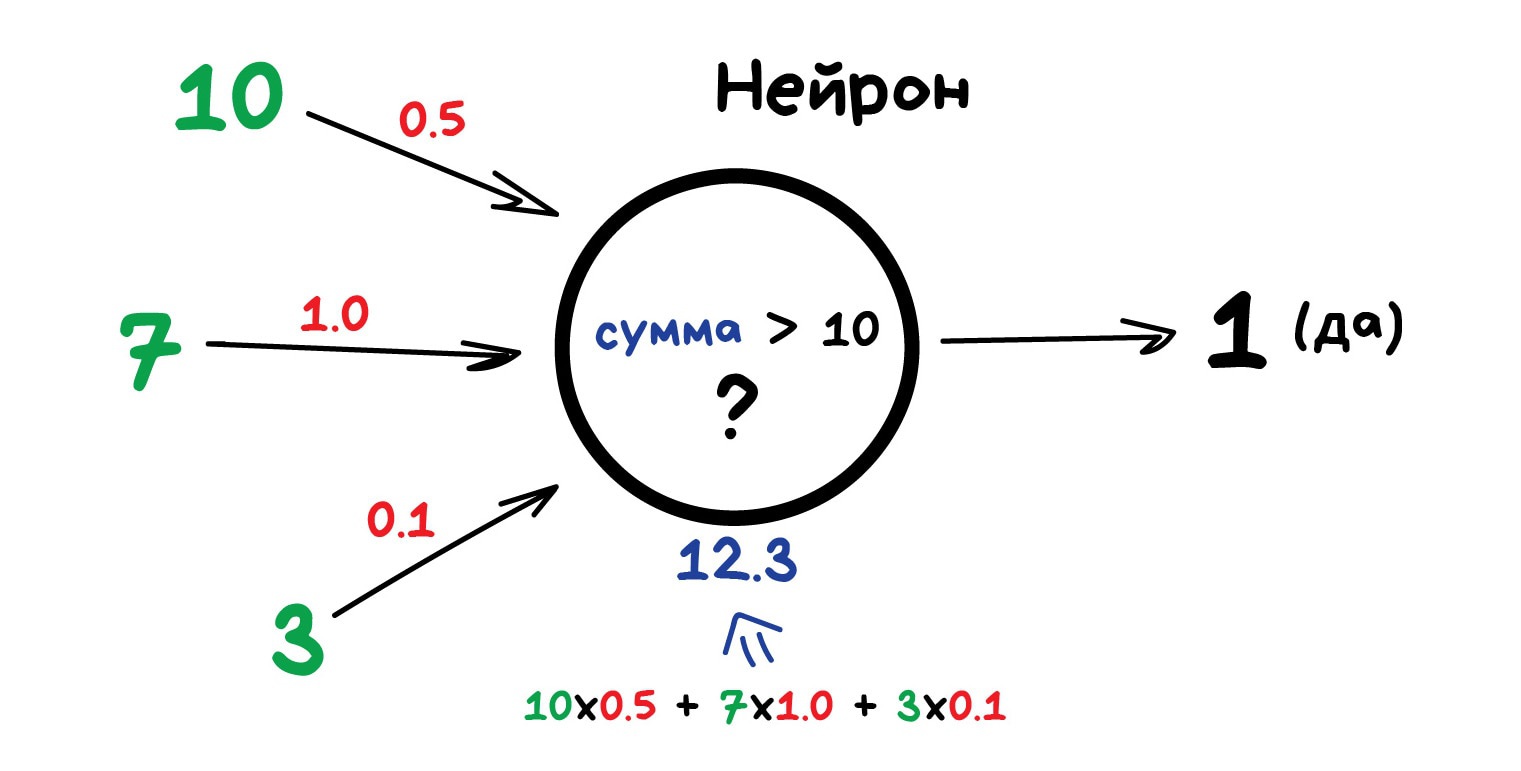
Любая нейросеть — это набор нейронов и связей между ними. Нейрон лучше всего представлять просто как функцию с кучей входов и одним выходом. Задача нейрона — взять числа со своих входов, выполнить над ними функцию и отдать результат на выход. Простой пример полезного нейрона: просуммировать все цифры со входов, и если их сумма больше N — выдать на выход единицу, иначе — ноль.
Связи — это каналы, через которые нейроны шлют друг другу циферки. У каждой связи есть свой вес — её единственный параметр, который можно условно представить как прочность связи. Когда через связь с весом 0.5 проходит число 10, оно превращается в 5. Сам нейрон не разбирается, что к нему пришло и суммирует всё подряд — вот веса и нужны, чтобы управлять на какие входы нейрон должен реагировать, а на какие нет.
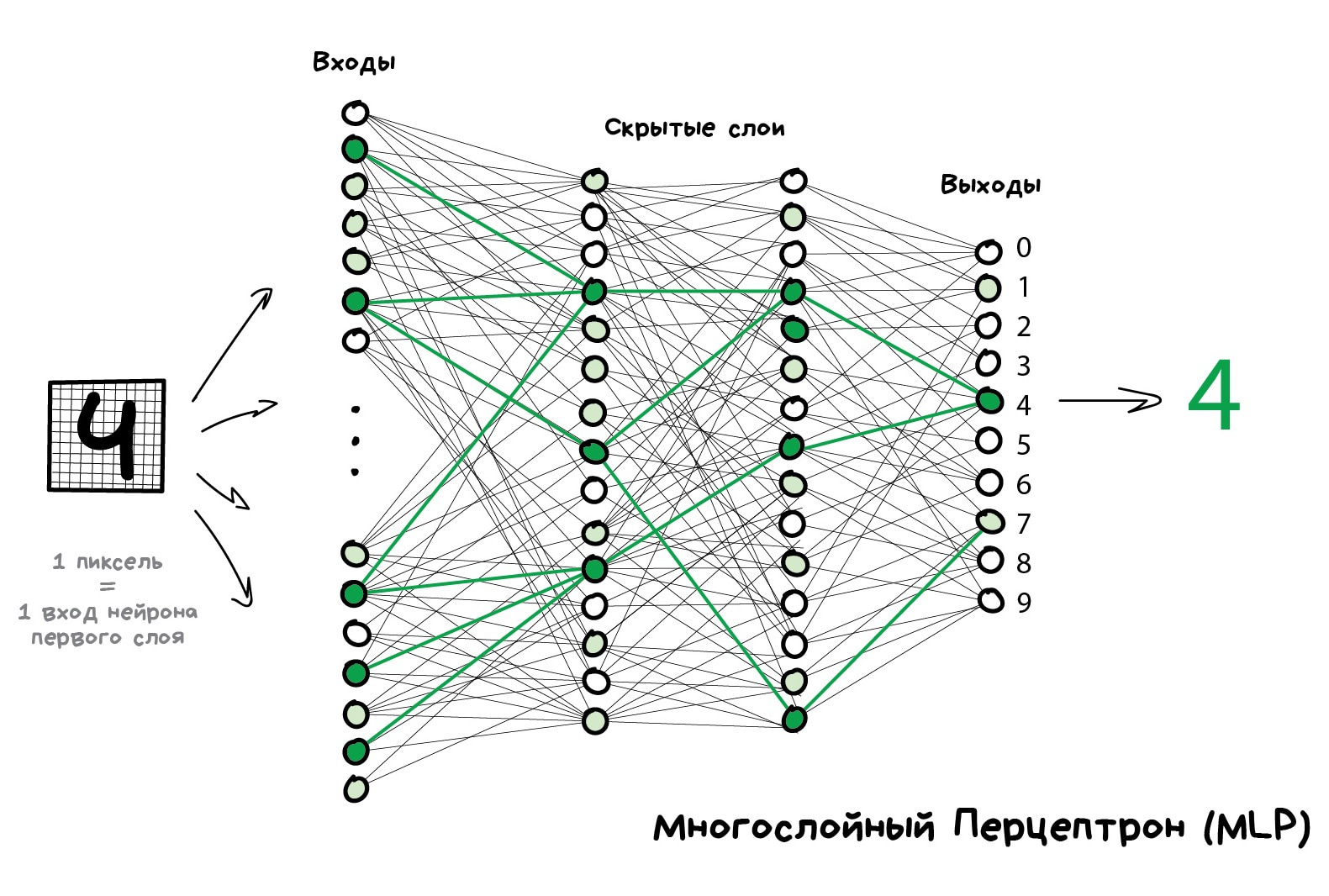
Чтобы сеть не превратилась в анархию, нейроны решили связывать не как захочется, а по слоям. Внутри одного слоя нейроны никак не связаны, но соединены с нейронами следующего и предыдущего слоя. Данные в такой сети идут строго в одном направлении — от входов первого слоя к выходам последнего.
Если нафигачить достаточное количество слоёв и правильно расставить веса в такой сети, получается следующее — подав на вход, скажем, изображение написанной от руки цифры 4, чёрные пиксели активируют связанные с ними нейроны, те активируют следующие слои, и так далее и далее, пока в итоге не загорится самый выход, отвечающий за четвёрку. Результат достигнут.
В реальном программировании, естественно, никаких нейронов и связей не пишут, всё представляют матрицами и считают матричными произведениями, потому что нужна скорость. У меня есть два любимых видео, в которых весь описанный мной процесс наглядно объяснён на примере распознавания рукописных цифр. Посмотрите, если хотите разобраться.
Такая сеть, где несколько слоёв и между ними связаны все нейроны, называется перцептроном (MLP) и считается самой простой архитектурой для новичков. В боевых задачах лично я никогда её не встречал.
Когда мы построили сеть, наша задача правильно расставить веса, чтобы нейроны реагировали на нужные сигналы. Тут нужно вспомнить, что у нас же есть данные — примеры «входов» и правильных «выходов». Будем показывать нейросети рисунок той же цифры 4 и говорить «подстрой свои веса так, чтобы на твоём выходе при таком входе всегда загоралась четвёрка».
Сначала все веса просто расставлены случайно, мы показываем сети цифру, она выдаёт какой-то случайный ответ (весов-то нет), а мы сравниваем, насколько результат отличается от нужного нам. Затем идём по сети в обратном направлении, от выходов ко входам, и говорим каждому нейрону — так, ты вот тут зачем-то активировался, из-за тебя всё пошло не так, давай ты будешь чуть меньше реагировать на вот эту связь и чуть больше на вон ту, ок?
Через тысяч сто таких циклов «прогнали-проверили-наказали» есть надежда, что веса в сети откорректируются так, как мы хотели. Научно этот подход называется Backpropagation или «Метод обратного распространения ошибки». Забавно то, что чтобы открыть этот метод понадобилось двадцать лет. До него нейросети обучали как могли.
Второй мой любимый видос более подробно объясняет весь процесс, но всё так же просто, на пальцах.
Хорошо обученная нейросеть могла притворяться любым алгоритмом из этой статьи, а зачастую даже работать точнее. Такая универсальность сделала их дико популярными. Наконец-то у нас есть архитектура человеческого мозга, говорили они, нужно просто собрать много слоёв и обучить их на любых данных, надеялись они. Потом началась первая Зима ИИ, потом оттепель, потом вторая волна разочарования.
Оказалось, что на обучение сети с большим количеством слоёв требовались невозможные по тем временам мощности. Сейчас любое игровое ведро с жифорсами превышает мощность тогдашнего датацентра. Тогда даже надежды на это не было, и в нейросетях все сильно разочаровались.
Пока лет десять назад не бомбанул диплёрнинг.
На английской википедии есть страничка Timeline of machine learning, где хорошо видны всплески радости и волны отчаяния.
В 2012 году свёрточная нейросеть порвала всех в конкурсе ImageNet, из-за чего в мире внезапно вспомнили о методах глубокого обучения, описанных еще в 90-х годах. Теперь-то у нас есть видеокарты!
Отличие глубокого обучения от классических нейросетей было в новых методах обучения, которые справлялись с большими размерами сетей. Однако сегодня лишь теоретики разделяют, какое обучение можно считать глубоким, а какое не очень. Мы же, как практики, используем популярные «глубокие» библиотеки типа Keras, TensorFlow и PyTorch даже когда нам надо собрать мини-сетку на пять слоёв. Просто потому что они удобнее всего того, что было раньше. Мы называем это просто нейросетями.
Расскажу о двух главных на сегодняшний момент.
Свёрточные сети сейчас на пике популярности. Они используются для поиска объектов на фото и видео, распознавания лиц, переноса стиля, генерации и дорисовки изображений, создания эффектов типа слоу-мо и улучшения качества фотографий. Сегодня CNN применяют везде, где есть картинки или видео. Даже в вашем айфоне несколько таких сетей смотрят на ваши голые фотографии, чтобы распознать объекты на них. Если там, конечно, есть что распознавать хехехе.

Картинка выше — результат работы библиотеки Detectron, которую Facebook недавно заопенсорсил
Проблема с изображениями всегда была в том, что непонятно, как выделять на них признаки. Текст можно разбить по предложениям, взять свойства слов из словарей. Картинки же приходилось размечать руками, объясняя машине, где у котика на фотографии ушки, а где хвост. Такой подход даже назвали «handcrafting признаков» и раньше все так и делали.
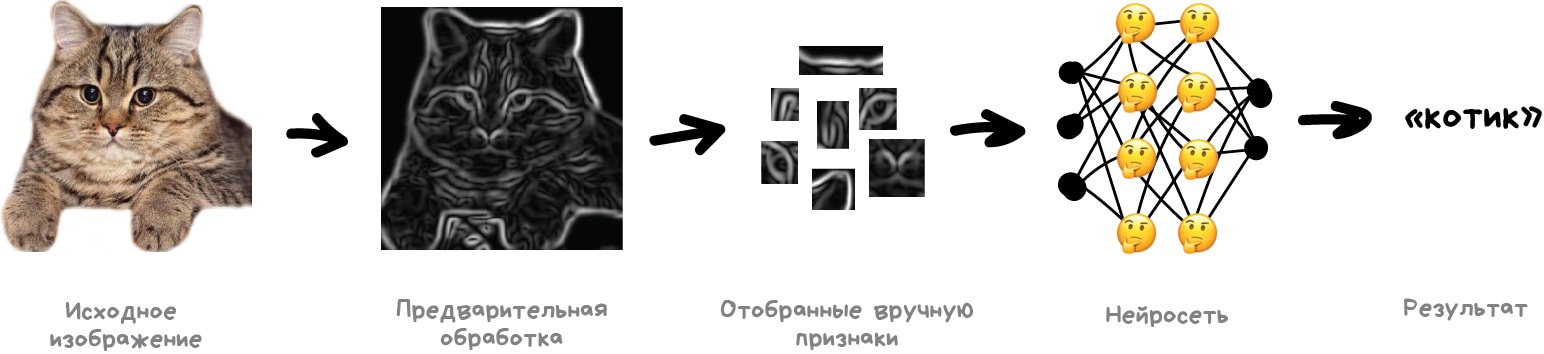
Проблем у ручного крафтинга много.
Во-первых, если котик на фотографии прижал ушки или отвернулся — всё, нейросеть ничего не увидит.
Во-вторых, попробуйте сами сейчас назвать хотя бы десять характерных признаков, отличающих котиков от других животных. Я вот не смог. Однако когда ночью мимо меня пробегает чёрное пятно, даже краем глаза я могу сказать котик это или крыса. Потому что человек не смотрит только на форму ушей и количество лап — он оценивает объект по куче разных признаков, о которых сам даже не задумывается. А значит, не понимает и не может объяснить машине.
Получается, машине надо самой учиться искать эти признаки, составляя из каких-то базовых линий. Будем делать так: для начала разделим изображение на блоки 8x8 пикселей и выберем какая линия доминирует в каждом — горизонтальная [-], вертикальная [|] или одна из диагональных [/]. Могут и две, и три, так тоже бывает, мы не всегда точно уверены.
На выходе мы получим несколько массивов палочек, которые по сути являются простейшими признаками наличия очертаний объектов на картинке. По сути это тоже картинки, просто из палочек. Значит мы можем вновь выбрать блок 8x8 и посмотреть уже, как эти палочки сочетаются друг с другом. А потом еще и еще.
Такая операция называется свёрткой, откуда и пошло название метода. Свёртку можно представить как слой нейросети, ведь нейрон — абсолютно любая функция.
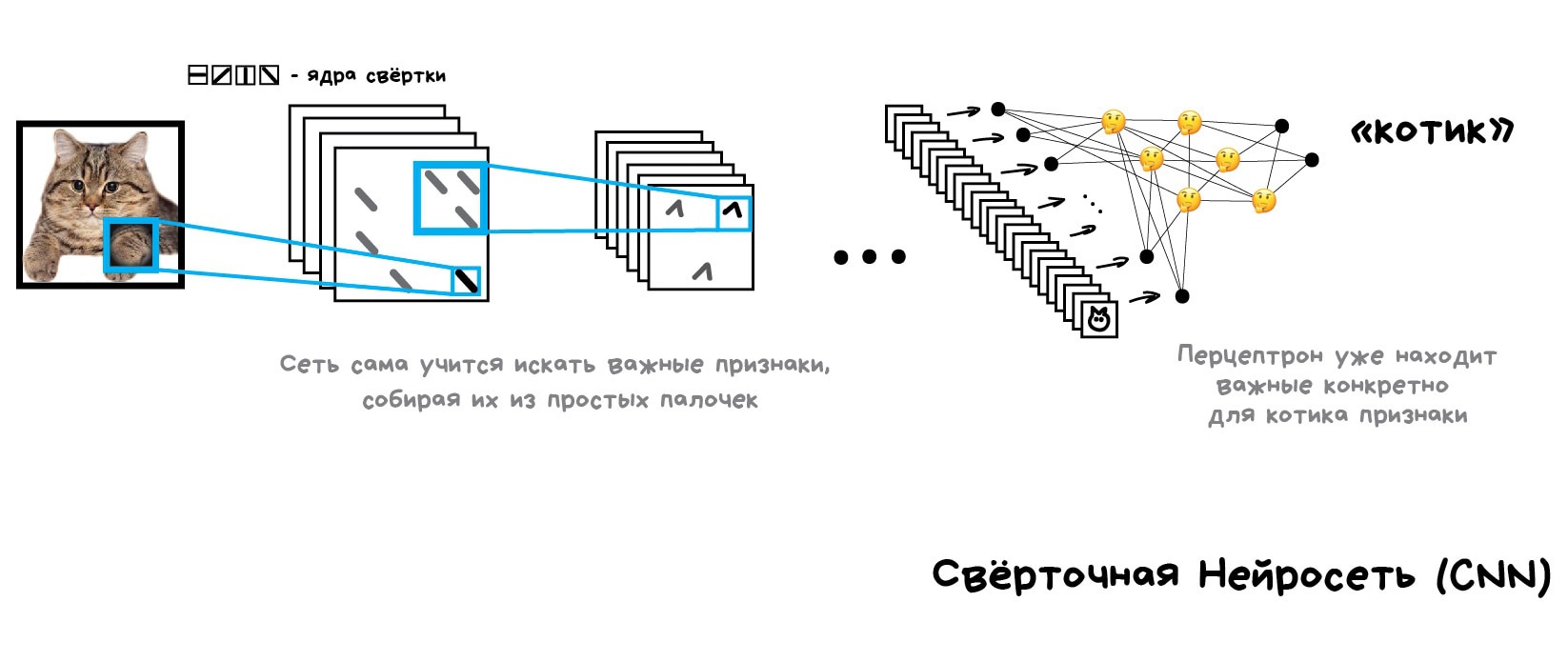
Когда мы прогоняем через нашу нейросеть кучу фотографий котов, она автоматически расставляет большие веса тем сочетаниям из палочек, которые увидела чаще всего. Причём неважно, это прямая линия спины или сложный геометрический объект типа мордочки — что-то обязательно будет ярко активироваться.
На выходе же мы поставим простой перцептрон, который будет смотреть какие сочетания активировались и говорить кому они больше характерны — кошке или собаке.

Красота идеи в том, что у нас получилась нейросеть, которая сама находит характерные признаки объектов. Нам больше не надо отбирать их руками. Мы можем сколько угодно кормить её изображениями любых объектов, просто нагуглив миллион картинок с ними — сеть сама составит карты признаков из палочек и научится определять что угодно.
По этому поводу у меня даже есть несмешная шутка:
Дай нейросети рыбу — она сможет определять рыбу до конца жизни. Дай нейросети удочку — она сможет определять и удочку до конца жизни...
Вторая по популярности архитектура на сегодняшний день. Благодаря рекуррентным сетям у нас есть такие полезные вещи, как машинный перевод текстов (читайте мой пост об этом) и компьютерный синтез речи. На них решают все задачи, связанные с последовательностями — голосовые, текстовые или музыкальные.
Помните олдскульные голосовые синтезаторы типа Microsoft Sam из Windows XP, который смешно произносил слова по буквам, пытаясь как-то склеить их между собой? А теперь посмотрите на Amazon Alexa или Алису от Яндекса — они сегодня не просто произносят слова без ошибок, они даже расставляют акценты в предложении!
Потому что современные голосовые помощники обучают говорить не буквами, а фразами. Но сразу заставить нейросеть целиком выдавать фразы не выйдет, ведь тогда ей надо будет запомнить все фразы в языке и её размер будет исполинским. Тут на помощь приходит то, что текст, речь или музыка — это последовательности. Каждое слово или звук — как бы самостоятельная единица, но которая зависит от предыдущих. Когда эта связь теряется — получатся дабстеп.
Достаточно легко обучить сеть произносить отдельные слова или буквы. Берём кучу размеченных на слова аудиофайлов и обучаем по входному слову выдавать нам последовательность сигналов, похожих на его произношение. Сравниваем с оригиналом от диктора и пытаемся максимально приблизиться к идеалу. Для такого подойдёт даже перцептрон.
Вот только с последовательностью опять беда, ведь перцептрон не запоминает что он генерировал ранее. Для него каждый запуск как в первый раз. Появилась идея добавить к каждому нейрону память. Так были придуманы рекуррентные сети, в которых каждый нейрон запоминал все свои предыдущие ответы и при следующем запуске использовал их как дополнительный вход. То есть нейрон мог сказать самому себе в будущем — эй, чувак, следующий звук должен звучать повыше, у нас тут гласная была (очень упрощенный пример).
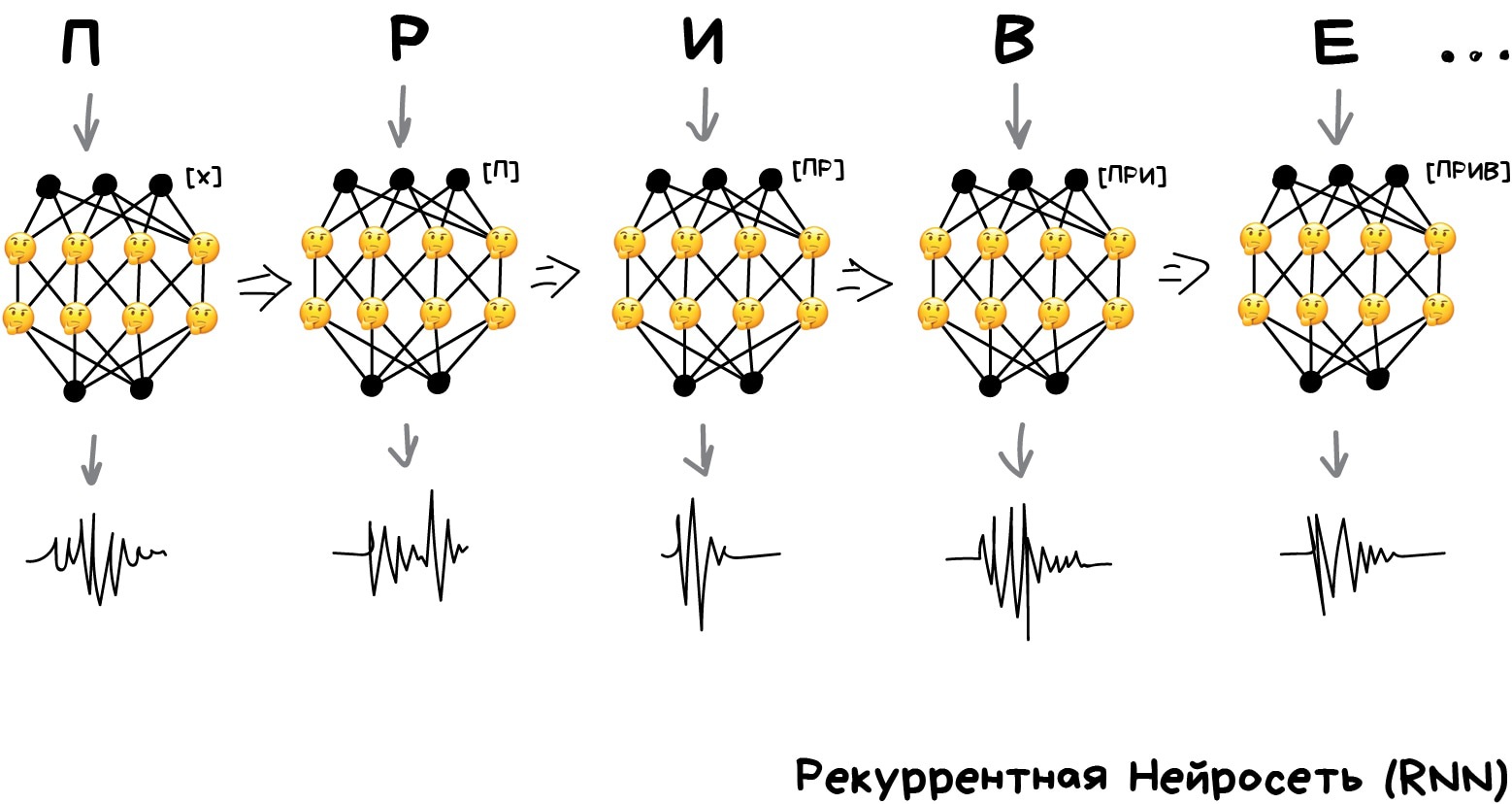
Была лишь одна проблема — когда каждый нейрон запоминал все прошлые результаты, в сети образовалось такое дикое количество входов, что обучить такое количество связей становилось нереально.
Когда нейросеть не умеет забывать — её нельзя обучить (у людей та же фигня).
Сначала проблему решили в лоб — обрубили каждому нейрону память. Но потом придумали в качестве этой «памяти» использовать специальные ячейки, похожие на память компьютера или регистры процессора. Каждая ячейка позволяла записать в себя циферку, прочитать или сбросить — их назвали ячейки долгой и краткосрочной памяти (LSTM).
Когда нейрону было нужно поставить себе напоминалку на будущее — он писал это в ячейку, когда наоборот вся история становилась ненужной (предложение, например, закончилось) — ячейки сбрасывались, оставляя только «долгосрочные» связи, как в классическом перцептроне. Другими словами, сеть обучалась не только устанавливать текущие связи, но и ставить напоминалки.
Просто, но работает!
Озвученные тексты для обучения начали брать откуда угодно. Даже базфид смог выгрузить видеозаписи выступлений Обамы и весьма неплохо научить нейросеть разговаривать его голосом. На этом примере видно, что имитировать голос — достаточно простая задача для сегодняшних машин. С видео посложнее, но это пока.

Про архитектуры нейросетей можно говорить бесконечно. Любознательных отправляю смотреть схему и читать статью Neural Network Zoo, где собраны все типы нейронных сетей. Есть и русская версия.
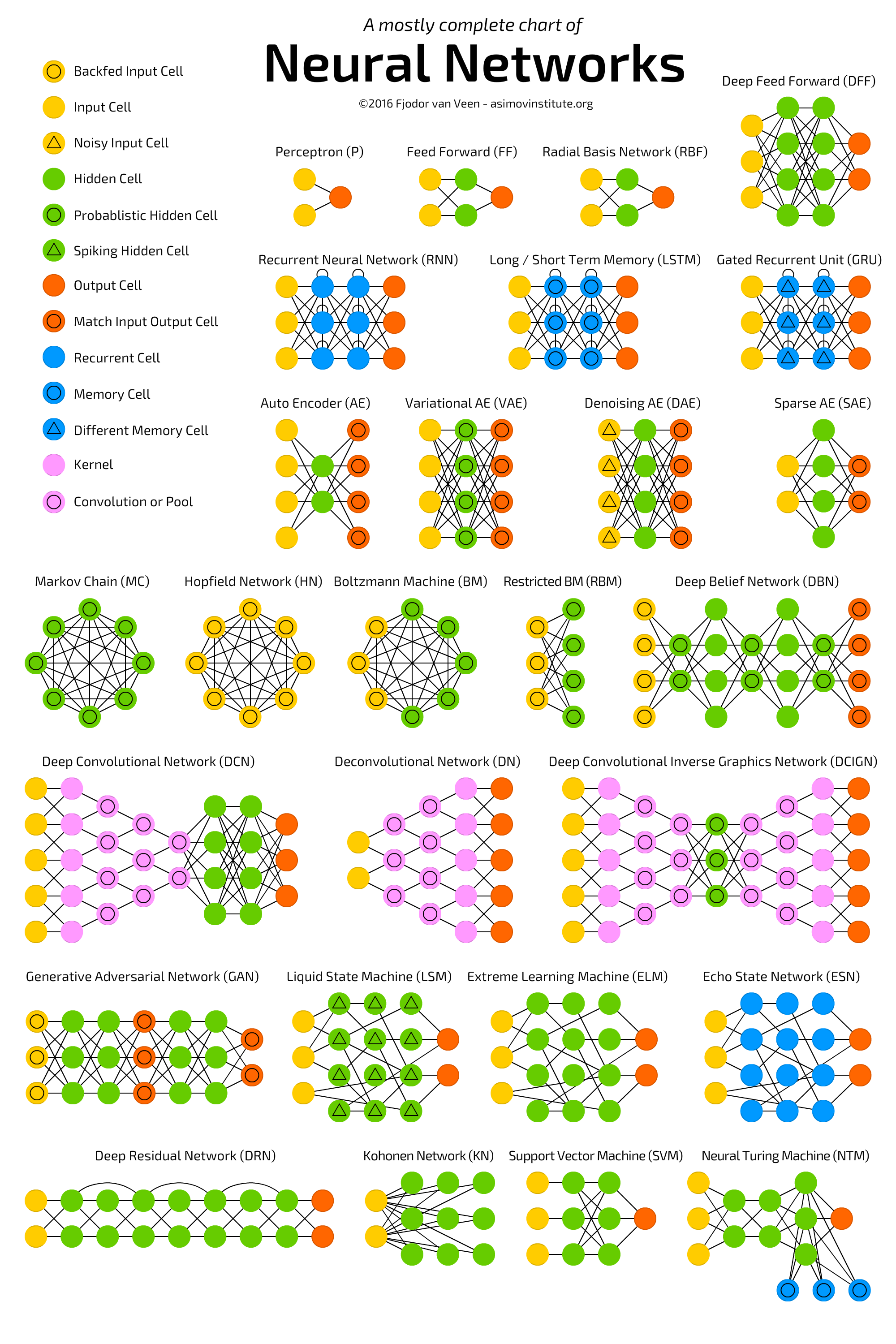
C в CNN - Convolutional
про стеккинг неправильно написано. то, что там написано - это разновидность бэггинга. проверьте плиз
lgbm норм параллелится на i9))
А как понять, что предыдущий алгоритм ошибся?
Поправочка, Random Forest -- это не только беггинг, но ещё случайное подмножество фичей для каждого дерева.

{kind=link}
{kind=link}
{kind=link}
Очень круто 👍
мля. это ж какой труд ты проделал
neu, ой, даже не спрашивай
Чувак, снимаю шляпу!
Это, пожалуй, самая понятная статья про нейросети, которую я видел
TL;DR потомушто я кожаный мешок
Да, похоже работа сегодня будут работать себя сама Спасибо!
Класс, не зря я отказался от солёных m&m's в пользу поддержки тебя на патреоне. Снимаю воображаемую шляпу.
Круто! Кожаные мешки доставляют.
Спасибо за статью! Так все четко и понятно, очень зашла!
Брат, завтра получу зп — проставлю пивас, а пока что огромное спасибо за упорядочивание мусора, который был у меня в голове :)
"Кожаный ублюдок купил диван! Рекомендуем ему еще 100500 диванов" Я так понимаю проблема в том что "умная" система знает лишь то, что я НАЧАЛ интересоваться диваном, но нет никакой обратной связи которая бы пояснила что диван уже куплен. В итоге получается, что вместо того чтоб рекомендовать мне плед/подушку, кожаный мешок получает бесконечные вариации все тех же диванов.
Это лучшее, что я читал в своей жизни
Спасибо, статья зашла на одном дыхании.
огромный респект автору! и плюсую за отличное чувство юмора
Где картинки рисовал?
Апплодирую!
Где ты работаешь ?
Ура, Вастрик-жив! Как всегда-великолепно - пивас!
Статья огонь! Продолжай!
Ясно-понятно!
Спасибо огромное за статью - на едином дыхании, хотя от этой темы далека и никогда особо не интересовалась. Надеюсь, будет еще :) Очень вставочки порадовали "сын мамкиной подруги" и подобное, стиль зачетный :)
Чёрт, Вастрик, спасибо тебе. Постоянно откладывал прочтение всей этой информации по кускам и ленился. Лонгрид лучше очень многого, что я читал по этой тематике. Лови пятишечный донатик.
Чувак, ты забыл самое мозговрыватьельное - GANы. Статья супер!
Офигительная статья! Автор крут! Плакат жду, повешу на стену.
эпичный пост по длине как режиссерская версия властелина колец
впервые решил проставить пивас автору
Вастрик, добавь пожалуйста LTC-кошелёк для доната, у PayPal конская комиссия (больше 3$) да и много у кого есть мелочь в крипте, думаю будет полезно. Статья - огонь.
Ну как бы да, когда мы пользуемся калькулятором или блокнотом - мы расширяем свой интеллект. Также как бульдозеры расширяют наши физ. возможности. Белка просто заточена на запоминание тайников, эволюцией. Но она не умнее человека. Вывод то какой?
Восторг! Пока читал думал: В чём секрет объяснений, которые работают? Чем они отличаются от десятков и сотен других, не работающих? Простотой? Почему другие не используют эту простоту? И можно ли эту концепцию простоты использовать (пусть хотя бы в качестве идеи, метафоры) в ML? Если вообще дело в «простоте», а не в чём-то ещё… Спасибо, автор! P.S. Попытался проставить пиво, но перевод с карты тинькофф на тинькофф не прокатил. Какая-то странная ошибка. Попробую ещё попозже.
Возможно автор поймет и этих ребят -Джон Гриндер, Ричард Бэндлер. Структура магии . Я встретил лишь одного, кто понял, как это использовать в прикладной психологии. Если поймет - будет вторым
Поставил пивас автору!
Статья шик, но ради христа подчисти опечатки, тысячи их
Vitalever, если хорошо понимаешь, то и можно найти простое объяснение. Если не можешь объяснить понятно, значит сам не понимаешь.
Отличная статья, спасибо!
Спасибо! Снимаю шляпу и проставляю пиво!
Статья просто супер. Спасибо большое! Лучшее, что читал по ML. Максимально понятно, подробно и много ссылок для дальнейшего изучения! :)
Статья прекрасна. Но, черт возьми, где г-н Вастрик рисует такие картинки? В фотошопе? Как такому научиться?
Огромное спасибо за статью. Донат +
Привет. Очень крутая статья, есть один вопрос. Какой шрифт используешь в своих схемах? (например, "принять кредит" и прочее)?
Мешок с транзисторами, признавайся, какой алгоритм использовал, чтобы сгенерировать эту статью?
Это божественно! Спасибо за статью!
Ничего себе ты психанул. Очень круто! Даже мне как человеку в теме было интересно не торопясь пройтись по каждой части и насладиться разжеваным контентом, а также одновременно всплакнуть с мыслью, почему таких статей не было, когда я только начинал разбираться с ML.
Класс! Эта статья просто космос. Если бы мне кто сказал, что я буду про какие-то там алгоритмы читать не отрываясь несколько часов подряд, я бы ржала. Вастрик, ты реально нереально круто рассказываешь.
Восторг и восхищение! Донат тебе за такой аццкий труд!
Ох*ительно. Огромное спасибо. Комикс в конце статьи порадовал. Редкий случай, но я даже готов простить ему шрифт Comic Sans (всё равно никто не знает про Dat Fest Comic...). Когда-нибудь мой Комикслейт обзаведётся нейросетью, которая будет сама ставить забеливание, подбирать шрифты и переводить так, чтоб глаза не вытекали. На 68 языков сразу...
Прекрасный материал, спасибо. Казалось бы, где я и где машинное обучение :) Но у вас отличный стиль, чувство юмора и вообще вы крутой :)
Спасибо за качественный материал и подробное объяснение.
Как можно с помощью ИИ всех наебать так и не вычитал. К чему это всё, в офисе за з.п. сидеть?
Добрый день! Спасибо за прекрасный материал! Подскажите кто то проходил "Машинное обучение и анализ данных»" от Яндекс? Интересует порог вхождения в курс...ну и на сколько он практически полезен Буду признателен за любую информацию
В статье очень много ошибок :(
Осилил за пару подходов, правда под конец мозг все равно начал вскипать и читал уже по диагонали) Очень классная статья, спасибо
Машина может создавать сама - текст, картинки, звуки и т.д. А так нереально круто.
Годнота
Спасибо.
#респект, всё по полочкам, всё по красоте
CNN это тоже MLP. CNN обычно являются частью GAN. Seq2seq это не автоэнкодер, это класс задач, которые обычно решаются при помощи рекуррентных сетей...
Ансамбли моделей могут включать в себя любые модели, в том числе, например, могут быть ансамбли нейронных сетей. Обучение с подкреплением — это не группа методов машинного обучения (с этой точки зрения виды МО это: обучение с учителем, обучение без учители и обучение с частичным привлечением учителя; при этом обучение с подкреплением это разновидность обучения с учителем).
Приветствую. Статья отличная. Читать интересно и весело. Думаю такая задача и была. Да? По сути где-то Сергей может формально и прав. Но для вводной статьи это допустимо, я думаю. Тут нужен индерес вместо академической точности формулировок. Кому надо - тот почитает Гудфеллоу и других "что, кто и зачем". Самому тема интересна на практике. Поэтому поделюс опытом и примером. Вопрос про анализ совместных покупок. Тут все сложнее. Компании пилят велосипед, так как хотят сохранить конкурентрое преимущество. Ведь там много вопросов. Обычно начинают с BI и делают руками и что-то вроде KNN и деревьев простых, возможно. Однако надо понимать - хорошая оценка возможна только по карточкам, так как у вас будет нормальная классификация как минимум по демографии и истории покупок. С историей покупок я бы думал о кластеризации и посике скрытых зависимостей. Далее мы возвращаемся во временные ряды с анализом сезонностей, аномалий. Например выходные, праздники, 1 сентября, конец учебного года, дачный сезон по погоде каждый раз отличаться будет немного. Если изучать поведение конкретного человека, то есть примеры отличного моделирования и привязки к событиям. Правда не в России этот случай был. Система сети супермаркетов определила предложила девушке в почте купоны на товары для беременных. Родители написали гневное письмо. Однако система нашла скрытый паттерн СМЕНЫ групп и цепочек покупок. И оказалась права. Человек (молодая девушка) резко перестал покупать сигареты и алкоголь, начала покупать другие крема, одежду, еду. Такая смена паттернов четко указывала на высокую вероятность такого события. Безусловно это могло бы быть и заболевание. Но со значительно меньшей правдоподобностью. В Чехии сети это надо. У наших сетей может и так хватает денег и им это не надо. Удачи.
Еще вопрос автору - что ж у вас новые комменты внизу? Я сначала подумал, что вообще не особо кому интересно, комменты очень старые. Это, правда, не помешало приятелям ссылку бросить, но ощущение....
Статья классная, но автор пишет как двоечник. Подучил бы язык, прежде чем писать огромные пасты.. (Именно стилистика и логика текста жутко хромает) Вот к примеру обзац, который надо бы отредактировать: "Старый доклад Бобука про повышение конверсии лендингов с помощью SVM Для классификации всегда нужен учитель — размеченные данные с признаками и категориями, которые машина будет учиться определять по этим признакам. Дальше классифицировать можно что угодно: пользователей по интересам — так делают алгоритмические ленты, статьи по языкам и тематикам — важно для поисковиков, музыку по жанрам — вспомните плейлисты Спотифая и Яндекс.Музыки, даже письма в вашем почтовом ящике." Он реально очень раздражает)
А так конечно ,извините за критику. Содержание статьи бесспорно - ПИЗДАТО, нигде в инете такого нет. За это спасибо, а про редактирование текста я написал, что бы будущим людям было легче читать. Спасибо и досвидания.
Отличная статья, столько полезного, что некоторым умникам на докторскую хватит. Спасибо автору за щедрость. Пивасик обязательно.
Вы великолепны!
ИдеальнО! Спасибо за статью!
Офигенский текст понятный нематематику и непрограммисту. Огромное спасибо
Это топ, спасибо!
Огромное спасибо!!
Я мама парня, который работает как раз в сфере глубокого обучения нейросетей. Чтоб мне не объяснять долго, скинул вашу статью. :)) Очень понравилось, все понятно и доступно! И весело, мило. Про ошибки не слушайте никого. Я вот сознательно иногда люблю слова подменять и буквы, чтоб придать большей выразительности! На вкусняшки отправила:)
Автор, я кожаный ублюдок-гуманитарий, но работаю в сфере ML. Спасибо тебе огромное за то, что мне теперь всё понятно и я больше не буду чувствовать себя дебилом на планёрках)
Статья классная, а иллюстрации вообще огонь! Все понятно, все ясно даже не особо просвященному человеку. Я обычно все новости про машинное обучение и искусственный интеллект беру из Вк https://vk.com/neural_nets или канала https://t.me/aichannel в телеграме, но как же приятно находить еще полезные статьи по этой теме на других ресурсах.
Замечательная статья! Можно тиражировать как учебник!
Дочитала всё и в конце не поленилась перемножить в уме 1680 на 950. Получилось правильно :) Твой лонгрид отлично разогнал мозг!
Лайк, шер, респект!
Лучшее, что я нашел в рунете об ML для "совсем новичков"!!! Респектище!!! А не планируешь еще подкрепить это практическими примерами на Питончеге? =) было бы круто =)
Автору пивасик и моё восхищение его способности говорит о сложном просто. Ты вернул мой мозг на место. А графика просто волшебная по своей понятности.
Спасибо, статья супер!
Спасибо, отличный лонг.
Статья - огонь!
Лучшая статья про нейросети!
С П А С И Б О
С МЕНЯ 3 ПИВА ПРИЛЕТЕЛО ТЕБЕ )) Боги, Я буду читать это по утрам и перед сном вам в дар!
Сделаю мозговой штурм в команде. Есть теперь конструктивный материал. спасибо!
Сделаю мозговой штурм в команде. Есть теперь конструктивный материал. спасибо!
Внимание: Вы ищете РЕАЛЬНУЮ ФИНАНСОВУЮ КРЕДИТНУЮ КОМПАНИЮ, чтобы предоставить вам кредит на сумму от 10,000.00 евро до 5,000,000.00 евро (для займа для бизнеса или компании, личного займа, ипотечного кредита, автокредита, займа для консолидации долга, венчурного капитала, займа для здравоохранения и т. Д.) Или вам отказали в кредите в банке или финансовом учреждении по той или иной причине? Подайте заявку сейчас и получите реальный финансовый кредит, обработанный и одобренный в течение 3 дней. ФИРМА ФИНАНСОВОГО КРЕДИТА МАРКА ДЭВСОНА, мы являемся «Кредитором, получившим международное признание», который предоставляет РЕАЛЬНЫЕ ФИНАНСОВЫЕ КРЕДИТЫ частным лицам и компаниям с низкой процентной ставкой 2% с вашей действительной идентификационной картой или международным паспортом вашей страны для проверки. Срок погашения нашего кредита начинается через 1 (один) год после получения кредита, а срок погашения составляет от 3 до 35 лет. Нашей компании также нужен человек, который может быть представителем нашей компании в вашей стране. ДЛЯ НЕМЕДЛЕННОГО ОТВЕТА И ОБРАБОТКИ ЗАЯВКИ НА ВАШ КРЕДИТ В ТЕЧЕНИЕ 2 РАБОЧИХ ДНЕЙ, Свяжитесь с нами напрямую через это письмо: [email protected] Свяжитесь с нами со следующей информацией: ФИО:____________________________ Сумма, необходимая в качестве займа: ________________ Срок кредита: _________________________ Цель кредита: ______________________ Дата рождения:___________________________ Пол:_______________________________ Семейное положение:__________________________ Контактный адрес:_______________________ Город / Почтовый индекс: __________________________ Страна:_______________________________ Оккупация:____________________________ Мобильный телефон:__________________________ Отправьте запрос на немедленный ответ по адресу: [email protected] Спасибо ГЕНЕРАЛЬНЫЙ ДИРЕКТОР. Преподобный Марк Дэвсон МАРК ДЭВСОН ФИНАНСОВАЯ КРЕДИТНАЯ ФИРМА Великобритания, Англия (Великобритания) E-mail: [email protected] Электронная почта: [email protected] Электронная почта: [email protected] Веб-сайт: //davsonfinancialloanfirm.webs.com/ WhatsApp: +447404320361 WhatsApp: +19046065496
У человека очень слабый процессор из-за ограничений среды, его потребляемая мощность всего то 0,5 Вт на пике, нельзя разогнать его больше, не поломав законы термодинамики. Так что да, способности голого мозга - это никак не экспонента. Как то так.
Это охренительно.
Спасибо, оказывается я еще и это не знал.
Великолепная статья, прочитал на одном дыхании, весь тот буллшит что был у меня в голове тут же раскидался по полочкам и теперь мне понятно who is who)) Снимаю шляпу))))
"Ключевое слово — разных алгоритмов, ведь один и тот же алгоритм, обученный на одних и тех же данных не имеет смысла. Каких — ваше дело, разве что в качестве решающего алгоритма чаще берут регрессию." Здесь имеется в виду логистическая регрессия?
Здесь лучше описано чем за 2 курса...
Thanks, very useful
Статья бомба. Автор молодец
Можно взять пару слайдов для презентации?
Спасибо огромное! Количество котиков и шутеек в статье сглаживает негатив написания курсовой по теме, в которой ты не шаришь. Огонь
Супер материал! Но есть подозрение, то написан очень умной машиной )
классный материал!
В первом абзаце заключения "В нём слишком много скрытых условий, который примаются как как данность", надо наверное, так "В нём слишком много скрытых условий, которые принимаются как данность"
Спасибо! Отличная статья!
Лучшая статься про МО!
Спасибо огромно! Великолепная статья!
Вастрик, блэт! Ну зачем? У меня это знакомы
-.- Так вот, комментарии типо "я домохозяйка, а статья такая интересная" отражают всю суть! К тому же видно, что тема непрофильная :) Не надо писать ради хайпа, пожалуйста, и так куча некачественных материалов на тему. Я лублу твою рассылку, но от этой статьи бомбит. Особенно когда вижу ошибки. И когда знакомый с дипломом философа ее расшаривает.
Мне кажется, что люди обрабатывают зрительную информацию не только по палочкам, из которых состоит тот или иной визуальный образ, а и по пропорциям. То есть, увидев краем глаза чёрное пятно, ты поймёшь, что это кот, а не крыса, потому что: - вероятность встретить крысы в твоём районе очень маленькая (ты их никогда не видел), - такой изгиб позвоночника и способ передвижения (скорость, прижатость к земле, способ переставления лап) характерен только для котиков, - пропорции ушей/лап/хвоста/головы/туловища/глаз к целому котику и по отдельности характерны только для котиков (голова крысы пропорционально меньше туловища крысы), то же самое касается всех внутренних пропорций в животном 🤔 или нет ___ Спасибо.
Статья супер, большое спасибо
Прочитал на одном дыхание, буду пиздить материал на свой диплом
Чтобы бустинг параллелился используют oblivious decision trees - все узлы одного уровня обязательно используют один и тот же атрибут. https://www.youtube.com/watch?v=g-bPnhKU0P8 - c 7:30
а с 11:07 доп инфа по распараллеливанию
или тут - https://www.youtube.com/watch?v=Q_xa4RvnDcY с 10 мин
Спасибо за труд, как всегда мега полезно и доступно!
это очень очень круто! у нас в Практикуме у специальности DA на эту тему 2 недели всего 🤦 вообще не врубиться. Могу поделиться pdf-кой с коллегами?