≡
На прошлой неделе я опять был во Франции. Когда ты во Франции, твоя главная цель — ВКУСНО ЖРАТЬ. Потому что во Франции ЖРАТЬ лучшее в мире.
Но есть одна проблема: если ты идёшь не в туристическую забегаловку, а в аутентичный ресторанчик в любом французском городе, в лучшем случае (когда у владельца хороший почерк и он проснулся в хорошем настроении) его меню будет выглядеть примерно так:

Кто не был во Франции, я даже уточню: даже если вы просите «меню», вам не дают красивую книжку с картинками, как вы привыкли. Вам литералли ставят на стол вот такую черную доску с написанными белым мелом блюдами дня (на французском). Сильвупле, мёсьё! Ду вин пур ле дамэ?
Да, нам обычно везёт, и с нами обычно есть друзья, говорящие по-французски. Но иногда бывают ситуации, когда ВКУСНО ЖРАТЬ хочется, а друзей рядом нет.
Так я как-то давно придумал идею для стартапа.
У ChatGPT (и аналогов) есть интересная особенность — они на удивление хорошо распознают рукописный текст. Даже если это каракули какого-нибудь доктора или протокол полиции на сербском языке (не спрашивайте откуда я это знаю). Прям на голову выше любых старых OCR приложений.

Так вот во время последней поездки по Франции меня озарила максимально тупая и гениальная мысль:
Надо сделать приложение, которым фотографируешь меню ресторана, а оно тебе возвращает список блюд с описаниями на понятном тебе языке и фотографиями как они реально выглядят. И рейтингом... И...
Уверен ли я, что таких приложений уже существует минимум пара сотен тысяч в аппсторе? Конечно же да. Волнует ли меня это? Нет))00)
Так что здесь мы переходим непосредственно к теме поста — вайб-кодингу!
Я не знаю кто придумал сам термин вайб-кодинг, но популярным он стал после твита Andrej Karpathy:
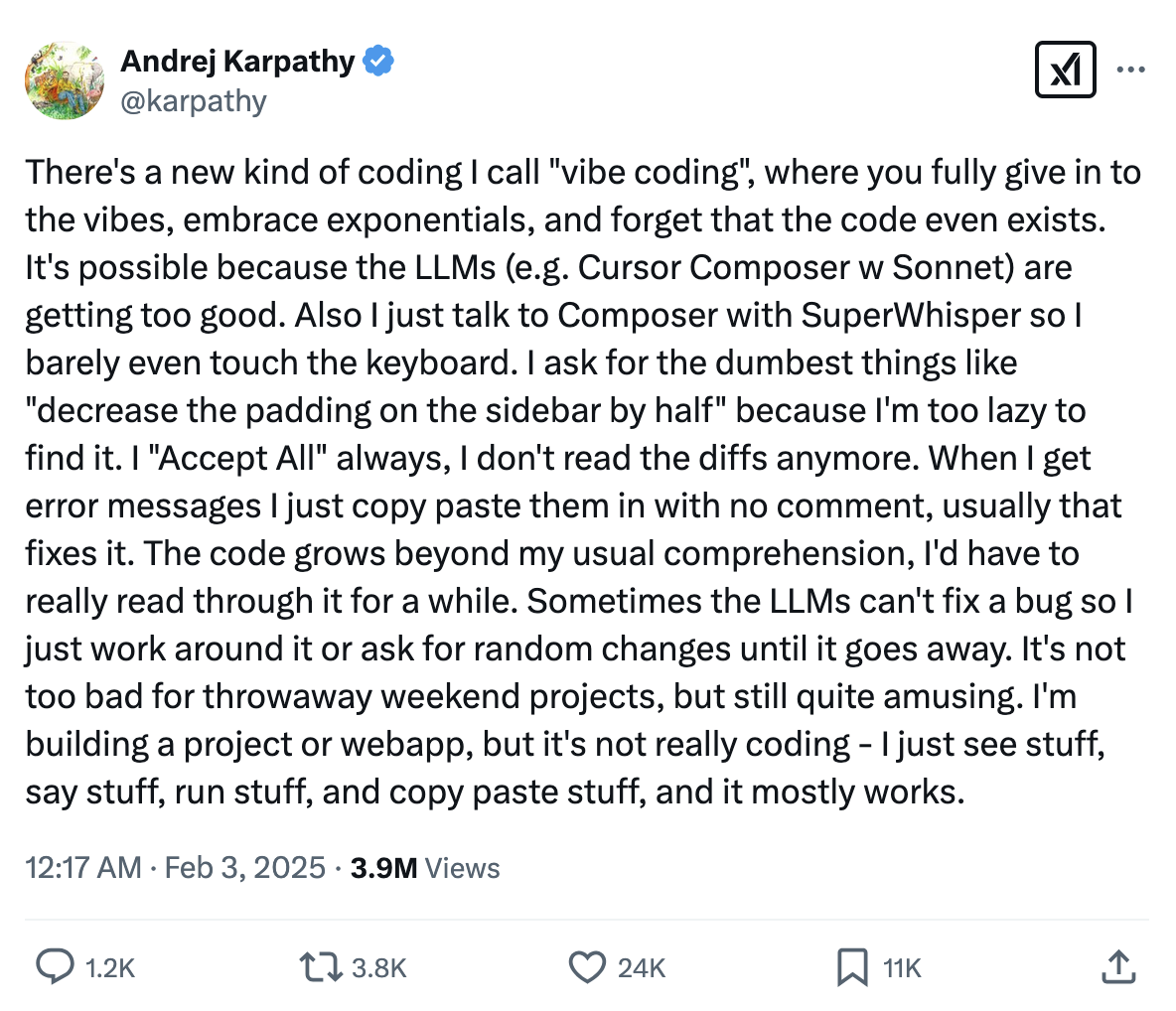
Идея вайб-кодинга в том, что с появлением LLM-инструментов генерации кода и даже целых проектов, как например Claude Sonnet или Cursor (я писал о нем в Итогах Года), у любителей попрограммировать что-нибудь вечером открылся новый способ программирования — с помощью чата с LLM или даже голоса.
Вы открываете Cursor или любую другую AI IDE, создаете чистый проект и начинаете прямо сообщениями в чат ему написывать о том, что вы хотите получить.
Например, я начал с такого промпта:
Create me a React app from scratch. The idea is to have an app which can take a photo of a menu in a restaurant, translate it and then show a list of food with photos of this food from the internet. It must be a PWA with a button opening camera or choosing a photo from gallery which then sends it to ChatGPT to parse text, create a list of items (including categories and prices) and then uses some image API to find images for the food name in the internet. User can see the list and click on items opening more images and description of the dish
Дальше я отправляю свой промпт в Le Chat Sonnet...
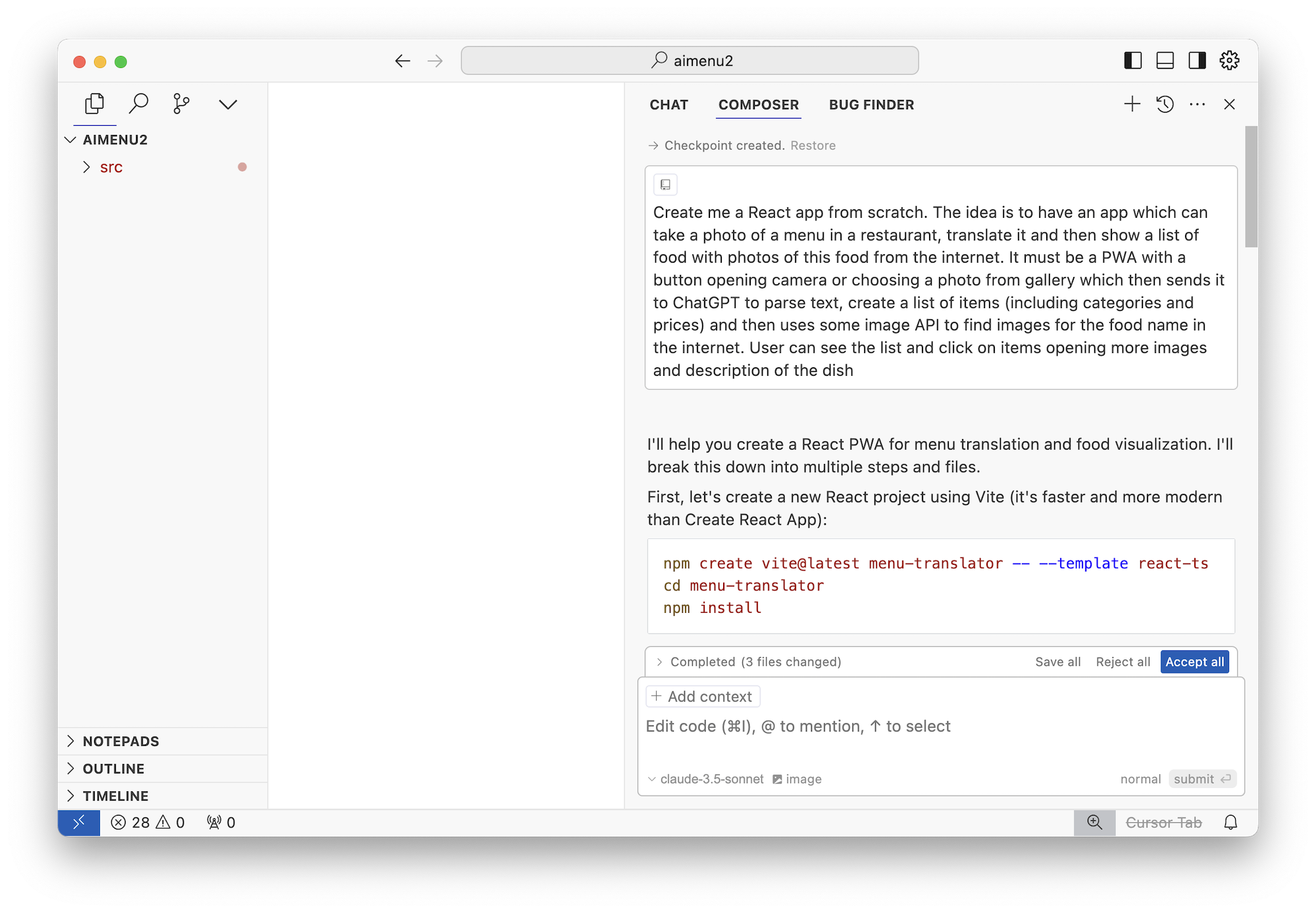
И волшебство GenAI магическим образом генерирует мне...
какое-то говно.
ахахаха, жиза
Структура проекта отвратительная, всё запихано в один компонент, к OpenAI API он ходит через REST вместо стандартной либы, никакого разделения по экранам, индикации процесса, сотни запросов бегают туда-сюда без кеширования, короче как будто бы джун писал. Здоровый человек этим пользоваться не сможет.
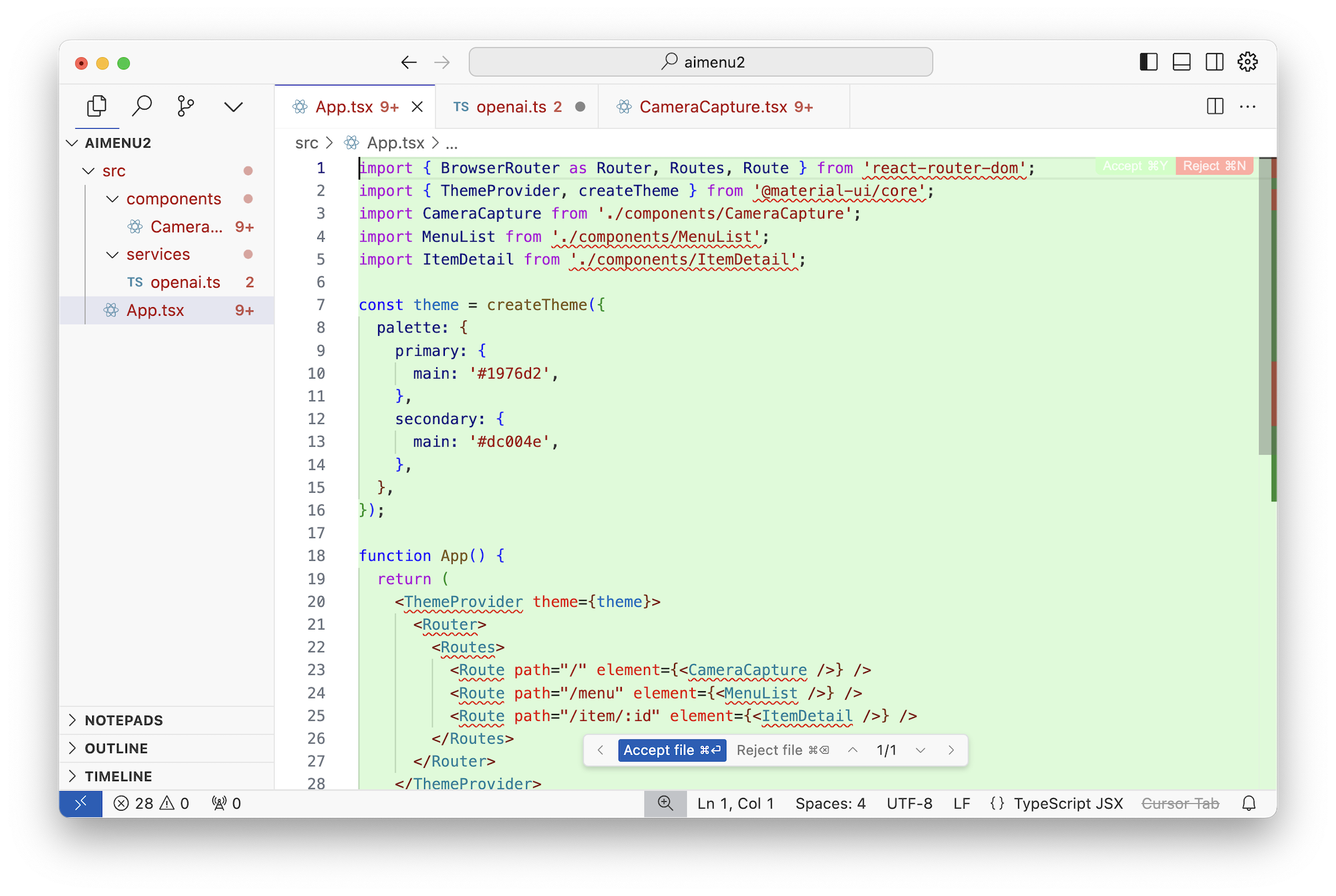
Хотя мне нравится, что оно взяло React + Vite + MUI. Я хоть и бекендер, но поцаны-фронтендеры во дворе рассказывали, что для прототипов это выбор солидного джентельмена.
А еще оно ЗАПУСКАЕТСЯ!
Если сделать npm create/install, как он просит, то npm run dev реально запустит вам (почти) рабочий проект, где просто руками надо будет изменить пару api-ключиков в конфиге и подставить современные версии OpenAI-моделей.
В целом, оно работает.
Но теперь вы понимаете, что с LLM надо разговаривать не как сеньор с сеньором, а как сеньор с джуном. Вы начинаете формулировать свои мысли более конкретно.
Каждый экран, каждая кнопка, каждый лаяут, размеры кнопок и иконок на каждом экране, положение меню, кнопки «назад» и даже выбор фреймворка — всё должно быть вами упомянуто и описано.
Как будто пишешь тикет в Джире для ОЧЕНЬ тупого разработчика. Только результат появляется сразу, а не через пару месяцев созвонов и выборов CSS-фреймворка.
Нельзя сразу требовать от LLM чего-то сложного. Иначе он устанет и сломается на полпути (прям как реальный программист). Нужно придумать и описать тот самый MVP, чтобы результат первой итерации был одновременно максимально простым и базовым, но при этом запускался, работал и решал свою основную задачу.
Короче, теперь вы как будто работаете продакт-менеджером для LLM. Добро пожаловать! Надеюсь настоящие продакты еще не поняли, что программисты им больше не нужны...
Ладно.
Продакты делятся на две группы - которые уже поняли и которые скоро поймут. Всем программистам лучше бы уже переделываться в продакты.
Это ты еще агент мод не пробовал. Он сам запустит (с твоего позволения) проект в консоли, посмотрит логи и исправит ошибки линтера. И еще ему не нужно подставлять контекст руками, он может сам найти нужные файлы в проекте
Дмитрий Белов, в windsurf такое встроено прям в основной функционал.
Агентский режим есть в любом уважающем себя редакторе. Но результаты с ним часто хуже чем через полу-автоматический режим Chat.
По итогу я удаляю проект, создаю новый и пишу следующий промпт в Claude 3.5 Sonnet:
Да начнется вайб-кодинг!

Окей, на этот раз он сгенерировал мне на первый взгляд достойную структуру приложения. Четыре экрана, индикаторы загрузки, URL-роутинг, даже отдельную модельку-сервис создал, которая обрабатывает бизнес-логику меню. Как будто бы курс «Стань Веб-Разработчиком за 13 дней» пройден не зря. Плюс вайб!
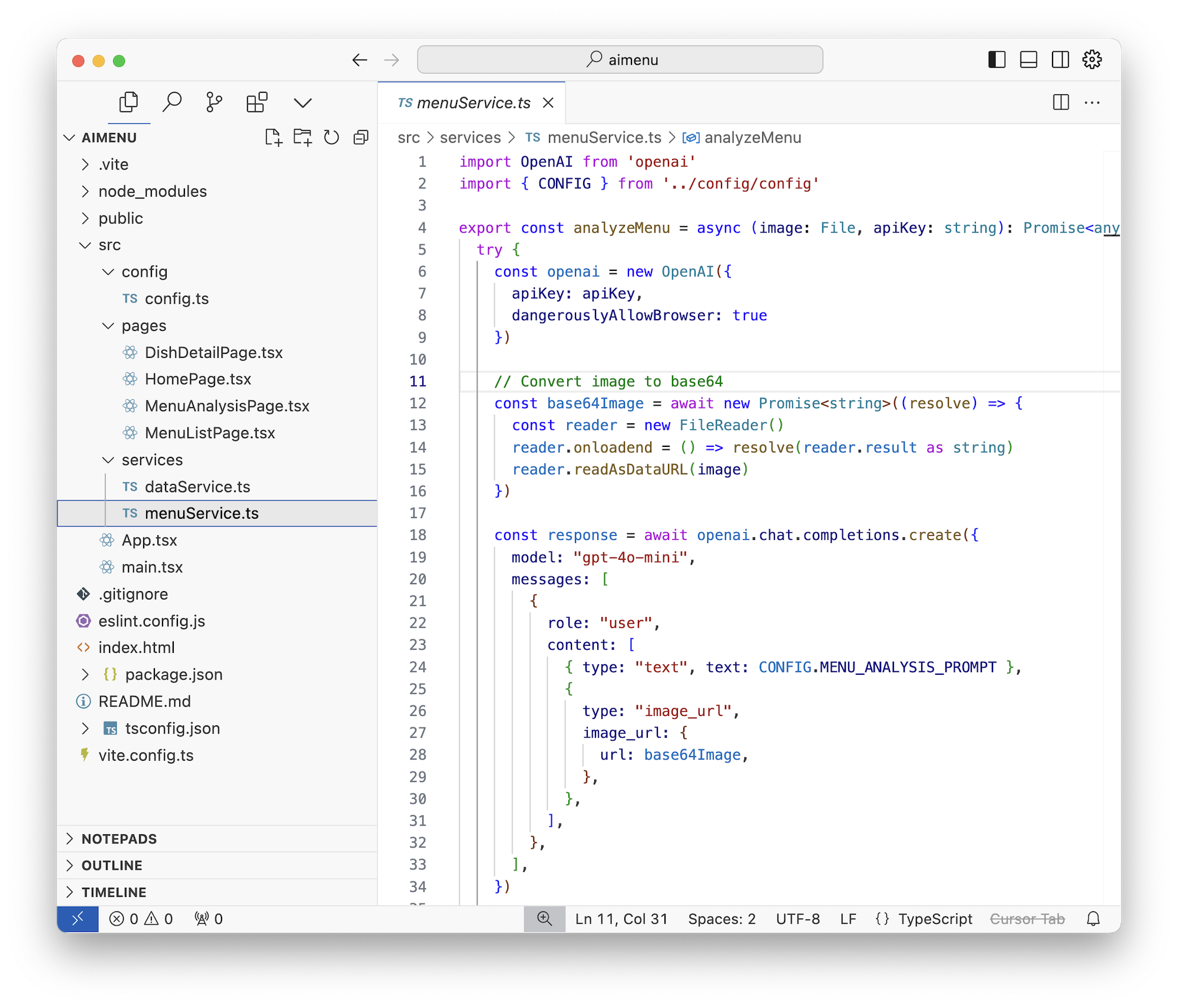
📝 Note: когда я писал этот пост и запускал свои промпты еще раз, чтобы сделать скриншоты — каждый раз они мне давали разный результат, иногда вплоть до нерабочего проекта. Так что если у вас не получается повторить — просто меняйте запрос и бейтесь с ним до победного!
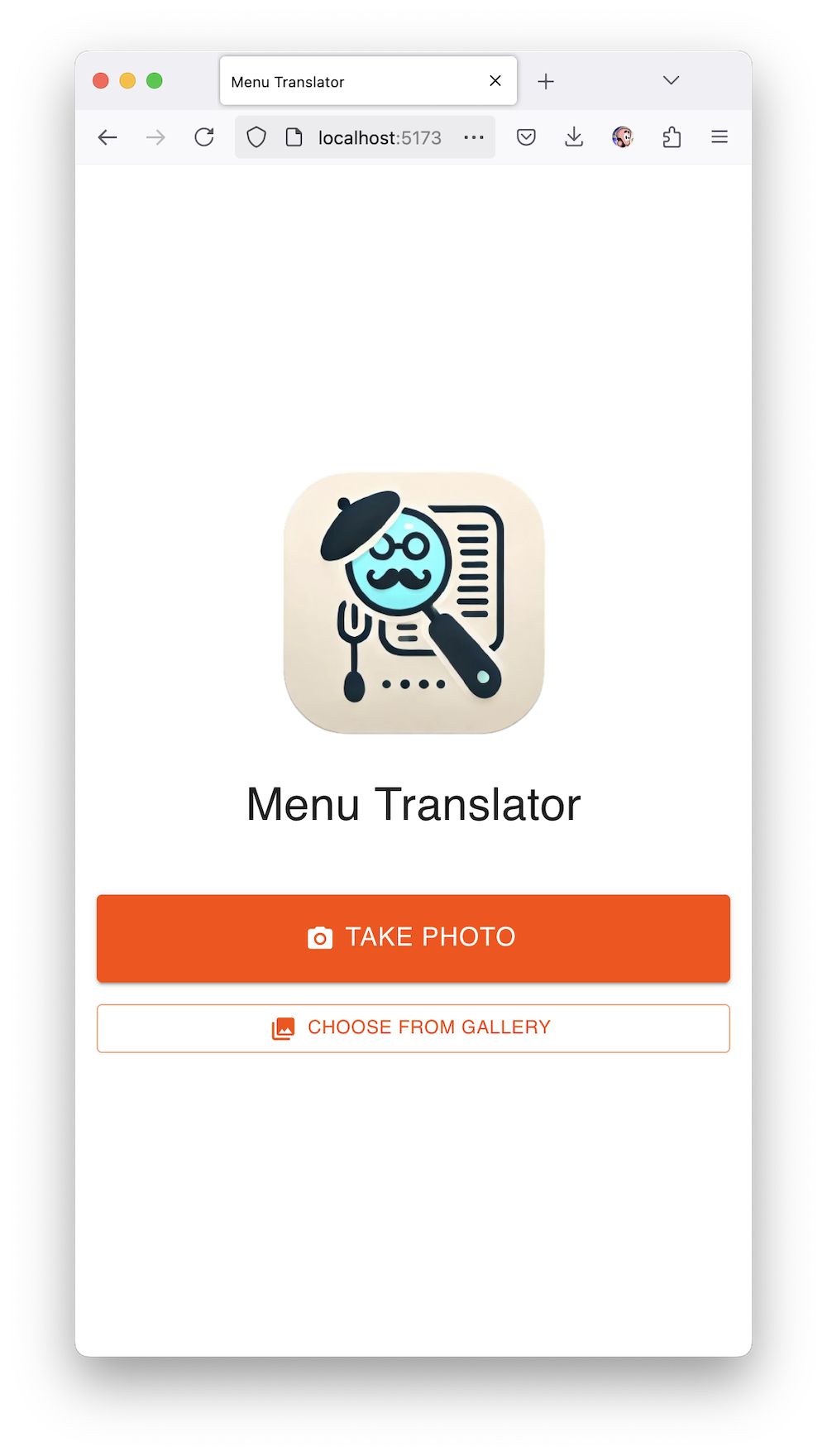
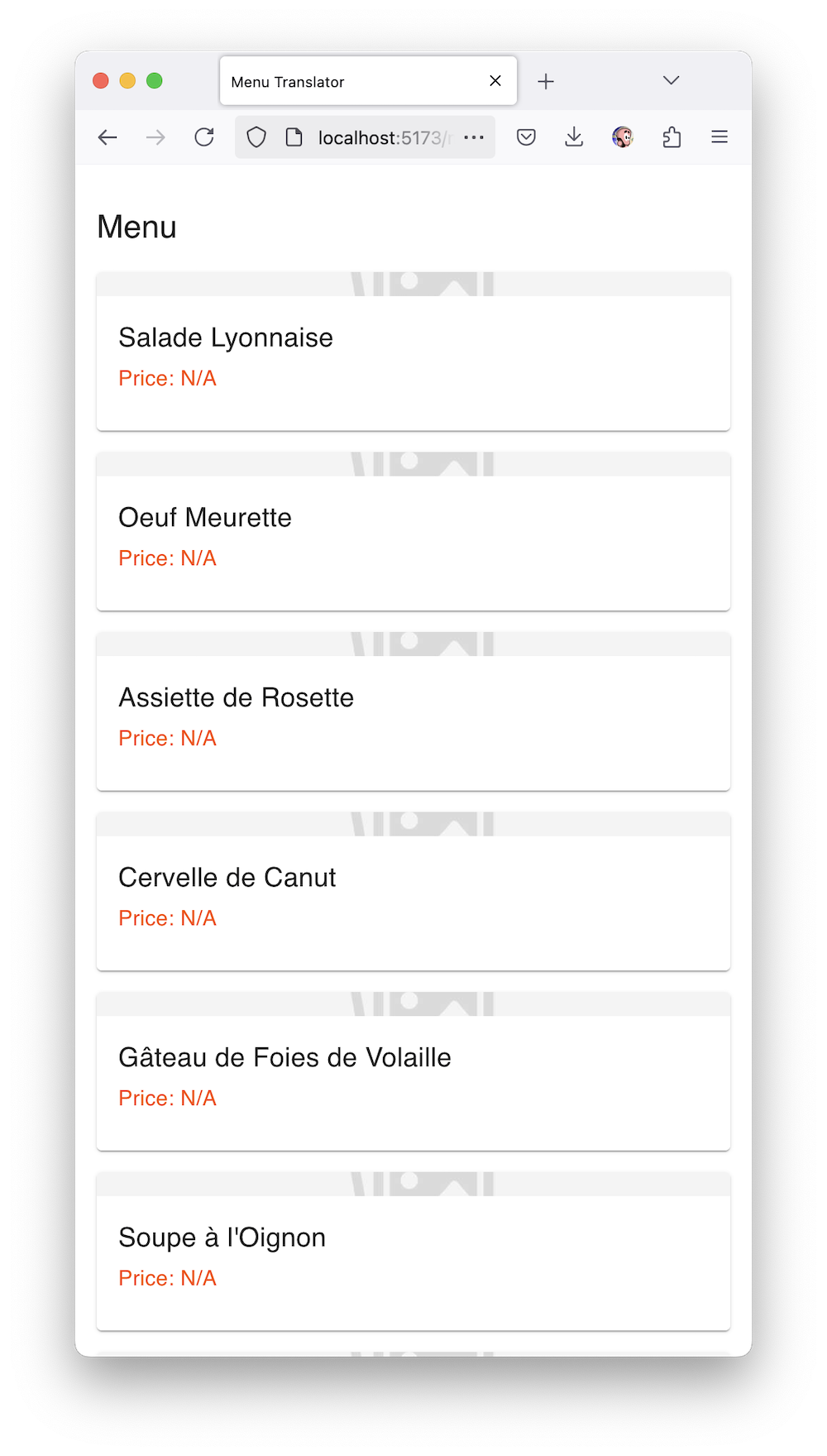
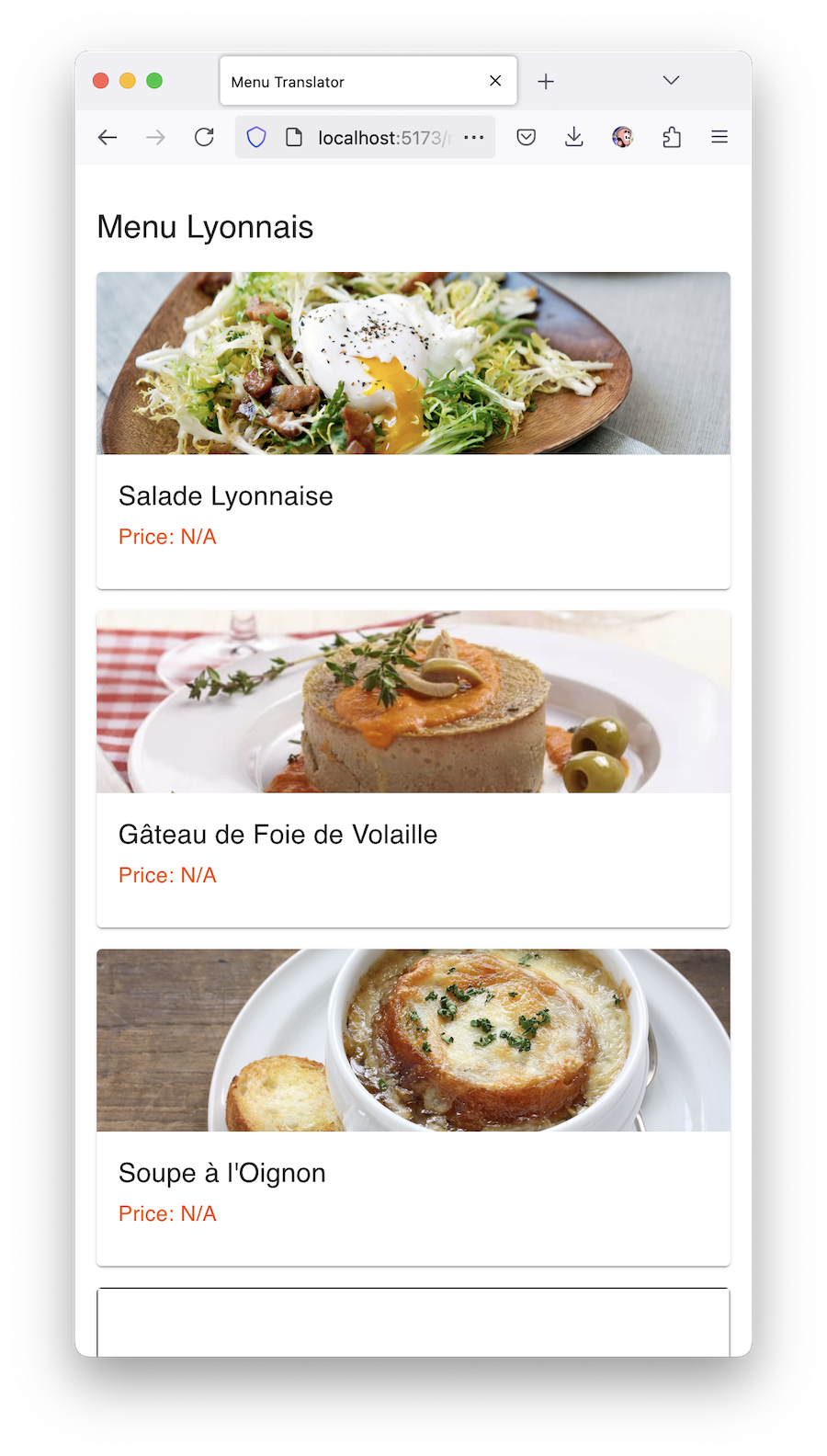
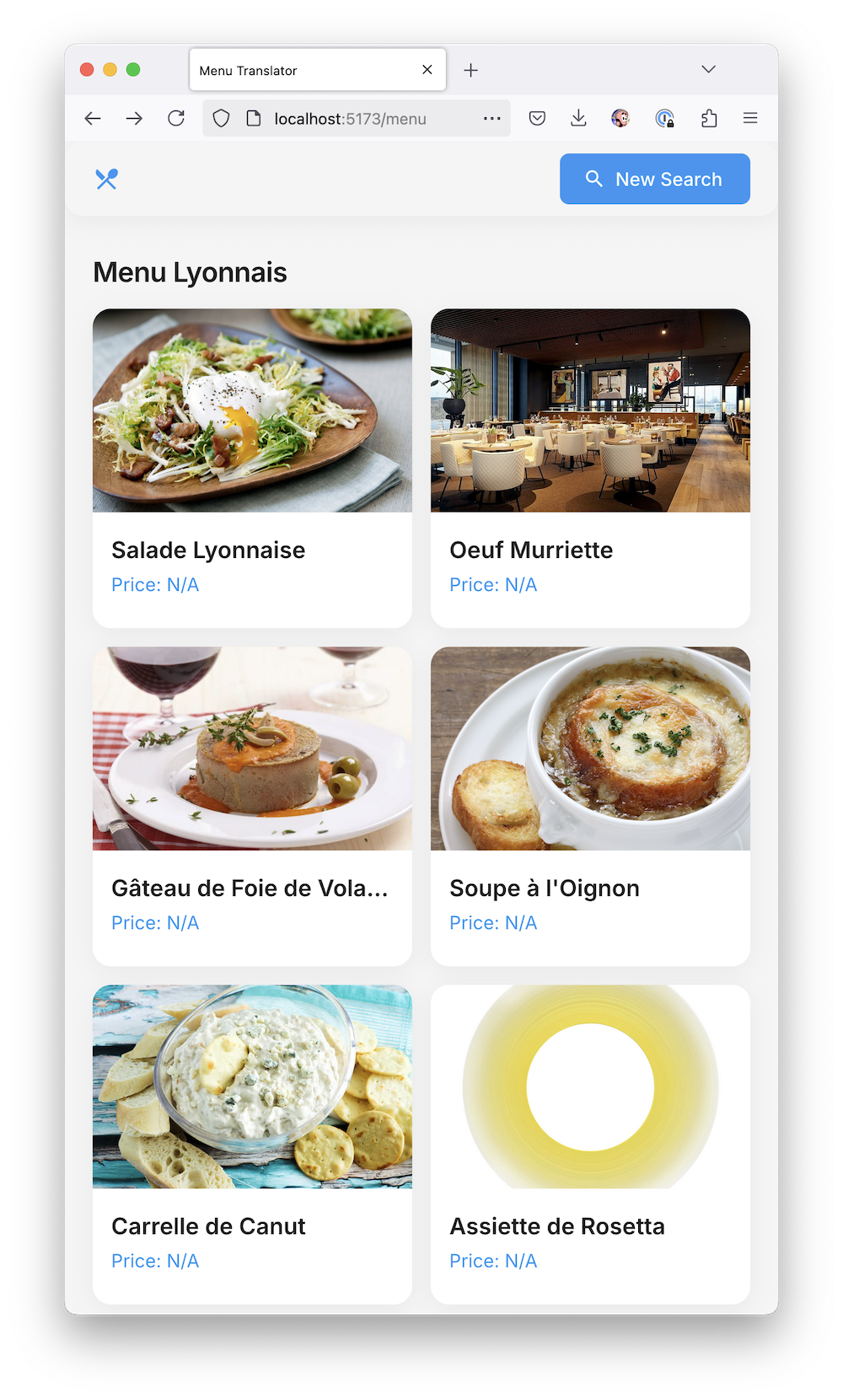
На первом экране можно выбрать фотографию меню из галереи или открыть камеру, на втором происходит анализ с красивым лоадером от Material UI, на третьем показывается само меню с изображениями блюд.
Иконку для приложения я тоже сгенерировал с помощью DALL-E, попросив добавить ей немного французского вайба. Получилось дешевое говно, но под вайб подходит. Усы он красиво нарисовал.
Первое, что бросается в глаза — очень плохо написан промпт. Результат даже не парсится, потому что ChatGPT возвращает не JSON, а просто текстовый ответ в Markdown. Но это было ожидаемо, LLM пока плохо пишут промпты для других LLM.
Потому мы поправим промпт руками, используя все наши небольшие знания о Prompt Engineering из других статей. Примерно вот так:
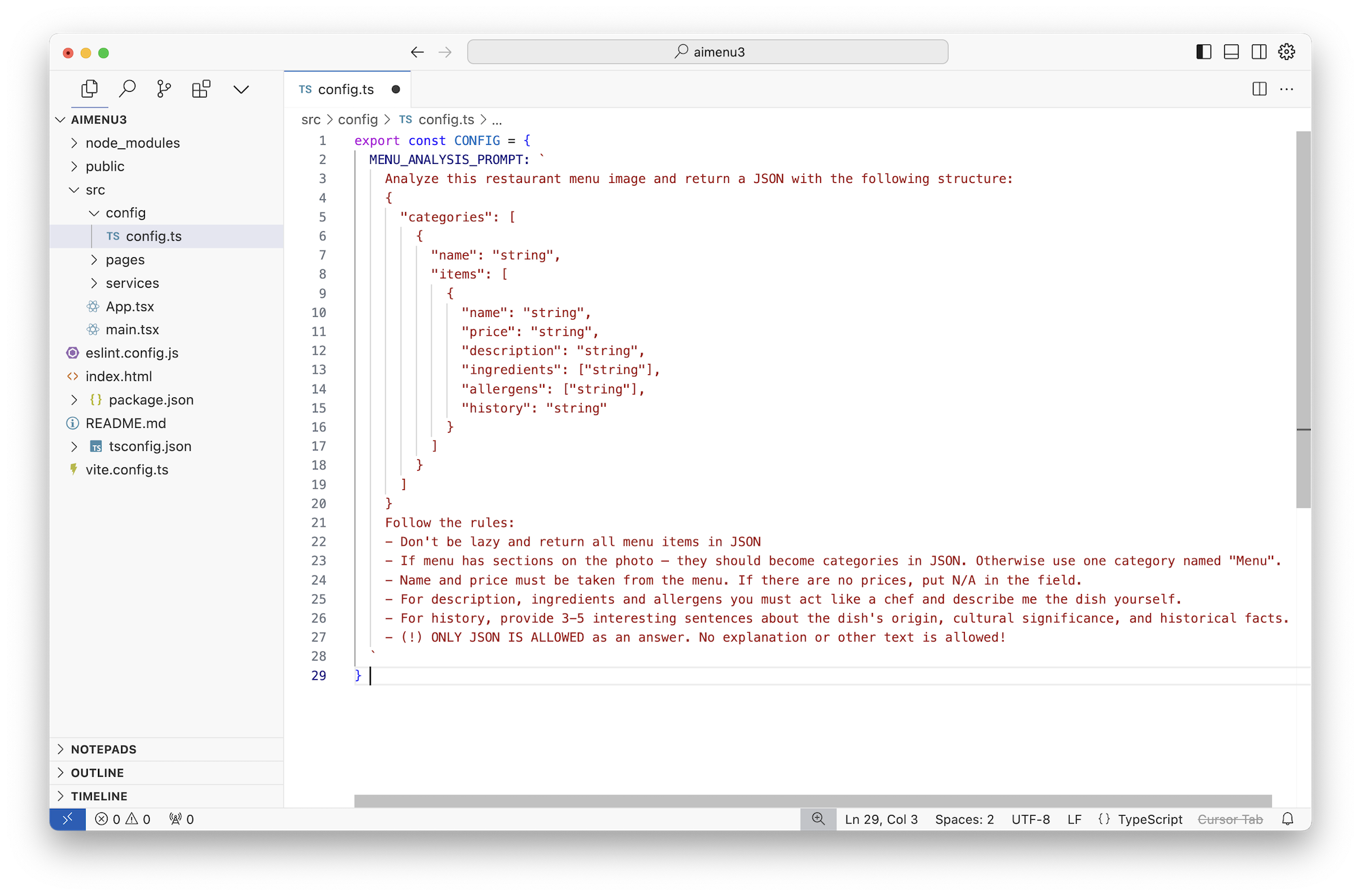
Второе, что мне не понравилось – он решил использовать Unsplash для поиска изображений. Unsplash хорош, но для нашего юзкейса подходит плохо, потому что там в основном стоковые изображения, а мы хотим реальные как из поиска Гугла. Но гугл, я слышал, дерёт много денег за свой API, может попробуем Bing?
Прям так и пишем ему:
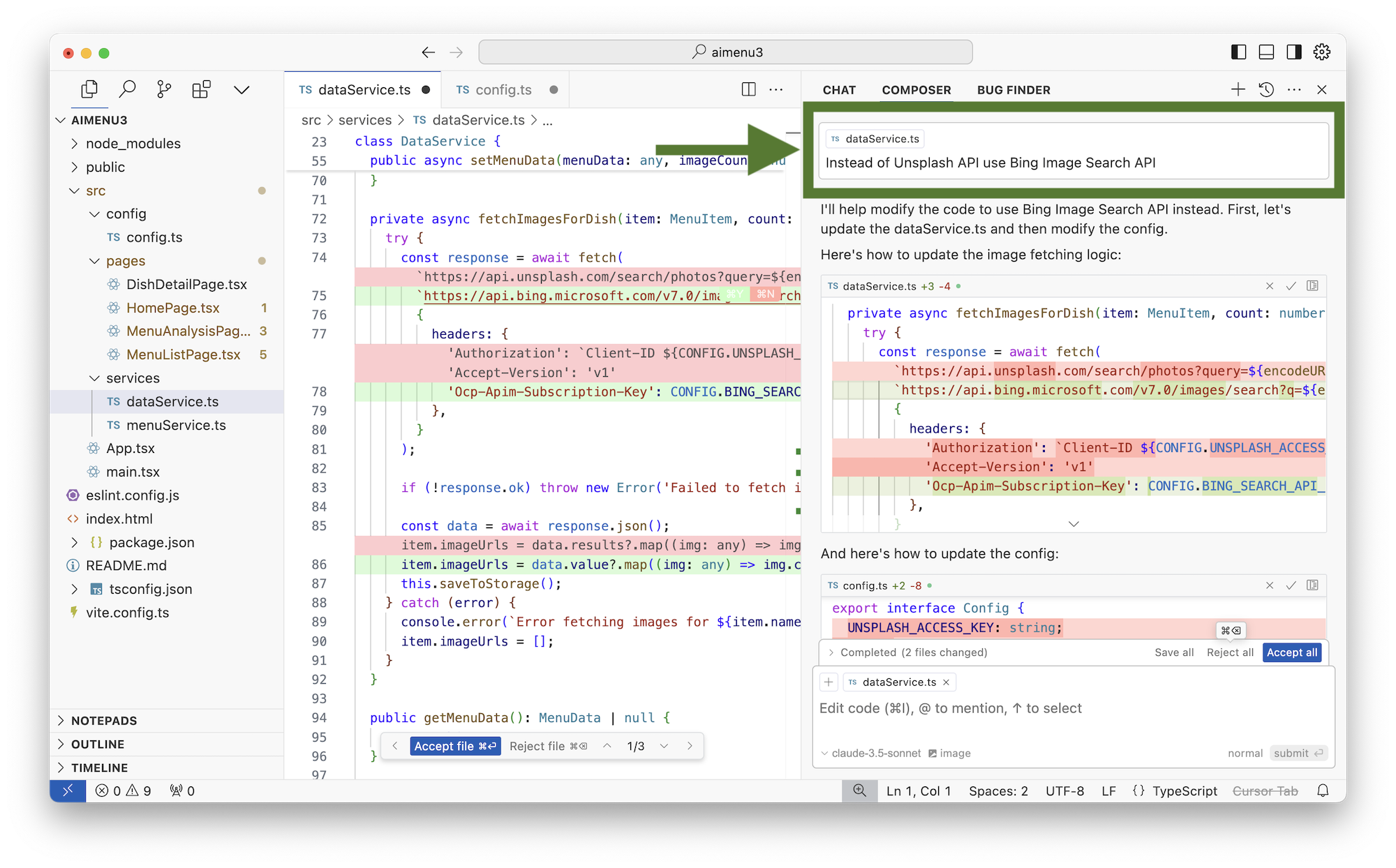
Код получился рабочим, но нам надо где-то взять ключ API от Bing Search. Для этого мне пришлось зарегистрироваться в Microsoft Azure, пройти 8 кругов верификаций, ввести данные всех кредитных карт, загрузить фотографию своей собаки, грязных трусов и заложить дом в ипотеку.
Даже несмотря на это, у меня ничего не получилось. Azure просто падал со случайными ошибками в консоли и даже не дал мне создать тестовый API ключ для поиска изображений. Я ничего не понял. В этом вопросе, к сожалению, LLM нам пока не помогут — это минус вайб.
Просто забьем на это. Microsoft как обычно сделали говно. Интерфейс Azure отвратителен.
Выбрасываем Bing, просим Cursor всё переписать на Google API. Он хотя бы не падал с ошибками и выдал мне тестовый ключ на 10К запросов. Картинки заработали.
Можно сделать еще надежнее, описав джейсон схемой формат ответа апи: https://platform.openai.com/docs/guides/structured-outputs
LLM пока плохо пишут промпты для других LLM
Это не правда. Возможно конкретно в твоем случае это не получилось, но в целом, Клод пишет довольно неплохие промпты, если норм описать задачу
ох, как же охуенно про developers! (x3) c критической ошибкой
Для гугла есть такое:
https://serpapi.com/images-results
https://docs.scrapingdog.com/google-images-api
Pricing: $75 за 5000 запросов. Ребята написали хорошую либу, да, но они поставили цену тупо x10 от цены гугла (там $5 за 1000). Это явно В2В. Не подходит совсем.
Pricing: $40 за 40000 запросов https://www.scrapingdog.com/google-search-api/
Вот тут уже цена в 5х ниже гугла ($1 за 1000 вместо $5), это хорошо, но всё равно дохуя для бесплатного приложения
Чтобы чекнуть вайб, обратимся к проблеме попроще.
Да, я хочу полностью local-first и serverless приложение. Однако, для распознания фоток через ChatGPT нам нужно где-то взять ключ от OpenAI, не хранить же его в коде в открытую.
Так что я подумал, что для бесплатного прототипа спрашивать юзера ввести ключ от ChatGPT — в целом норм. Пусть сами платят за ChatGPT по мере использования. Потом сделаем платную версию со своим ключом.
Прошу Cursor модифицировать экран анализа меню так, чтобы он спрашивал OpenAI ключ и сохранял его в локальное хранилище для дальнейших запросов.
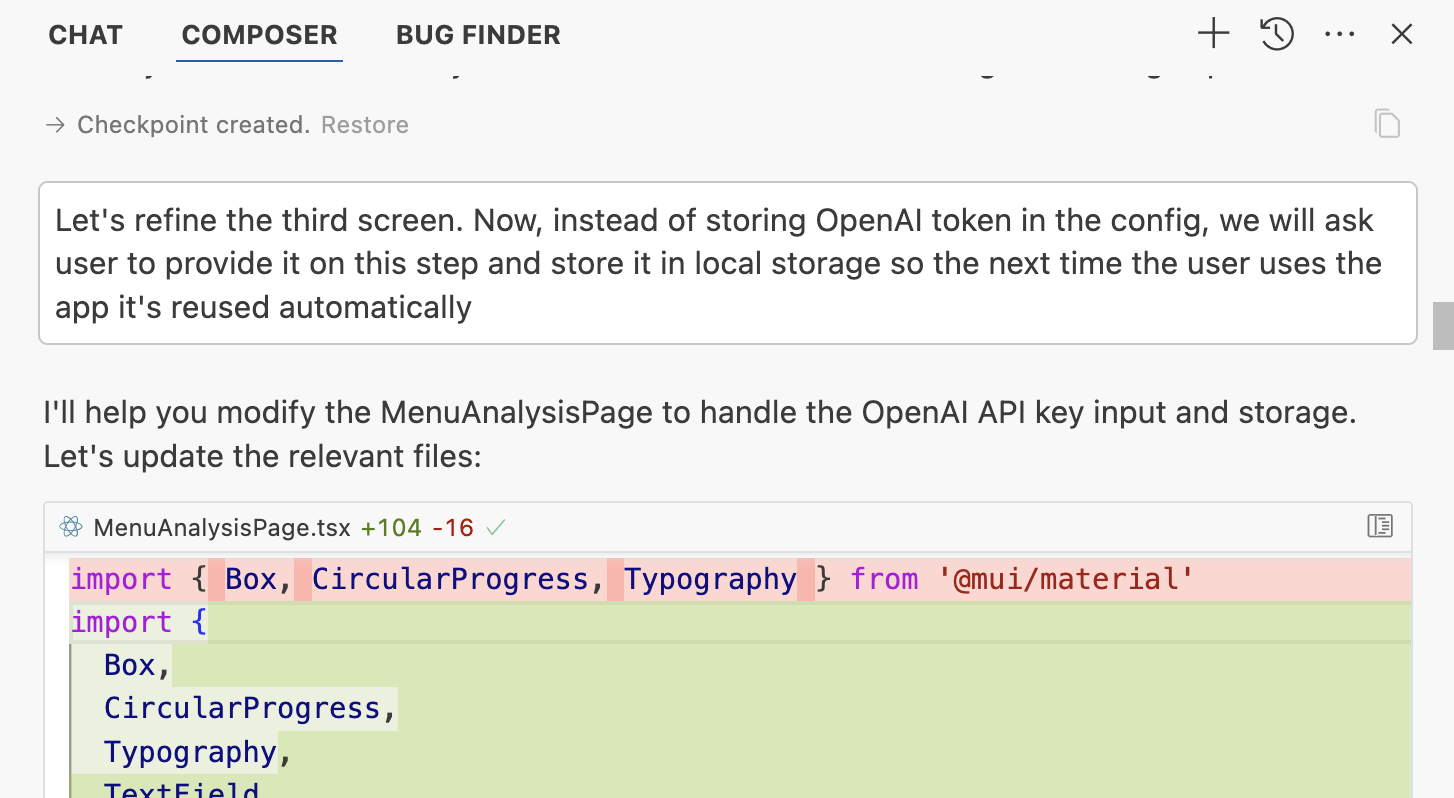
Применяем, сохраняем, применяем — да, работает! Плюс вайб!
Но чего-то еще не хватает...
После загрузки изображения нам долго показывается экран «Analyzing image...» во время которого происходит много магии типа конвертации картинки в base64, загрузки её через OpenAI API, и получения длиннющего JSON'а в ответ.
Процесс занимает секунд 20-30 — а это крайне грустно для пользователя. Он может заскучать, впасть в депрессию, пойти смотреть PornHub или вступить в партию Зелёных — а это точно минус вайб.
Самым простым UX решением в это время будет показать ему загруженную картинку, чтобы он в неё втыкал и не скучал!
Попросим:
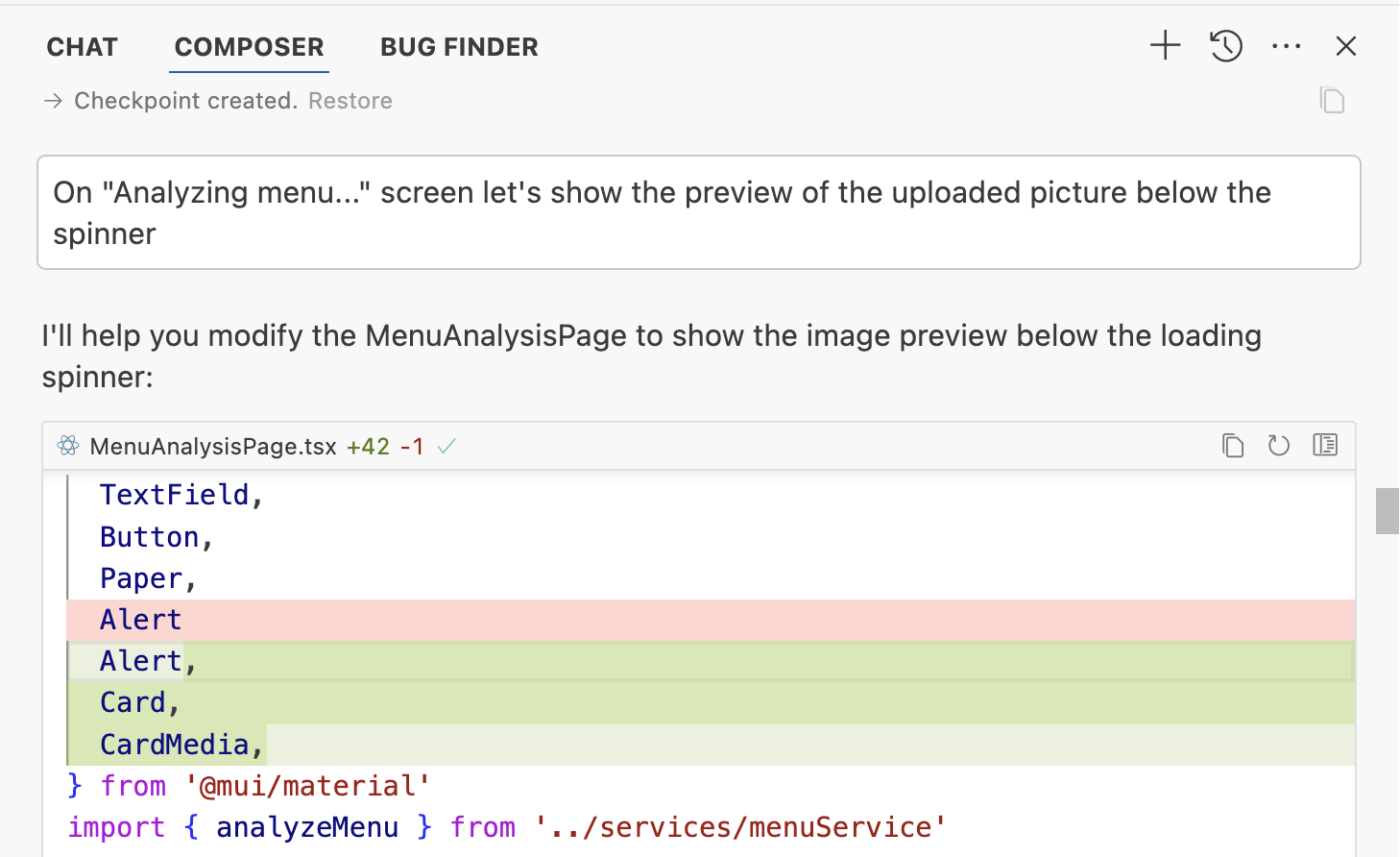
Вот теперь экран загрузки выглядит поинтереснее. Можно смотреть на свежую фотку и пытаться самому прочитать названия, пока там LLM пыхтят-стараются...

Оффтопик: я только сейчас понял, что ведь Франция — единственная страна в ЕС, у которой есть свой GenAI. Я уверен, это потому что они тоже им свои менюшки читают!
Окей, всё как-то даже работает, но ощущение от нашего нового «стартапа» пока какое-то не то!
Наверное потому что он выглядит как вырвиглазное говно, как будто его айтишники писали.
Я из своего опыта знаю, что MUI по-умолчанию выглядит всегда, мягко говоря, аскетично. Просто он ждет когда вы пропишете ему в табло какую-нибудь весёлую тему!
Но я понятия не имею какие темы сейчас в моде, а гугление «material ui themes» выдает кучу платных шаблонов за $66, а платить деньги капиталистам — это минус вайб.
Так что мы применим магию LLM снова и просто попросим его: «чот наше приложение выглядит как говно, дай ему красивую модную современную тему для MUI». Не смейтесь, это работает.
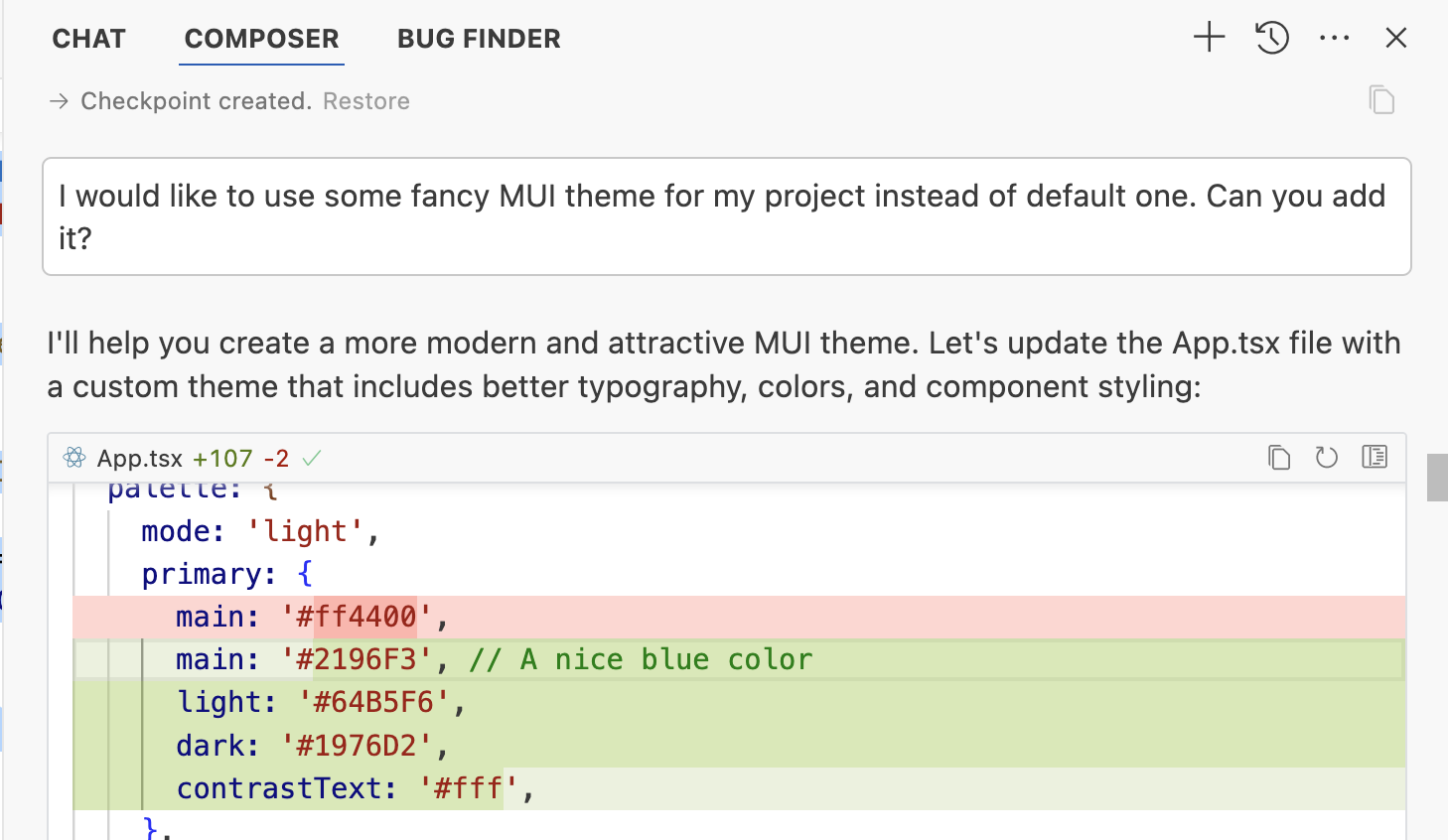
Ма-а-а-аксимальный плюс вайб!
Работает херово, но зато красиво!
Только, блин, подождите. Какая-то ошибка вылезла. Но мы уже так разогнались на вайбе, что приговорили три бутылочки пивандрия, так что не дело это самим разбираться что произошло, пусть кнопка «Починить с AI» работает за нас.

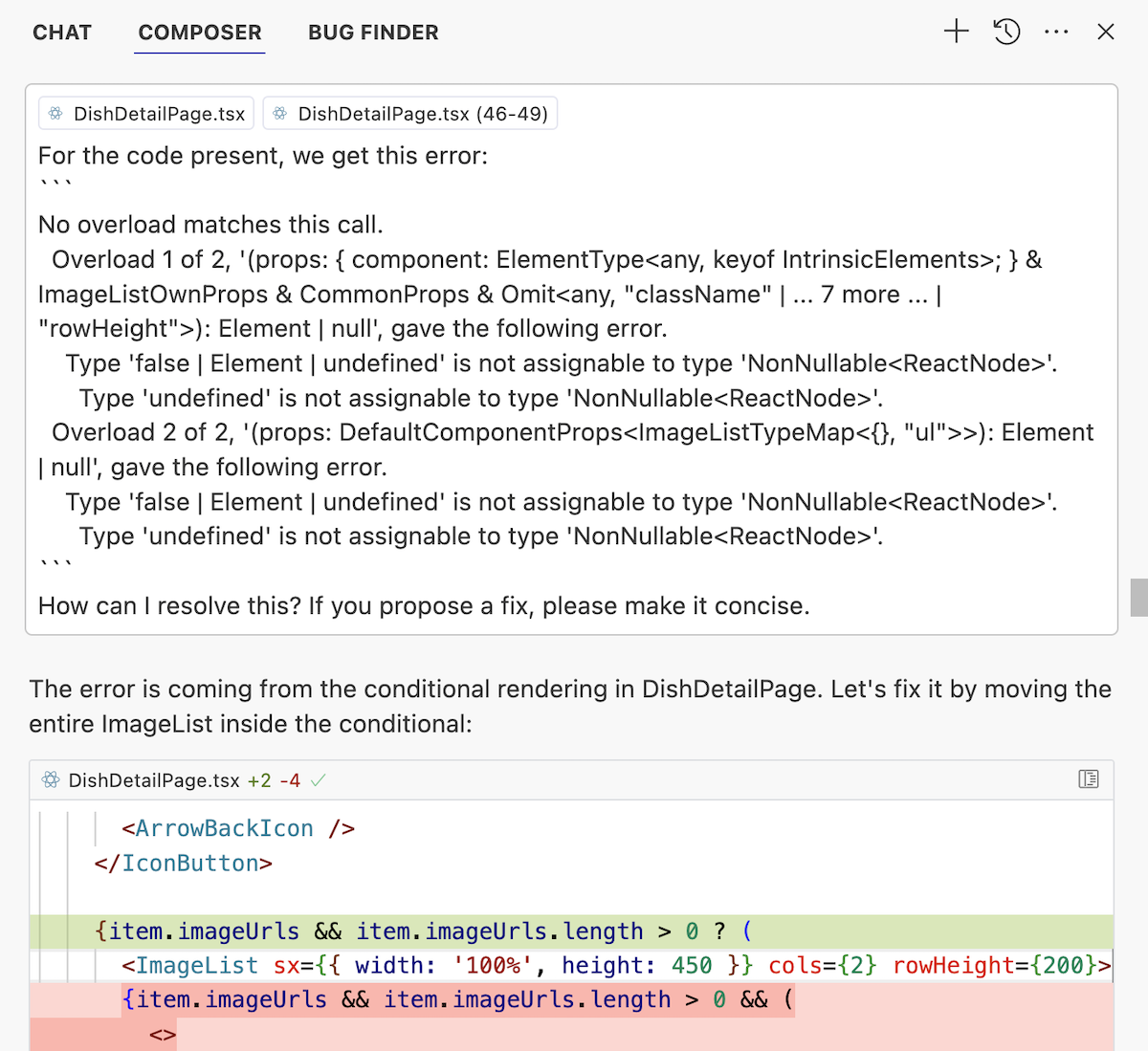
Вот теперь другое дело!
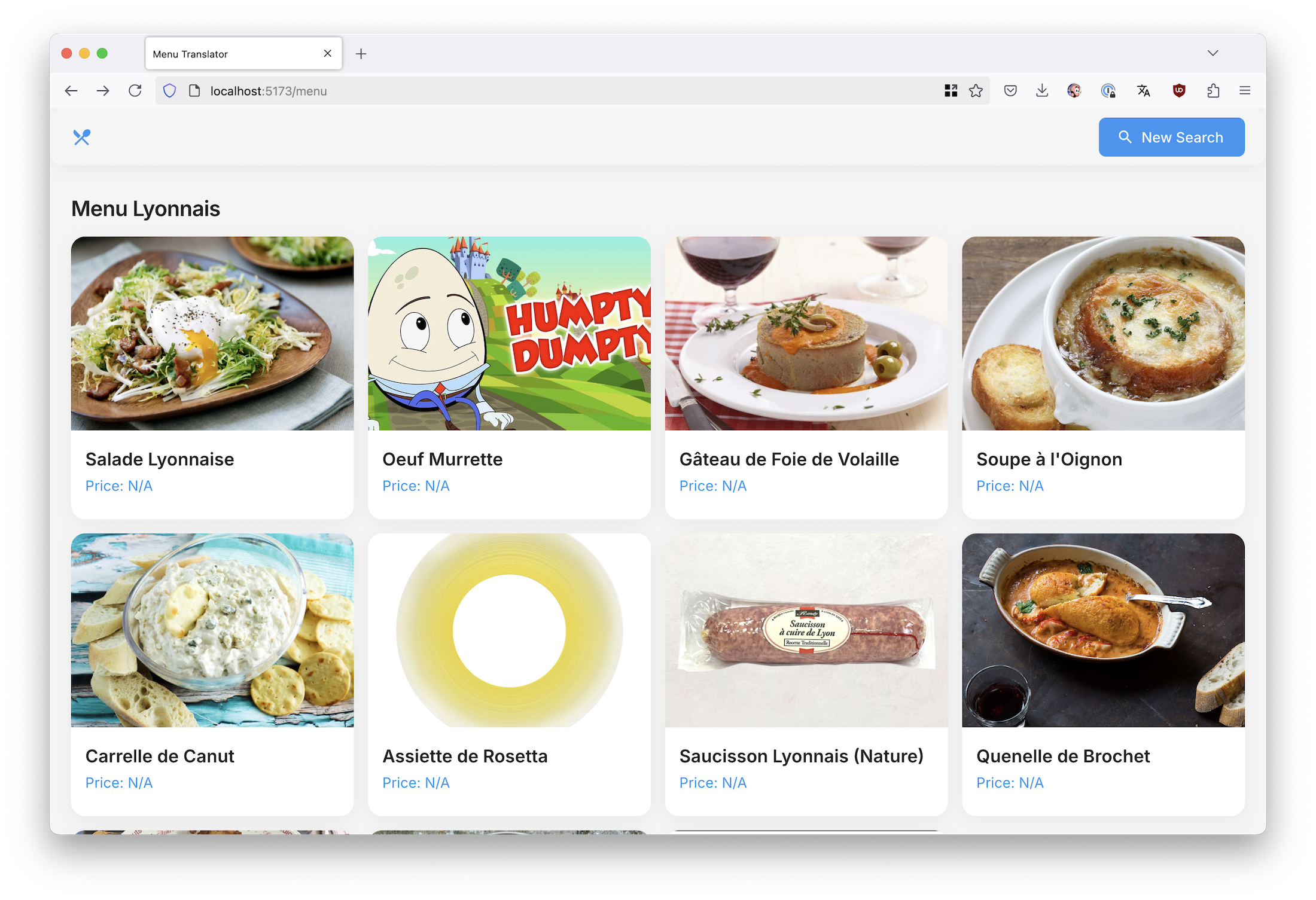
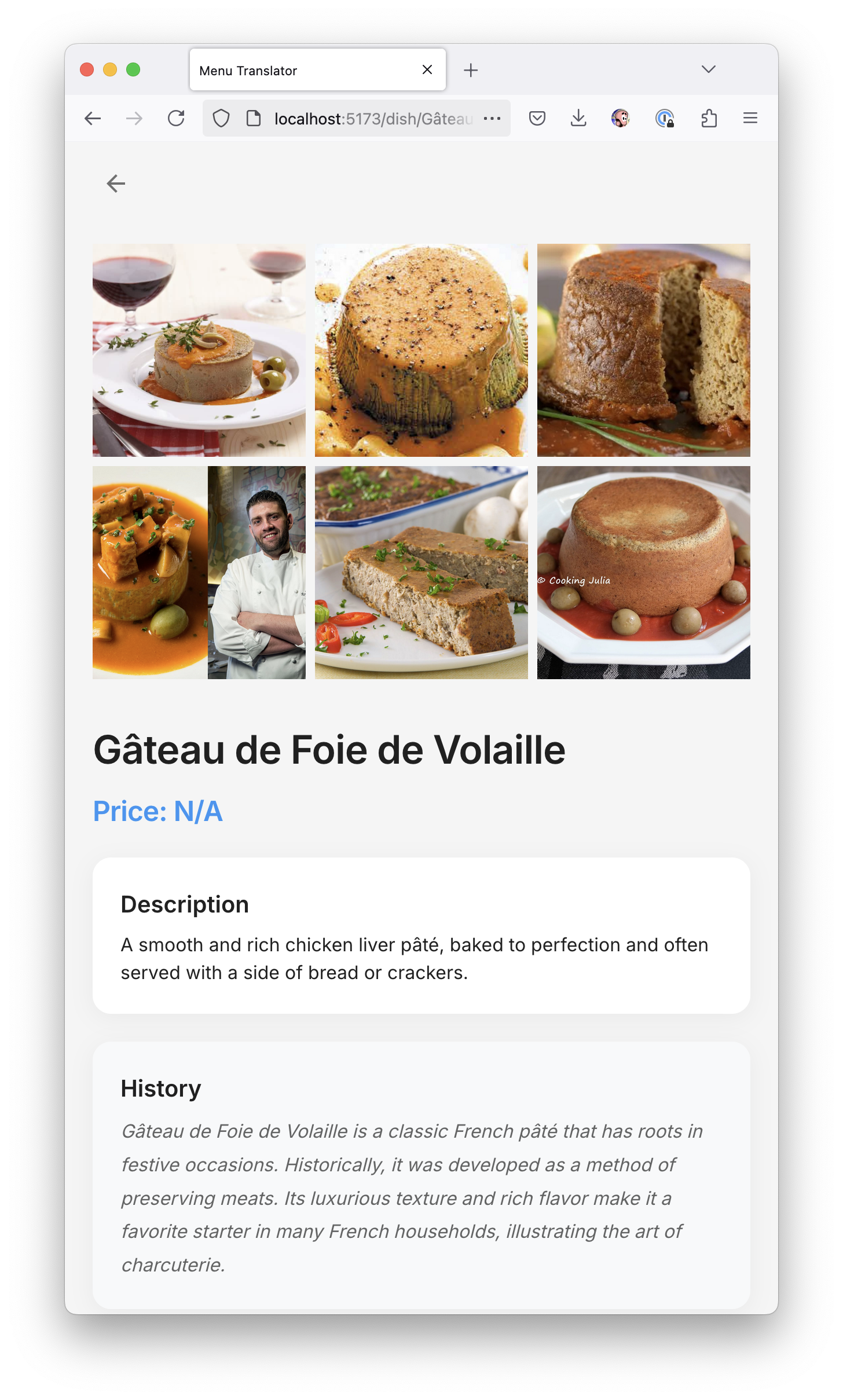
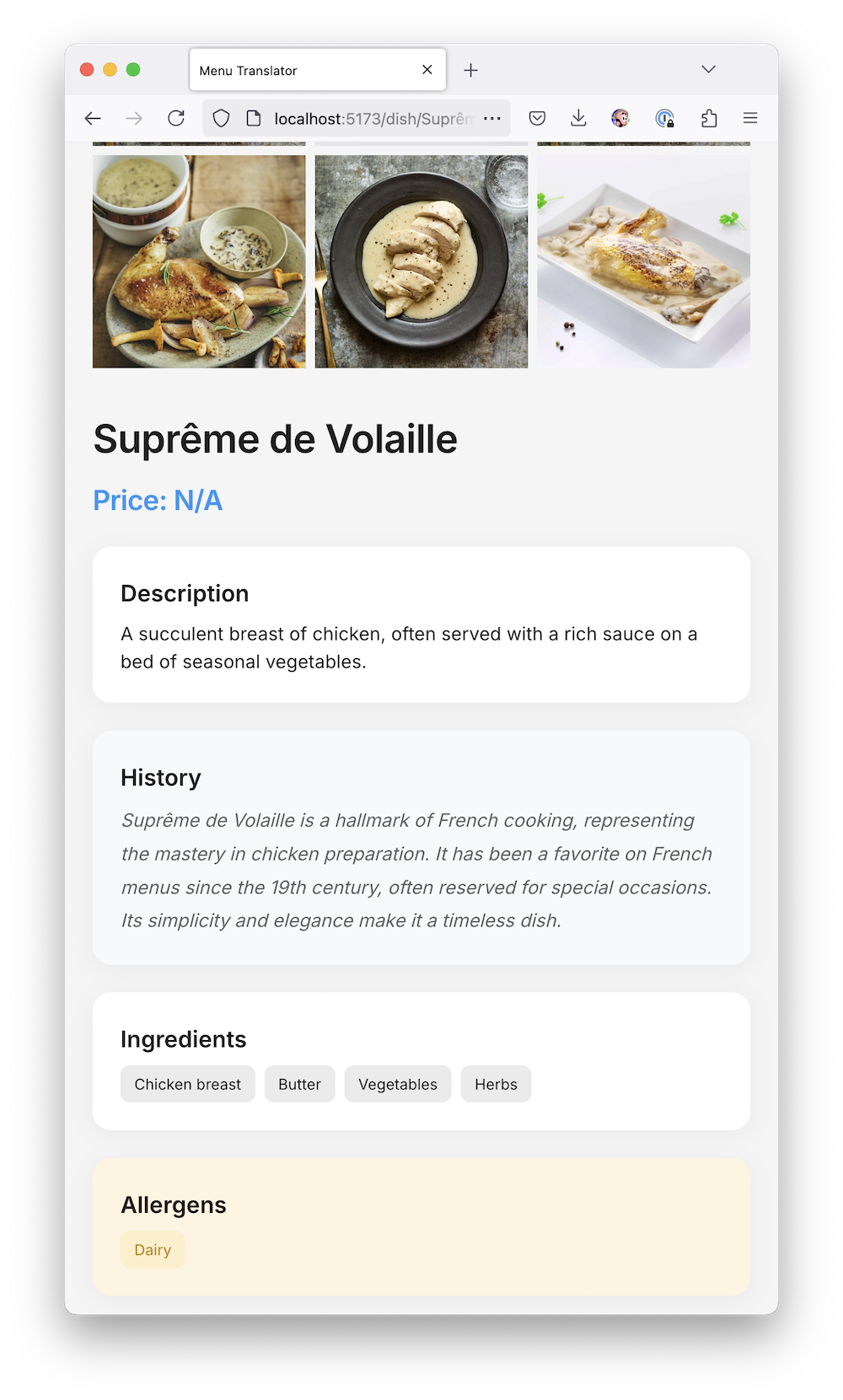
Наш «стартап» почти готов к выкладыванию на гитхаб и собиранию лайков в твиттере. Он реально работает как я хотел — берёт фотку, берет ключ от ChatGPT, парсит меню, делит его на категории, показывает список блюд с их фотками, даже рассказывает про ингредиенты, историю блюда и аллергены.
Веганам или аллергикам можно прям сразу платную подписку продавать. Или упороться по в B2B и генерировать ресторанам красивые AI меню с фотками на каждый день.
Но все-таки остается один нюансик, который не даёт мне права выложить это всё на Github Pages и порадовать вас всех — там всё еще используется Google Image Search, который стоит $5 за 1000 запросов.
Я даже провёл отдельный рисёрч с моими вымышленными друзьями-профессионалами из ChatGPT Pro. Оказывается, в современном интернете реально не существует открытого и бесплатного API для поиска картинок.
Полный пиздец.
Нет, вы просто вдумайтесь. Мы научились запускать автомобили в космос, ездить 500 км/ч на поездах, изобрели искусственный интеллект, но ДО СИХ ПОР у нас нет способа бесплатно найти картинки омлета с беконом по запросу «омлет с беконом». Google, Bing, и прочие хотят за такую роскошь $5 за 1000 запросов.
1000 запросов — это смех. Если в вашем меню хотя бы 100-200 блюд, то за каждую фотку вы должны заплатить гуглу ОДИН доллар. Пиздец. Так мы стартап не сделаем. Минус вайб.

Я сожрал 2500 из своих 10К бесплатных запросов просто за пару часов разработки. А просить юзера принести еще и API ключ от Google — сразу мертвая идея, я сам несколько часов потратил на его получение.
Я даже пытался найти другие решения. Я пытался забить на фотографии и генерировать картинки блюд из меню через DALL-E, но там очень драконьи лимиты, одна картинка генерируется секунд двадцать, а все меню займет пару часов и много десятков долоров по цене.
Я пытался использовать Web Scraping вместо API, но тут ни Sonnet, ни ChatGPT, мне не помог — ни один поисковик (даже сраный Pinterest) не дает нормально скрапить изображения по запросу.
А вижуал — это самое главное в стартапе. Ты можешь сколько угодно круто распознавать каракули французских рестораторов, но если ты не можешь показать картинки их блюд — ты проиграл.
Так вот я тоже проиграл. Пака!
Код я, конечно, выложу, но демо не будет: https://github.com/vas3k/stuff/tree/master/javascript/aimenu
Как будто-бы разных блюд сильно ограниченное количество. Экономика должна сойтись если кэшировать фотки блюд по названиям. Можно находить похожие названия из закешированных тупо на сервере, а потом прямо в запросе к ChatGPT спрашивать "это то или не то" чтобы удостовериться.
Споткнулся о ту же самую боль с image search api когда делал своего тележного бота @pic (а то он уж слишком цензурированый и мемы свежие не выдает) а теперь думаю, а для поиска фото блюд можно и его заюзать через telethon или типа того
Тоже подумал, что надо изначально собрать список блюд типичных для французской кухни и на сервере сразу сохранить все их фотографии. Пусть их будет хоть даже 1000
Затем надо завести какое-то векторное хранилище в котором мы сможем проверять название блюда из меню (чтобы хорошо метчить нечеткие дубли и авторское наименование).
И вот тогда мы сможем ходить в хранилище гугла только за обновлением кеша.
Вроде бы для демок самое то использовать неофициальное API duckduckgo. https://github.com/Snazzah/duck-duck-scrape и подобное.
Паша Куликов, попробовал. Но нет, оно работает только с серверным Node.js, с фронта не работает. Сервер делать не хочется совсем, его быстро вычислят и забанят. Нужна такая же либа, но для фронта!
Тру вайб будет просто генерировать изображение еды с помощью dalle. Ключ тот же, картинки получатся скорее всего похожими на настоящее блюдо (ну или произойдет кек).
Да, я там дальше пишу, что так и пробовал. Если написать в запросе еще что-то типа "фотореалистичное фото блюда на столе в ресторане" — то получается даже весьма неплохо (немного мультяшно, но под вайб подходит и детали блюд довольно хорошо просматриваются)
Но DALLE работает очень долго и генерит по 1 картинке за раз, так что не вариант оказался
А что если википедия? Там про многие блюда есть статья, картинка тоже будет
Denis Shepelin, есть же канал с нейрорецептами в тэгэ, надеюсь будет получаться примерно МЯС ОГУРЕЧНЫЙ (42 Кбит)
Можно поступить также, как делают с гугл-транслейтом, когда вместо интеграции просто открывают страничку с текстом подставленным — т.е. генерировать ссылку на поисковый запрос в картинки и уж какое блюдо заинтересует, можно в него ткнуть посмотреть картинку.
Дальше я начал играться со своим новым стартапом и просить Cursor и Sonnet улучшать его всё больше и больше. Я добавил dataService, который кешировал данные в модели, сохранял их в Local Storage и даже позволял из него посмотреть историю сканирований.
Я расширил промпт, чтобы ChatGPT возвращал мне еще и историю блюда, из какого оно региона и как его едят.
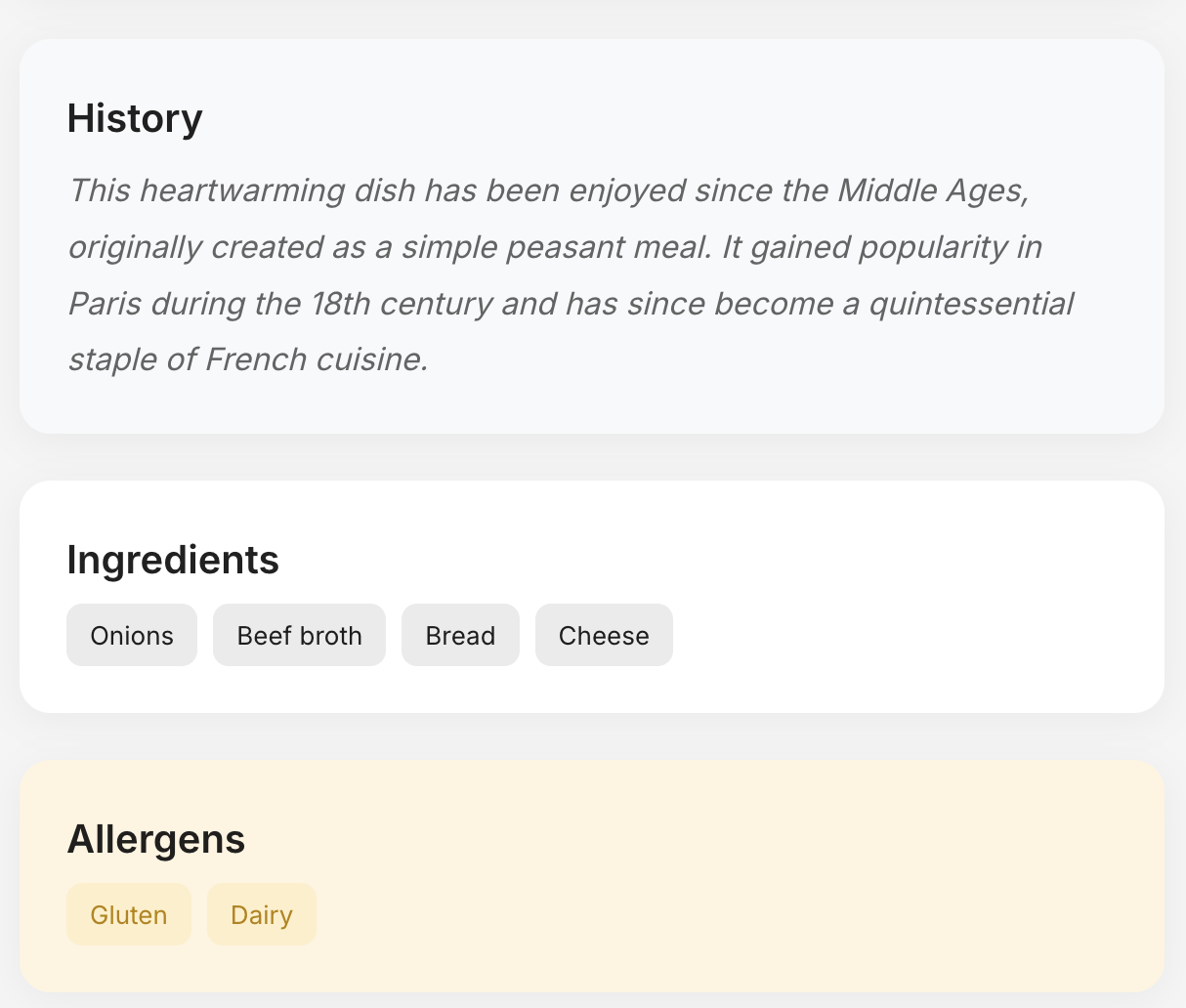
Пытался поиграть с ранжированием, типа просить ChatGPT проставить каждому блюду в меню рейтинг по нескольким параметрам, чтобы я мог выбрать самое интересное блюдо в этом ресторане. Но получилось говно и я забил на эту идею.
Чот вайб к этому моменту уже ушел.
Жаль у нас не получилось стартапа, но всё равно я очень круто провёл вечер!
Когда AI — твой личный джун
Собирать админки и лендинги стало проще, чем когда-либо. Ты просто кидаешь OpenAPI, указываешь фреймворки, и AI такой: "Понял, принял, начал писать" 💻.
Правда, иногда он явно не понял, не принял и написал полный хаос. Но если задать четкие правила и аккуратно разложить файлы, выходит вполне годно.
🔧 Как это выглядит на практике?
80% кода пишется автоматически.
20% — ты сидишь и чинишь то, что натворил этот цифровой джун.
Иногда смотришь на код и задумываешься: "А не заменить ли тебя на ChatGPT?"
🚀 Почему это кайф?
Сложные штуки делаются за 1–2 дня. Да, AI косячит, но разве джуны не делают так же? Только вот этот не просит повышения зарплаты 😆.
Вывод: AI как инструмент — топ, если знаешь, как его готовить. Жесткие рамки, четкие правила, минимум доверия — и можно собирать проекты быстрее, чем когда-либо.
Из последнего понравился Codeium, те же яйца только в профиль)
Подводя итоги, у меня есть три вывода:
1. Чем дольше вы общаетесь с LLM, тем хуже он пишет код.
Недавно где-то читал рисерч, что чат с LLM лучше время от времени «перезапускать», потому что он «тупеет» с ростом истории или размера контекста. В вайб-кодинге это прям хорошо видно — со временем он начинает больше «портить» код, чем помогать.
Если в самом начале вы вносите буквально 1-2 правочки в сгенерированный код, чтобы всё заработало, то теперь уже приходится переписывать 10-20% LLM лапши каждый раз.
В какой-то момент баланс смещается с «я дофига продуктивный, LLM мне помогает кодить» в сторону «какого фига я трачу больше времени на исправление его ошибок, чем на написание кода».
LLM — это реально кодинг с джуном :)
2. Когда проект перерастает стадию «прототипа», с ним опять становится проще работать «по-старинке».
С одной стороны, разрабы Cursor проделали неплохую работу по запихиванию всего необходимого в контекст LLM, включая зависимости, соседние модули, итд. При желании можно добавить туда что угодно еще, сославшись на файл или целую папку через "@". Так что если он у вас что-то «не знает» — это skill issue.
С другой же стороны, контекст LLM всё равно ограничен. И из предыдущего пункта мы знаем, что ограничен не столько технически (лимит токенов довольно высокий у современных моделей), сколько тем плавающим моментом, когда модель начинает магически «тупеть».
Так что «рисовать большим мазками» из общего чата получается хорошо на маленьких проектах (или микросервисах), но когда они вырастают хотя бы до уровня продакшен-аппа — больше времени начинаешь тратить на очистку кода от мусора, чем если бы писал его с нуля.
Так что в средне-больших проектах, вместо большого чата, я начинаю чаще использовать LLM-редактирование непосредственно внутри файла (Cmd+K которое) и накладываю изменения постепенно, контролируя каждый шаг.
Типа «перепиши мне эту функцию так, чтобы принимала на вход не объект файла, а сырые байты» или «добавь индикатор загрузки в этот react-компонент». Ну, короче, стандартное программирование с LLM, мне кажется уже все на него перешли.
Но это уже не вайб-кодинг.
3. Нас всех ждет куча говно-вайб-кода в продакшене.
Сейчас вайб-кодинг станет популярным и мы все потонем в куче говно-прототипов и ужасных по качеству коммитов на гитхабе. Вангую, что термин приобретёт супер-негативную окраску и вайб-кодеров будут гнать из уважаемых мест ссаными тряпками.
Так что дома с прототипами развлекаться — это одно, а тащить вайб-код в прод — уже совсем другое. Но как и с любым попсовым инструментом это неизбежно.
Если я все-таки решу допилить свою эту идею и сделать из нее продакшен сервис — я перепишу всё с нуля. Тоже не без помощи AI, конечно, но уже под полным своим контролем за фронтендом и бекендом.
И платным доступом, конечно же! :3
плюс вайб! 🥲
Концепт script kiddies 2.0 в студию!
Но если серьёзно, то это великолепный способ зайти за 20 минут в незнакомую тему. Если нужно на коленке накатать "чего-то что б посмотреть как оно примерно выглядит", что раньше упиралось в вопросы про каков минимальный бойлерплейт, как его билдить, и куда потом совать бизнес-логику, то ныне эти три вопроса решаются как в статье.
А попробуй, ради фана, то же самое, но с (Ader)[https://aider.chat/] в режиме (архитекта)[https://aider.chat/docs/usage/modes.html]. Оно весьма толковое и в новых релизах пишет овер 50% своего кода само.
во, тоже ждал что будет плоттвист про aider, потому что там мне кажется прикол что из-за того что интерфейс не такой секси ты в итоге быстрее переходишь к этапу что сам код пишешь, а потому тебе не так заметно что там было много косяков от LLM
Imilov, о, не слышал про него, надо потыкать
а меня еще пугают, что еще и тестировщиков AI заменит. но, так понимаю, либо разработчиков, либо тестировщиков, иначе риск получить неработающее говно стремится к 100%
Ian Kotik, ну если еще и пользователей заменит, то выйдет полный уроборос
Сейчас учу французский и понял, что нет приложений для тренировки неправильных глаголов, а стандартные методы типа anki для этой цели работают хуево.
Решил попробовать еще более простую реализацию prompt-to-app идеи - bolt.new
С первой итерации получилось огонь: авторизация, карточки глаголов, прогресс, механика тестирования и интервальное повторение. Все работало.
Потом пытался довести проект до продакшен-реди состояния: подписки, больше времен, премиум фичи. Ну и все сломалось к хуям, надо делать заново.
В итоге ты получаешь на 80% готовое приложение за полчаса, а оставшиеся 20% пройти просто нереально (если самому не лезть в код).
Вот последняя живая версия, если интересно (авторизация скорее всего поломана)
https://frenchirregular.com/
Как гипотеза - можно собрать свою базу с фотками блюд) если чего-то нет, то запрашивать по апи и сохранять. Хз, сработает ли такое для множества экзотических названий блюд во франции)
Как, по твоему мнению, сколько еще лет до полного перехода на программирование через LLM? Когда программисты станут не нужны? (ну хотя бы 90% программистов)
Вастрик, вот коротенькие видосы про него: https://www.youtube.com/@AICodeKing/search?query=aider
Vladimir Onyshchuk,
Честно говоря, я не думаю, что LLM кого-то заменит в классическом смысле. Ну то есть вряд ли мы увидим на улице бомжей с картонками «я был программистом, но меня заменили LLM и я больше не нужен». Причем сразу по многим причинам:
LLM все еще не пик развития AI. Это локальный максимум, да, очередная вершина прогресса, достигнутого человечеством, но мы уже начинаем видеть ограничения LLM и иногда даже разочаровываться в них. Ученые типа Яна Лекуна уже давно заявляют, что LLM это тупиковый способ достичь настоящего ИИ. Они могут бесконечно хорошо притворяться «человекоподобным интеллектом», но настоящий AGI будет не LLM-based, это будет что-то новое. А значит нас ждет веселое десятиление LLM-хайпа, а потом очередная "ИИ-зима".
Программисты выучат LLM просто как еще одну технологию в своём резюме. Программисты не «женятся» на одной технологии на всю жизнь — так просто не бывает. Тут каждый год приходится учить новые фреймворки, языки, подходы. LLM просто станет одним из. Когда появились облака, docker и k8s, все тоже говорили «вот теперь админить сервера больше не нужно будет» — и чо? Мы наблюдаем абсолютно обратную ситуацию — появление армии DevOps'ов и InfraEngineer'ов, которые только и занимаются тем, что эти k8s'ы настраивают.
Мы уже видим, насколько "LLM-хайп" в СМИ отличается от реального их применения (ну, те, кто попробовал). В утренних газетах могут хоть каждое утро рассказывать сколько инженеров заменит новая железка от NVIDIA, а по факту же LLM хорошо справляется лишь с простейшими кейсами и прототипами, типа описанного в этом посте, потом что их и раньше писали килотоннами и LLM просто воспроизводит куски из них. Но как только дело касается хоть чего-то, чего раньше не существовало — LLM сразу становится беспомощным котёнком.
Короче, никого не «заменят». Да, джунам будет сложнее вкатываться — это факт. Да, крупным корпорациям придётся адаптировать найм, ведь больше LeetCode не поспрашиваешь. Да, скорее всего из-за этого привычные нам паттерны трудоустройства перестанут работать, и какая-то тряска произойдет (но она уже происходит не из-за LLM)
На большой картине же мы просто получим новый вид программирования (или даже новую роль), когда вместо ленивого нытья на дейли про «нууу этот прототип потребует 3 недели разработки и нам нужно выбрать фронтенд-фреймворк для начала» появятся люди, которые «ребят я тут на-вайб-кодил вечером нам прототип новой системы, давайте потыкаем, сравним, может нашим клиентам надо такое»
Переписывание микросервиса с одного языка программирования на другой отныне тоже задачка на неделю, а не эпик на полгода. Короче, программирование ускорится и в нём останется самая интересная часть — «творить», а рутинные части «кодить CRUD-дашборды» автоматизируются.
Может этими людьми вообще станут продакты. Или может больше программистов перейдут в продакты. Посмотрим.
TL;DR: вместо «операторов ЭВМ» будут «операторы LLM».
Корпорации заработают еще больше деняк из-за увеличенной производительности труда, а простой Васян получит 2.5% индексации к з/п и продолжит ходить в офис с 9 до 7 и ненавидеть свою работу
Прошлой весной был в Италии, тоже столкнулся с отсутствием вменяемого меню в большинстве мест, и решил - что вот он, мой шанс разбогатеть!
За пару вечеров навайбкодил с Курсором MVP - генератор цифрового меню для ресторанов https://bestmenu.app/ (тут пример готового меню - https://bestmenu.app/pizzeria_mediterranea)
Киллер-фича, как я тогда думал, будет такая
Мне бы на месте владельца/работника ресторана, было бы влом вручную вносить позиции меню - и поэтому сделал фичу - ты просто фоткаешь бумажное меню, сервис делает магию (стучит в chatGPT) - и пользователь получает qr код на цифровое меню, с картинками из интернета
Тоже столкнулся с проблемой апишки для поиска картинок, но в итоге решил, что разновидностей блюд в мире ограниченное количество, поэтому просто сначала пробую найти картинку в своей базе, если не нашел - иду на гугл (ну и обновляю свою базу, чтобы в след раз не тратить долор)
Но в итоге оказалось, что таких сервисов куча в каждой стране, и не то чтобы владельцы ресторанов выстраиваются в очередь, чтобы внедрить их себе
Так что проект просто пылится, но опыт был прикольный
Roman Ventskus, о, брат!
Мне нравится такое будущее 😜
Доступ к технологиям стал проще, можно свои проекты пилить без кучи $$$
Не обязательно использовать агентов (composer) для вайб-кодинга.
Да и в целом композер херня и руинит оч сильно. Если уж хочется тру вайба то нужны тулы типа OpenHands или Roo Code, но они по деньгам не так выгодны как курсор.
В кусроре есть режим Chat, который как бы полуавтоматический. Сам он не вставляет код куда нужно, но делается это одной кнопкой.
Зато - проще менеджерить контекст, удобно и быстро посмотреть дифф чтобы он не сделал дичи и ещё и соннет в этом режиме работает лучше (ни разу не было такого чтобы удалила какой то код, в композере это частая история).
В общем в Чат-режиме нет большей части проблем, что описывает Вастрик. Очень рекомендую использовать именно его, тогда и вполне себе production-ready код получается без лапши и переписывания.
Главное не забывайте стартовать новый чат каждые 5-10 сообщений (по ощущениям - чувствуете что подтупливает, просите саммари и идите с ним в соседнее окно).
Ещё хорошо работает вариант просить его дампить инфу в md файлик и потом его же закидывать в контекст нового чата, очень удобно.
Igor Alentyev, блин а я думал тут профиль с клуба подтягивается(
Vibe coding is all fun and games until you have to vibe debug
Забавно - в конце 24го я написал ровно то же самое с aider =)
С бэком и поиском картинок через бинг. А вместо Хампти Дампти вылезал дятел Вуди :D
Забавно, что сам Карпаты только что завайбкодил ровно такое же приложение.
Получается, меню с картинками — это такой
Hello, World!в мире вайбкодинга (: